let poseNet, poses = [];
let video, videoIsPlaying;
let left = [], right = [], points = [];
let initialAlpha = 100, FOVheight = 150;
let time;
let show = true, debug = true;
let vidName = 'milkshake';
let rgb = '#513005';
class FOVedge {
constructor(_x1, _y1, _x2, _y2) {
this.x1 = _x1;
this.x2 = _x2;
this.y1 = _y1;
this.y2 = _y2;
}
draw(r, g, b, a){
stroke(r, g, b, a);
line(this.x1, this.y1, this.x2, this.y2);
}
intersects(l2) {
let denom = ((l2.y2 - l2.y1) * (this.x2 - this.x1) - (l2.x2 - l2.x1) * (this.y2 - this.y1));
let ua = ((l2.x2 - l2.x1) * (this.y1 - l2.y1) - (l2.y2 - l2.y1) * (this.x1 - l2.x1)) / denom;
let ub = ((this.x2 - this.x1) * (this.y1 - l2.y1) - (this.y2 - this.y1) * (this.x1 - l2.x1)) / denom;
if (ua < 0 || ua > 1 || ub < 0 || ub > 1) return false;
let x = this.x1 + ua * (this.x2 - this.x1);
let y = this.y1 + ua * (this.y2 - this.y1);
return {x, y};
}
}
class FOV {
constructor(x1, y1, x2, y2) {
this.s1 = new FOVedge(x1, y1, x2, y2 - FOVheight);
this.s2 = new FOVedge(x1, y1, x2, y2 + FOVheight);
this.s3 = new FOVedge(x2, y2 + FOVheight, x2, y2 - FOVheight);
this.col = color(191, 191, 191, initialAlpha);
this.show = true;
// right = 1, left = -1
if (x2 > x1) {
this.direction = 1;
} else {
this.direction = -1
}
}
checkForIntersections(fov) {
let intersections = [];
for (let j = 1; j < 3; j++){
let sattr = 's' + j.toString();
for (let i = 1; i < 3; i++) {
let attr = 's' + i.toString();
let ints = this[sattr].intersects(fov[attr]);
if (ints != false) {
intersections.push(ints);
}
}
}
if (intersections.length == 2){
intersections.push({x: this.s1.x1, y: this.s1.y1});
}
return intersections;
}
fade(){
this.col.levels[3] = this.col.levels[3] - 3;
if (this.col.levels[3] < 0) {
this.show = false;
}
}
draw() {
this.s1.draw(this.col.levels[0], this.col.levels[1], this.col.levels[2], this.col.levels[3]);
this.s2.draw(this.col.levels[0], this.col.levels[1], this.col.levels[2], this.col.levels[3]);
this.s3.draw(this.col.levels[0], this.col.levels[1], this.col.levels[2], this.col.levels[3]);
}
}
function setup() {
videoIsPlaying = false;
createCanvas(1280, 720, P2D);
//createCanvas(1920, 1080);
video = createVideo( vidName + '.mp4', vidLoad);
video.size(width, height);
poseNet = ml5.poseNet(video, modelReady);
poseNet.on('pose', function(results) {
poses = results;
});
video.hide();
}
function modelReady() {
select('#status').html('Model Loaded');
}
function mousePressed(){
vidLoad();
}
function draw() {
if (show) {
image(video, 0, 0, width, height);
} else {
background(214, 214, 214);
}
drawKeypoints();
}
function drawKeypoints() {
for (let i = 0; i < poses.length; i++) {
let pose = poses[i].pose;
for (let j = 0; j < 5; j++) { let keypoint = pose.keypoints[j]; if ((j == 3 || j == 4) && keypoint.score > 0.7) { // left or right ear
// calclulate average x between nose and eye
let earX = 0, earY = 0;
if (pose.keypoints[2].score > 0.7){
earX = pose.keypoints[2].position.x;
earY = pose.keypoints[2].position.y;
} else {
earX = pose.keypoints[1].position.x;
earY = pose.keypoints[1].position.y;
}
let x1 = keypoint.position.x
let y1 = keypoint.position.y
let x2 = earX;
let y2 = earY;
//let x2 = (earX + pose.keypoints[0].position.x) / 2;
//let y2 = (earY + pose.keypoints[0].position.y) / 2;
let length = Math.sqrt(Math.pow(x1 - x2, 2) + pow(y1 - y2 , 2));
let newX = x2 + (x2 - x1) / length * 1200;
let newY = y2 + (y2 - y1) / length * 1200;
let look = new FOV(x2, y2, newX, newY);
if (look.direction == -1) {
let lastR = right.pop();
if (lastR != undefined){
let ints = look.checkForIntersections(lastR)
if (ints.length >= 3 && show) {
points.push(ints);
}
right.push(lastR);
}
left.push(look)
} else {
let lastL = left.pop();
if (lastL != undefined) {
let ints = look.checkForIntersections(lastL)
if (ints.length >= 3 && show) {
points.push(ints);
}
left.push(lastL);
}
look.col = color(56, 56, 56, initialAlpha);
right.push(look)
}
}
let col = color(rgb);
col.levels[3] = 2;
fill(col.levels[0], col.levels[1], col.levels[2], col.levels[3]);
noStroke();
if (!debug){
for (let i = 0; i < points.length; i++) {
beginShape();
for (let j = 0; j < points[i].length; j++) {
vertex(points[i][j].x, points[i][j].y);
}
endShape(CLOSE)
}
}
for (let i = 0; i < left.length; i++) {
if (debug){left[i].draw();}
left[i].fade();
if (!left[i].show) {
left.splice(i, 1);
}
}
for (let i = 0; i < right.length; i++) {
if (debug){right[i].draw();}
right[i].fade();
if (!right[i].show) {
right.splice(i, 1);
}
}
}
}
}
function vidLoad() {
time = video.duration();
video.stop();
video.loop();
videoIsPlaying = true;
if (!debug) {
setTimeout(function(){
show = false;
video.volume(0);
video.hide();
}, time * 1000);
}
}
function keyPressed(){
if (videoIsPlaying) {
video.pause();
videoIsPlaying = false;
} else {
video.loop();
videoIsPlaying = true;
}
} |


















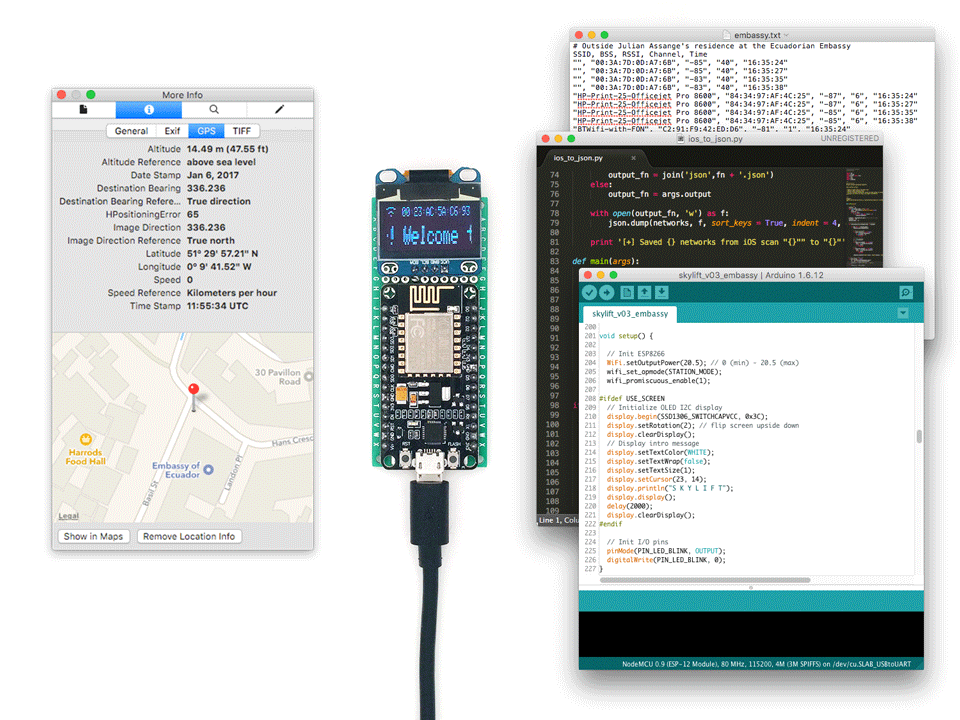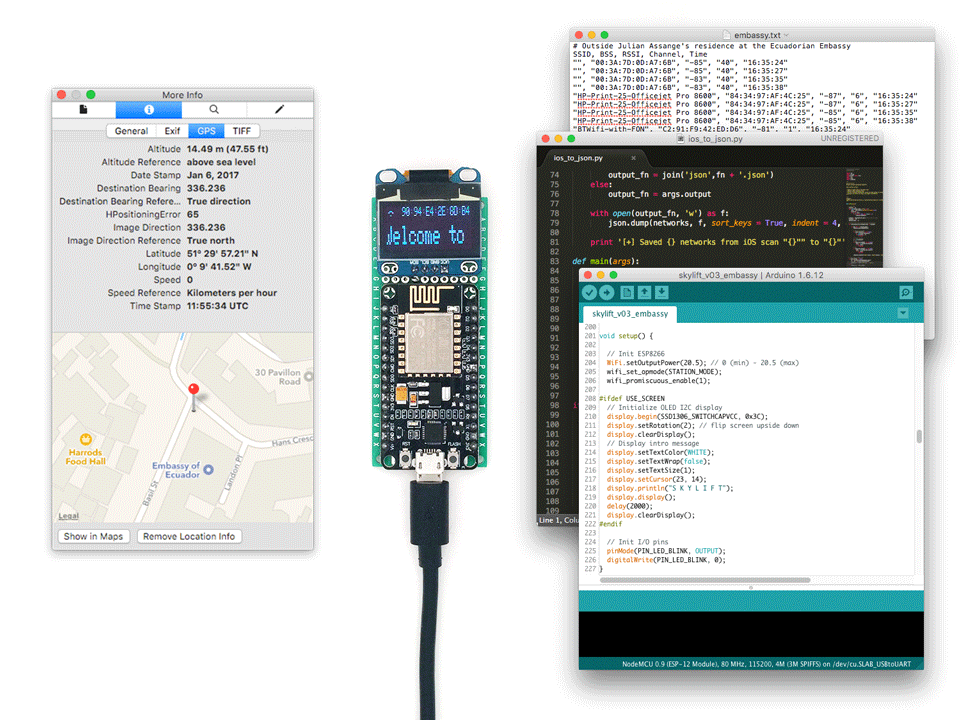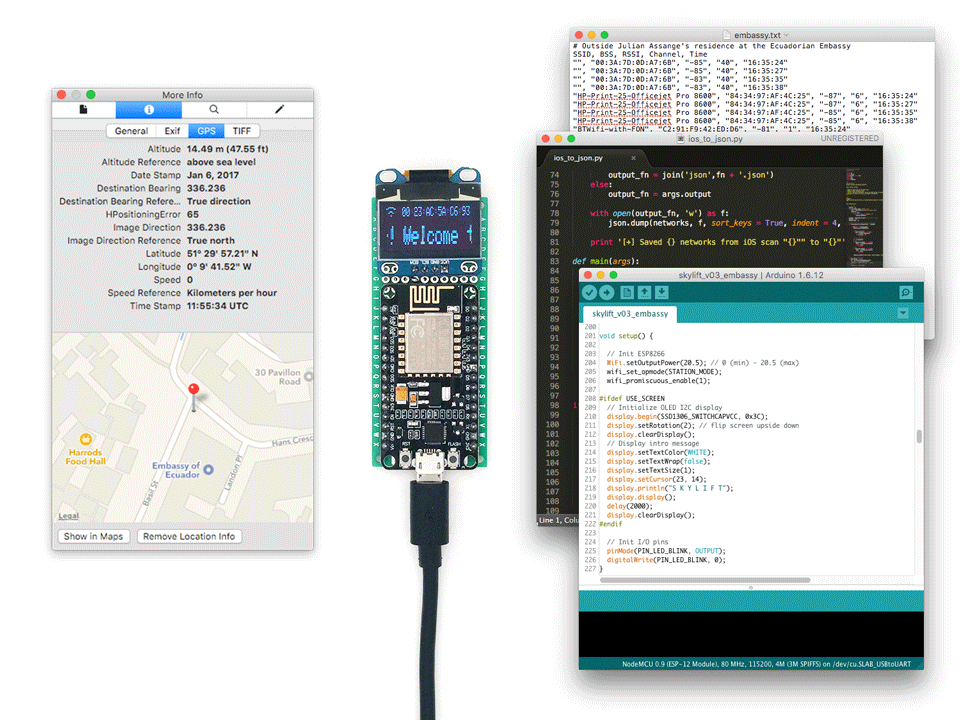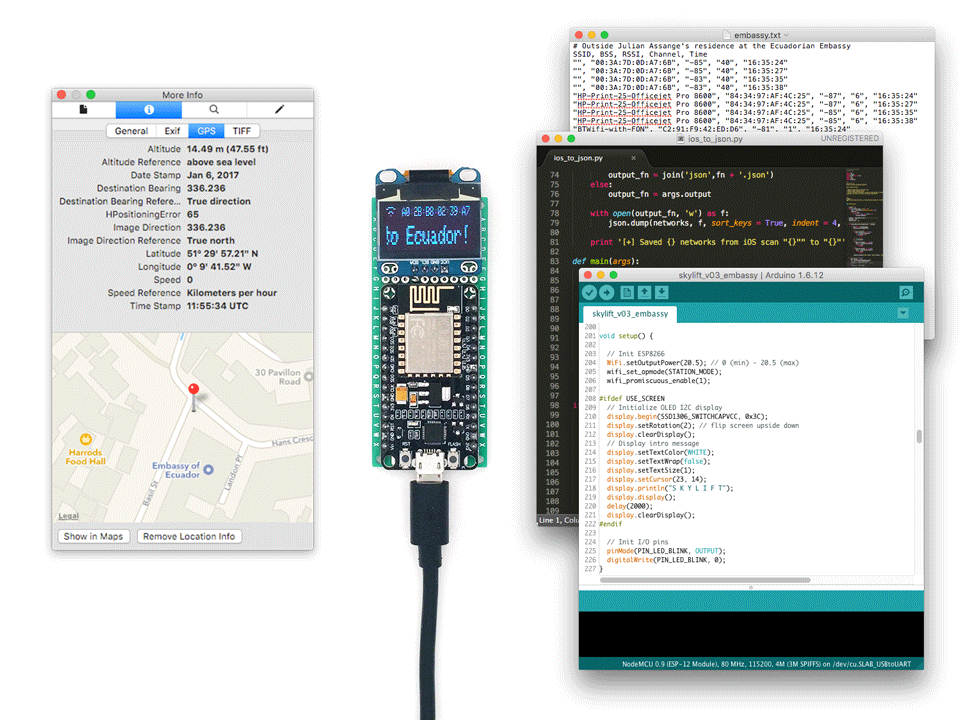



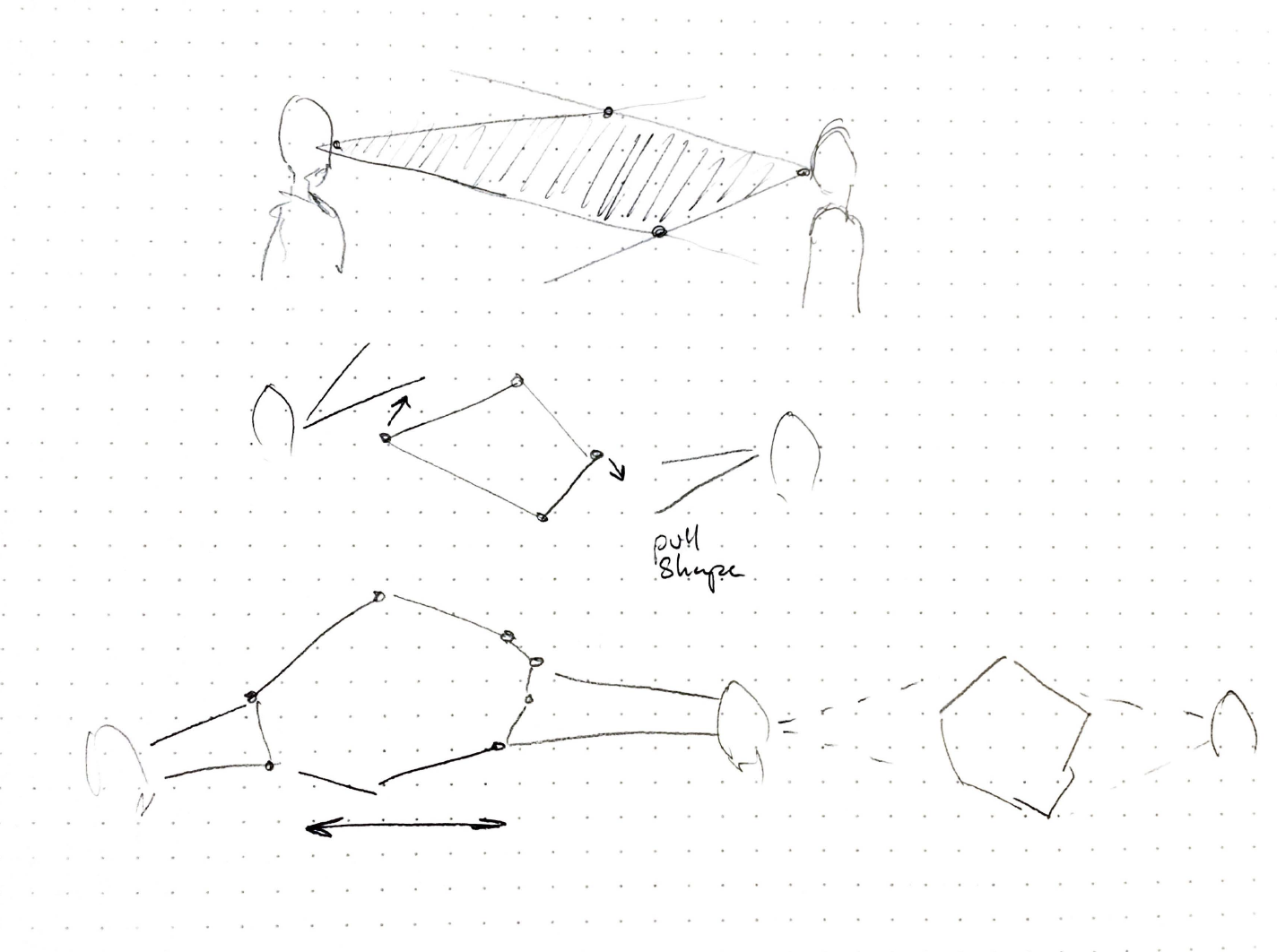 The code can be found on
The code can be found on 
