Some Resources:
Rita.js
RiTa is an open-source software toolkit for computational literature.
"Designed to support the creation of new works of computational literature, the RiTa library provides tools for artists and writers working with natural language in programmable media. The library is designed to be simple while still enabling a range of powerful features, from grammar and Markov-based generation to text-mining, to feature-analysis (part-of-speech, phonemes, stresses, etc). RiTa is implemented in both Java and JavaScript, is free/libre and open-source, and runs in a number of popular programming environments including Android, Processing, Node, and p5.js."
- RiTa.js Reference
- Rhyming dictionary
- Markov chain text generator
- Syllable decomposition
- Analyzing text
- Transformation
Here are some helpful RiTa demos by our TA, Char Stiles:
- A RiTa Rhymer using README files (at Editor.p5)
- A Markov Generator using README files (at Editor.p5)
- A Haiku Generator using README files (at Editor.p5)
Here are some helpful Coding Train videos:
- Shiffman's Introduction to RiTa (20m)
- Shiffman's Context-Free Grammars in RiTa (17m)
ML5.js
"ml5.js aims to make machine learning approachable for a broad audience of artists, creative coders, and students. The library provides access to machine learning algorithms and models in the browser, building on top of TensorFlow.js with no other external dependencies. The library is supported by code examples, tutorials, and sample datasets with an emphasis on ethical computing. "
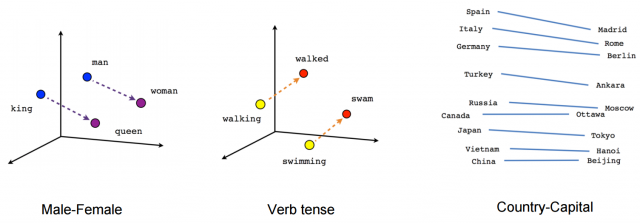
Here is a helpful Coding Train video:
- Shiffman's Word2Vec with ML5.js (11 minutes)
Wordnik API
The Wordnik API "lets you request definitions, example sentences, spelling suggestions, related words like synonyms and antonyms, phrases containing a given word, word autocompletion, random words, words of the day, and much more."
Here's a helpful demo by our TA, Char Stiles:
- Wordnik synonym follower (at Glitch.com)
Here's a helpful Coding Train video:
- Shiffman's Introduction to the Wordnik API (20 minutes)
Text Corpora
Kazemi writes: "This project is a collection of static corpora (plural of "corpus") that are potentially useful in the creation of weird internet stuff. I would like this to help with rapid prototyping of projects. I'm also hoping that this can be used as a teaching tool. My hope is that students can be pointed to this project and they can pick and choose different interesting data sources to meld together for the creation of prototypes."
Example corpora include (among others):
- A list of occupations
- A list of honorifics
- A list of encouraging words
- A list of interjections
- A list of corporations
- Many more....
If you would like industrial-strength corpora (e.g millions of words of transcribed soap operas, etc.), see here.
Project Gutenberg (via Allison Parrish)
- Gutenberg, Dammit -- all of project Gutenberg, well-structured JSON
- Gutenberg Poetry Corpus
N-Grams
An n-gram is a contiguous sequence of n items from a given sample of text or speech. You can view the history of select n-grams using this nice Google viewer.
Professor Mark Davies at Brigham Young University makes N-Gram datasets available for free download (--note: with a simple registration). These words are also tagged with their Parts-of-Speech, using the PoS codes found here.
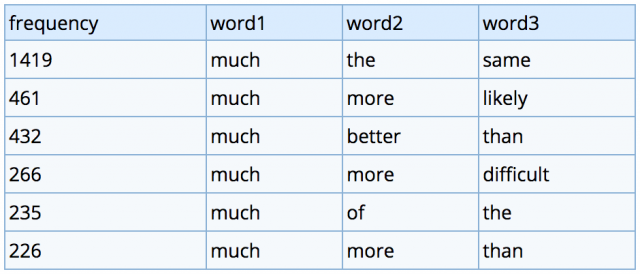
- Set One (complete): the 1,000,000 most frequent 2, 3, 4, and 5-grams, from the 430-million word COCA dataset
- Set Two (demo): the most frequent 2, 3, 4, and 5-word strings from the 14 billion word iWeb corpus
Here's a helpful Coding Train video:
- Shiffman's introduction to Markov Chains and n-grams (8 minutes)