I find the idea of coding as exploration very compelling in her talk. Not only applied to poetry or generative text, but as it applies to creative coding in general. Thinking of it as an exploration opens up the world of "happy accidents" where if you are exploration, you might not completely know what it is you're looking for, and I find that exciting. I love her discussion about the creation of "nonsense", and that "what you thought was nonsense was actually sensical all along, you just had to learn how to look at it right." Robots being reporters is also a funny idea - that you are asking a bot or robot to go find things out for you.
Category: 07
shuann-book
URL to ZIP: https://drive.google.com/file/d/1RQSg3IoQqV_9MWc9p3Vng2feqgH-IsUT/view?usp=sharing
Title: A Guide to Absurd Movies
One sentence description: Explore absolutely absurd movies with this chapter. Yet remember the biggest challenge is where to find them.
I first had the idea of making a recipe book for creating new movies. For the ingredients, I would just throw in some random director, actors, writers ect., and then you will generate a random plot to go along with it. However, as I discovered some resources online containing real user reviews I wanted to include that as well. Thus, eventually, my chapter become something like a review book on non-existing movies: it is the interplay between the fake and the real that I am personally very interested in.
The entire project is generated based on Markov chains because I have to have completely bazar plot lines which the computer think marks as possible with little intervention as possible (i.e. predefined grammar). However, also due to this technique that I am using, I had to spend hours and hours cleaning up the data that I was feeding into the program. For example, I had to change all the names of the male protagonists to Chris and those of the female protagonists to Jade just so that names that only appear in one movie would not break the Markov chain. I also had to do a lot of filtering so that the plot content is not too over the place that two generated sentences adjacent to each other make no sense.
you can see that here, too many names and proper nouns are breaking the reading experience.

A lot better with cleaned up data, though more needed to be done.
Also, to make sure the first sentence makes sense, I need to incorporate many validators so that, for example, the sentence will always contain a determiner, does not start with a conjunction, etc. Moreover, I also tried to make sure that the pronoun matches the sex of the person that was named. Ex. "him" is changed into "her" because the determiner is identified as female in the first sentence.
Screenshots of the book pages: 

var metaData; var plot; var posReview, negReview; var titleTracker = 1; var dirList = []; var writerList = []; var actorList = []; var plotList = []; var linesPlot = []; var linesReview = []; var markovPlot, x = 160, y = 240; var markovPosReview, markovNegReview, x1 = 160, y1 = 200; var bannedBeginner = ["He", "His", "Her", "She", "They", "Their", "We", "Another", "Suddenly", "However", "The next"]; var bannedMid = ["then", "as well", "also", "not only"]; var male = ["he", "Chris", "Chris's", "him", "male", "man", "his", "gentlemen", "boy", "himself"]; var female = ["she", "Jade", "Jade's", "her", "female", "woman", "her", "lady", "girl", "herself"]; var finalReivew = []; var curDir = []; var curActor = []; var curWriter = []; var movies = []; function preload(){ metaData = loadJSON("movieDetails.json"); plot = loadStrings('illusion.txt'); posReview = loadStrings('posReview.txt'); negReview = loadStrings('negReview.txt'); } function setup() { createCanvas(600, 600); textFont('times', 16); textAlign(LEFT); // create a markov model w' n=4 markovTitle = new RiMarkov(2); markovPlot = new RiMarkov(3); markovPosReview = new RiMarkov(4); markovNegReview = new RiMarkov(4); // load text into the model markovTitle.loadText(plot.join(' ')); markovPlot.loadText(plot.join(' ')); markovPosReview.loadText(posReview.join(' ')); markovNegReview.loadText(negReview.join(' ')); extractInfo(); for (var i = 0; i < 15; i++){ generate(i); } // Create a JSON Object, fill it with the Poems. var myJsonObject = {}; myJsonObject.movies = movies; // console.log(myJsonObject); // Make a button. When you press it, it will save the JSON. createButton('SAVE POEMS BUTTON') .position(10, 10) .mousePressed(function() { saveJSON(myJsonObject, 'myPoems.json'); }); } function combineText(index) { var finalPlot = linesPlot.join(' '); for (var i = 0; i < linesReview.length; i++){ finalReivew[i] = linesReview[i].join(' '); } var title = "Absurd Moive No." + titleTracker; titleTracker += 1; movies[index] = new moiveInfo(title, curDir, curActor, curWriter, finalPlot, finalReivew); console.log(movies[index]); } function generate(index) { randBasicInfo(); linesPlot = markovPlot.generateSentences(2); checkPlot(); checkAgreement(); for (var i = 0; i < 3; i++){ if (random() < 0.7){ linesReview[i] = markovNegReview.generateSentences(random([3, 4])); } else { linesReview[i] = markovPosReview.generateSentences(random([2, 3, 4])); } } combineText(index); } //generate basic movie setp info function randBasicInfo(){ curDir = []; curActor = []; curWriter = []; var dirNum = 1; var actNum = random([3, 4, 4]); var wriNum = random([1, 2, 2]); for (var a = 0; a < dirNum; a++){ curDir[a] = random(dirList); } for (var b = 0; b < actNum; b++){ curActor[b] = random(actorList); } for (var c = 0; c < wriNum; c++){ curWriter[c] = random(writerList); } } function checkPlot() { //get all words in the frist sentence var sentence1 = linesPlot[0].split(' '); //replace first sentence when it begins with pronoun if (checker(sentence1[0], bannedBeginner) || checkConjunction(sentence1[0])){ linesPlot[0] = markovPlot.generateSentence(); checkPlot(); } else { //look at each word in the sentence for (var i = 0; i < sentence1.length; i++){ sentence1[i] = RiTa.trimPunctuation(sentence1[i]); } // console.log(sentence1); // console.log("here"); // if (checker(sentence1, bannedMid) && checker(sentence1, charNames) === false){ // console.log(linesPlot[0]); // linesPlot[0] = markovPlot.generateSentence(); // console.log(linesPlot[0]); // } if (checker(sentence1, bannedMid)){ linesPlot[0] = markovPlot.generateSentence(); checkPlot(); } if (checkDeterminer(sentence1) === false){ linesPlot[0] = markovPlot.generateSentence(); checkPlot(); } } } // https://stackoverflow.com/questions/37428338/check-if-a-string-contains-any-element-of-an-array-in-javascript function checker(value, ban) { for (var i = 0; i < ban.length; i++) { if (value.indexOf(ban[i]) > -1) { return true; } } return false; } function checkDeterminer(value){ for (var a = 0; a < value.length; a++){ if (RiTa.getPosTags(value[a]) == "dt"){ return true; } } return false; } function checkConjunction(value){ var tag = RiTa.getPosTags(value); for (var i = 0; i < tag.length; i++){ if (tag[i] === "in" || tag[i] === "cc"){ return true; } } return false; } function checkAgreement() { var sex = null; // sentence1Agg(); // sentence2Agg(); var sentence1 = linesPlot[0].split(' '); var sentence2 = linesPlot[1].split(' '); for (var i = 0; i < sentence1.length; i++){ sentence1[i] = RiTa.trimPunctuation(sentence1[i]); if (sex === null){ if (male.indexOf(sentence1[i]) > -1){ sex = "M"; } if (female.indexOf(sentence1[i]) > -1){ sex = "F"; } } } for (var a = 0; a < sentence1.length; a++){ if (RiTa.getPosTags(sentence1[a]) == "prp"){ if (male.indexOf(sentence1[a]) > -1 && sex === "F"){ var index = male.indexOf(sentence1[a]); sentence1[a] = female[index]; } if (female.indexOf(sentence1[a]) > -1 && sex === "M"){ var index = male.indexOf(sentence1[a]); sentence1[a] = male[index]; } } } linesPlot[0] = sentence1.join(' ') + "."; } function moiveInfo(title, dir, actor, writer, plot, reviews){ this.title = title; this.direc = dir; this.actor = actor; this.writer = writer; this.plot = plot; this.reviews = reviews; } function extractInfo(){ console.log(metaData.results.length); for (var i = 0; i < metaData.results.length; i++){ if (metaData.results[i].imdb.rating >= 8){ //extract the names of directors on file for all movies with imdb rating > 8 if (metaData.results[i].director != null){ if (metaData.results[i].director.length > 1){ var dirArray = metaData.results[i].director.split(', '); for (var a = 0; a < dirArray.length; a++){ append(dirList, dirArray[a]); } } else { var dirArray = metaData.results[i].director; append(dirList, dirArray); } } if (metaData.results[i].writers != null){ if (metaData.results[i].writers.length >= 1){ for (var b = 0; b < metaData.results[i].writers.length; b++){ append(writerList, metaData.results[i].writers[b]); } } } if (metaData.results[i].actors != null){ if (metaData.results[i].actors.length >= 1){ for (var c = 0; c < metaData.results[i].actors.length; c++){ append(actorList, metaData.results[i].actors[c]); } } } } } } |
Sources:
review.json from: https://github.com/Edmond-Wu/Movie-Reviews-Sentiments
Plot summary dataset from: http://www.cs.cmu.edu/~ark/personas/
Example movie dataset from: https://docs.mongodb.com/charts/master/tutorial/movie-details/prereqs-and-import-data/
chewie-book
High Stakes - A real account of what's happening in poker.
archive


When I was 6, every morning while I was eating cereal I would have a big Calvin and Hobbes book open in front of me. I never read it out of a newspaper, having to wait a whole day before the next little morsel, but we had these collection books full of strips that I could blow through like binge watching Netflix. There's no doubt a running narrative between the strips (some even continuing the same event) but each also exists as its own distinct story, like a joke in a comedy routine. This is why in researching and developing ideas for this project I was excited to find an online database containing plot descriptions of every published Calvin and Hobbes comic strip.
Thinking about the different uses of these texts, I was wondering what Calvin and Hobbes was at its lowest level and the types of events that transpired in the strip. Calvin is relentlessly true to himself and his beliefs despite the pressure he faces from his peers and superiors to act "normal": social rejection, being grounded, and getting scolded by his teachers to name a few. There's something admirable about the willingness to believe in yourself to that extent, but it also causes a great deal of inefficiency when you refuse to think based on observation or even speculation and only perpetuating and expanding on your existing ideas.
This is almost the complete opposite of some thoughts I've had about poker.
In this relentless game you are restricted to a finite set of actions, and (at least at the professional level) if you aren't able to make the most efficient set of actions based on the changing state of the game and the mechanisms of probability, you lose with no second chance. Because these two worlds are so contradictory I thought it would be interesting and amusing to combine references to both in these short, narrative descriptions.
I decided to use the texts by replacing the main characters with popular poker players, and replacing some of the Calvin and Hobbes language with poker terms. These terms were collected from an article describing all of the rules for playing no-limit Texas hold 'em. The results were interesting and at times amusing, although they definitely weren't completely coherent.
For the background images, my program went through each text, added each instance of a players name to a list and then used those frequency indices to select which player to show a picture of in the background. The front and back cover pages are illustrations from one of the gorgeous full-color strips released on Sundays.

Code in Java for ripping summaries of every Calvin and Hobbes comic to a .txt file.
PrintWriter output; void setup() { output = createWriter("positions.txt"); String t; int max = 3150; output.println("{"); for (int i=1; i<max+1; i++) { println(i); t = getJist(i); t = t.replace("\"","'"); output.print("\""+str(i)+"\" : \""); output.print(t); output.print("\""); if (i<max) output.print(","); output.println(""); } output.println("}"); output.close(); } String getJist(int n) { if ((n<1)||(n>3150)) return "invalid index"; else { String[]t; t = loadStrings("http://www.reemst.com/calvin_and_hobbes/stripsearch?q=butt&search=normal&start=0&details="+str(n)); String line = t[56]; t = line.split(" "); line = t[1]; return line; } } |
Code in Javascript for modifying the texts and outputting to .json:
var t,p,corp, rm; var availPos = ["nns","nn","jj"];//,"vbg","vbn","vb","vbz","vbp"]; var corp2 = { "nns": [], "nn": [], "jj": [], "vbg": [], "vbn": [], "vb": [], "vbz": [], "vbp": [], "rb": [] } var nns = []; var nn = []; var jj = []; var vbg = []; var vbn = []; var vb = []; var vbz = []; var vbp = []; var rb = []; var reps = [ ["Calvin","Negreanu"], ["Hobbes","Dwan"], ["Mom","Selbst"], ["Dad","Ivey"], ["Susie", "Tilly"], ["Christmas", "WSOP"], ["parent", "sponsor"], ["Parent", "Sponsor"], ["Tiger", "Dealer"], ["tiger", "dealer"], ]; function preload() { t = loadJSON("jists.json"); p = loadStrings("poker.txt"); } function setup() { createCanvas(400, 400); //print("okay"); loadToks(); var texts = []; var fake; for (var i=0; i<3000; i++) { ttt = doer(int(random(3150))); fake = new RiString(ttt); fake.replaceAll("\"", ""); fake.replaceAll(" ,", ","); ttt = fake._text; texts.push(ttt); } var ret = {"a":texts}; saveJSON(ret,"all.json"); //print(availPos); } function draw() { background(220); } function doer(n) { var j = RiString(t[n]); for (var i in reps) { j.replaceAll(reps[i][0], reps[i][1]); } //print(j); return advRep(j._text); } function loadToks() { var movie = join(p," "); rm = new RiMarkov(3); var toks = movie.split(" "); var om,rs; var tooks = []; for (var i in toks) { if (toks[i].length>3) { om = split(split(split(toks[i],".")[0],",")[0],"?")[0]; //if (RiTa.isNoun(om)&& !(RiTa.isAdjective(om))) { rs = new RiString(om); rs = rs.replaceAll("(",""); rs = rs.replaceAll(")",""); rs = rs.replaceAll(":",""); rs = rs.toLowerCase(); rs = rs.trim(); var ppp = RiTa.getPosTags(rs._text)[0]; if (availPos.indexOf(ppp)!=-1 ) { tooks.push(rs._text); corp2[ppp].push(rs._text); } } //print(toks[i]); } //print(corp2) //saveJSON(corp2,"corp2.json"); rm.loadTokens(tooks); } function advRep(s) { var poss = RiTa.getPosTags(s); var toks = RiTa.tokenize(s); var stringy = ""; var randInt; for (var i in toks) { if (availPos.indexOf(poss[i])!=-1 && int(random(3))==0) { randInt = int(random(corp2[poss[i]].length)) if (!(RiTa.isVerb(toks[i])) || poss[i]=="vbg") { for (var j in poss) { if (toks[j] == toks[i]) toks[j] = corp2[poss[i]][randInt]; } } else { for (var j in poss) { if (toks[j] == toks[i]) toks[j] = corp2[poss[i]][randInt]; } } } } var stringgg = new RiString(join(toks, " ")); stringgg.replaceAll(" .", "."); return str(stringgg._text); } |
Basil.js code:
#include "../../bundle/basil.js"; // Version for basil.js v.1.1.0 // Load a data file containing your book's content. This is expected // to be located in the "data" folder adjacent to your .indd and .jsx. // In this example (an alphabet book), our data file looks like: // [ // { // "title": "A", // "image": "a.jpg", // "caption": "Ant" // } // ] var jsonString; var jsonData; var text = ["*here is where I included the quotes*"]; ]; //-------------------------------------------------------- function setup() { var randSeed = 2892; while (b.pageCount()>=2) b.removePage(); // Load the jsonString. jsonString = b.loadString("lines.json"); // Clear the document at the very start. b.clear (b.doc()); var imageX = 72*1.5; var imageY = 72; var imageW = 72*4.5; var imageH = 72*4.5; var anImageFilename = "images/front.jpg"; var anImage = b.image(anImageFilename, 35, 35, 432-35*2, 648-35*2); anImage.fit(FitOptions.FILL_PROPORTIONALLY); // Make a title page. b.fill(244, 215, 66); b.textSize(48); b.textFont("Calvin and Hobbes","Normal"); b.textAlign(Justification.LEFT_ALIGN); b.text("CHEWIE", 60,540,360,100); // Parse the JSON file into the jsonData array jsonData = b.JSON.decode( jsonString ); b.println(jsonData); // Initialize some variables for element placement positions. // Remember that the units are "points", 72 points = 1 inch. var titleX = 195; var titleY = 0; var titleW = 200; var titleH = 600; var captionX = 72; var captionY = b.height - 108; var captionW = b.width-144; var captionH = 36; var txt, tok, max; var just; var names = ["n"]; // Loop over every element of the book content array // (Here assumed to be separate pages) for (var i = 0; i < 9; i++) { // Create the next page. b.addPage(); txt = text[randSeed+i]; tok = b.splitTokens(txt," "); for (var j=tok.length; j>=0; j--) { if (tok[j] === "Dwan"){ names.push("d"); } if (tok[j] === "Hellmuth") { names.push("h"); } if (tok[j] === "Selbst") { names.push("s"); } if (tok[j] === "Tilly") { names.push("t"); } if (tok[j] === "Negreanu") { names.push("n"); } } var ic = b.floor(b.random(0,names.length)); ic = names[ic]; names = []; if (ic == "d") max=6; if (ic == "h") max=7; if (ic == "i") max=11; if (ic == "n") max=9; if (ic == "s") max=6; if (ic == "t") max=3; anImageFilename = "images/"+ic + (i%max+1)+".jpg"; // Load an image from the "images" folder inside the data folder; // Display the image in a large frame, resize it as necessary. // no border around image, please anImage = b.image(anImageFilename, 0, 0, 432, 648); anImage.fit(FitOptions.FILL_PROPORTIONALLY); b.opacity(anImage,70); if (i%2==0) { titleX = 50; just = Justification.LEFT_ALIGN; } else { titleX = 190; just = Justification.RIGHT_ALIGN; } b.textSize(16); b.fill(0); b.textFont("DIN Alternate","Bold"); b.textAlign(just, VerticalJustification.BOTTOM_ALIGN ); var ttp = b.text(txt, titleX,titleY,titleW,titleH); // Create textframes for the "caption" fields b.fill(0); b.textSize(36); b.textFont("Helvetica","Regular"); b.textAlign(Justification.LEFT_ALIGN, VerticalJustification.TOP_ALIGN ); //b.text(jsonData."first"[0].caption, captionX,captionY,captionW,captionH); }; b.addPage(); imageX = 72*1.5; imageY = 72; imageW = 72*4.5; imageH = 72*4.5; anImageFilename = "images/back.jpg"; anImage = b.image(anImageFilename, 35, 35, 432-35*2, 648-35*2); anImage.fit(FitOptions.FILL_PROPORTIONALLY); } // This makes it all happen: b.go(); |
paukparl-book

Generated Self-Help Books
These are generated book covers (front and back) of self-help books, each with a different instruction on how to live your life.
Process
Lately I've been consumed by an unhealthy obsession with how to lead my life and how to start my career. Since we were making a book, I wanted it to make be about me. I hoped to resolve some of my issues through introspection.
During the process, I was somehow reminded of the sheer number of self-help books out there that instruct you on how to live your life. When you see too many of them sometimes, you are made to think that it is that important to live your life to your fullest, when it just as well might not be that important. My book was an attempt to emulate, and thereby mock, these self-help books
I based most of my word selections on Text Corpora and used minimal code from RiTa.js library. For example, the title was drawn from corpora/data/words/common.json directory with a few filters such as (!RiTa.isNoun()). I also made a few template strings for subtitles, and a few arrays of words related to success. I think I could have hidden the repeating pattern and made more clever and controlled title-subtitle matches by using the Wordnik API. But there are still some examples that show the script is doing its job.
google drive link to 25 instances
Code
Some snippets of code showing functions for title and subtitle generation, and where I got the data.
adv = ['conveniently', 'quickly', 'certainly', 'effortlessly', 'immediately', 'completely'] adj = ['convenient', 'undisputed', 'quick', 'secret', 'true', 'groundbreaking', 'revolutionary'] obj = ['success', 'a successful career', 'true happiness', 'a new life', 'a healthier lifestyle'] v = ['succeed', 'win', 'challenge yourself', 'be successful', 'achieve success', 'get ahead in life', 'be famous', 'be happy', 'lose weight', 'make your dreams come true', 'plan ahead', 'make more friends'] function preload() { firstNames = loadJSON('/corpora-master/data/humans/firstNames.json'); lastNames = loadJSON('/corpora-master/data/humans/authors.json'); common = loadJSON('/corpora-master/data/words/common.json'); adverbs = loadJSON('/corpora-master/data/words/adverbs.json'); adjectives = loadJSON('/corpora-master/data/words/encouraging_words.json'); newspapers = loadJSON('/corpora-master/data/corporations/newspapers.json'); } ... ... ... function genTitle() { var temp = common[floor(random(common.length))]; if (RiTa.isNoun(temp) || RiTa.isAdjective(temp) || RiTa.isAdverb(temp) || !RiTa.isVerb(temp) || temp.length >7) return genTitle(); else return temp; } function randomDraw(array) { return array[floor(random(array.length))]; } function genSubtitle() { temp = random(10); str; if (temp<2.3) str = 'How to ' + randomDraw(adv) + ' ' + randomDraw(v) + ' and ' + randomDraw(v); else if (temp<4.6) str = 'A ' + floor(random(12)+3) + '-step guide to ' + randomDraw(obj); else if (temp<6.6) str = floor(random(9)+3) + ' ways to ' + randomDraw(adv) + ' ' + randomDraw(v); else if (temp<8.6) str = 'A ' + randomDraw(adj) + ' guide on how to ' + randomDraw(v); else str = 'If only I had known then these ' + floor(random(12)+3) + ' facts of life'; return str; } function genAuthor() { gen = {}; gen['books'] = []; gen['author'] = firstNames[floor(random(firstNames.length))] + ' ' + lastNames[floor(random(lastNames.length))]; for (let i=0; i<8; i++) { book = {}; book['title'] = genTitle(); book['subtitle'] = genSubtitle(); book['quotes'] = []; book['reviews'] = []; for (let j=0; j<5; j++) { review = {} temp = random(4); var reviewString; if (temp<1.2) reviewString = adverbs[floor(random(adjectives.length))] + ' ' + adjectives[floor(random(adjectives.length))] + ' and ' + adjectives[floor(random(adjectives.length))] +'.'; else if (temp<2.0) reviewString = adverbs[floor(random(adjectives.length))] + ' ' + adjectives[floor(random(adjectives.length))] + ' but ' + adjectives[floor(random(adjectives.length))] +'.'; else if (temp<2.8) reviewString = adverbs[floor(random(adjectives.length))] + ' ' + adjectives[floor(random(adjectives.length))] +'!'; else if (temp<3.5) reviewString = adverbs[floor(random(adjectives.length))] + ' ' + adjectives[floor(random(adjectives.length))] +'.'; else reviewString = adjectives[floor(random(adjectives.length))] + '...' review['text'] = uppercase(reviewString); review['by'] = newspapers[floor(random(8, newspapers.length))]; book['reviews'].push(review); } book['price'] = '$' + floor(random(7, 11)) + '.50' // 6 <> 10 gen['books'].push(book); } saveJSON(gen, 'book'+ n +'.json'); } |
airsun-book
Link of the zip file:https://drive.google.com/file/d/1vK9PlB3Dhnp6-Pvgipe16i5Mij0k40fH/view?usp=sharing
Link of the sample chapter: https://drive.google.com/file/d/1wINmM0CPXhITyv4fDxDD3slvJv1umwXm/view?usp=sharing
Title: Value of Advertisements
Short Description: In today's industry, advertising is actually much less effective than people have historically thought. This work, by using the AFINN ranking of words, challenges the traditional value of advertisement and its effect in building product's quality image.
Long Description: In today's industry, advertising is actually much less effective than people have historically thought. A research paper "The effect of advertising on brand awareness and perceived quality: An empirical investigation using panel data" done by C.R. Clark, Ulrich Doraszelski (University of Pennsylvania), and Michaela Draganska, establishes the finding that advertising has "no significant effect on perceived quality" of a brand. The use of advertisement does build a significant positive effect on brand awareness, but details in the advertisement do not change people's quality perception. Therefore, looking at the most recent products by Apple, an experiment of changing the advertisements from its official website with different descriptive words (all positive, but differs in the levels of positivity) is conducted. Through the process, I am wondering about the differences between the randomly generated results and the original transcript. From the generated advertisement, will people really pay attention to new descriptive words? If so, to what extent? If not, then I am curious about whether computing generated word will be able to replace the traditional advertisement.
To discover this effect, I first copied down and cleaned the set of advertisements from Apple's official websites. Then, I categorized the list of AFINN ranking of words by the level of positivity and part of speech (noun/verb/adj/adv). After that, I replaced descriptive words from the original ads with the AFINN ranking word with the proper capitalization and punctuation to make things "make sense". An example of advertisements for iPhone Xs:

Here is an example of the advertisement for the AirPods:
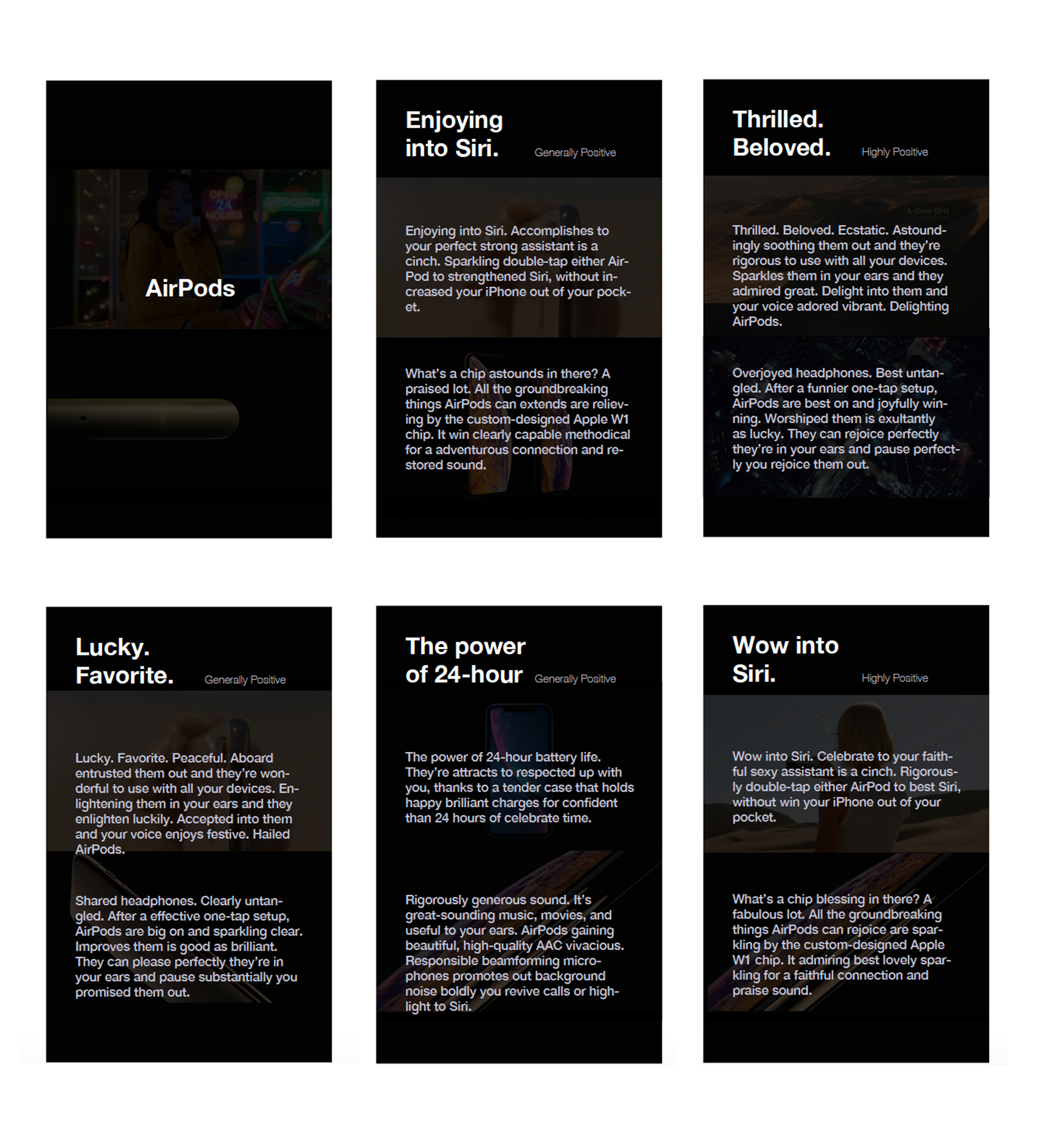
Moreover, to make the advertisement resembles Apple's actual advertisement, I studied typography, the choice of images, layout and color scheme of their official website. From one of their advertisement videos, I got photos that represent the product and randomly assigned them to each advertisement.
Here are some inspirational layout and photos used for designing the final pages:



Embedded Code:
var rhymes, word, data; var afinn; function preload() { afinn = loadJSON('afinn111.json'); script = loadJSON('description.json'); } var detect_words = []; var detect_values = []; var currentlevel; //for general category var pos_verbs = []; var neg_verbs = []; var pos_adj = []; var neg_adj = []; var pos_adv = []; var neg_adv = []; //for high category var pos_adj_high = []; var pos_adv_high = []; var pos_verbs_high = []; //for low category var pos_adj_low = []; var pos_adv_low = []; var pos_verbs_low = []; var original_ary1 = []; var original_ary2 = []; var original_ad; var original_ad_ary; var output = []; var output1 = []; var output2 = []; var currentT1 = []; var currentT2 = []; var currentT3 = []; var currentT4 = []; var currentT5 = []; var currentT6 = []; var currentT7 = []; var currentT8 = []; var currentT9 = []; var phonecontent; var imagecontent; // var page = {phone: phonecontent, image: imagecontent} // var page2 = {phone: phonecontent, image: imagecontent} // var page3 = {phone: phonecontent, image: imagecontent} var final_array = []; //creating the larger 2d array var pagearray1 = []; var pagearray2 = []; function setup(){ createCanvas(800, 1000); fill(255); textFont("Georgia"); var txt = afinn; var currentWord; detect_words = Object.getOwnPropertyNames(txt); detect_values = Object.values(txt); //AirPods //IphoneXs original_ary1 = script.IphoneXs; //print(original_ary1) produceP(original_ary1, pagearray1); //original_ary2 = script.AirPods; //produceP(original_ary2, pagearray2); print("array1", pagearray1) //print("array2", pagearray2) } function produceP(original_ary, pagearray){ //print(original_ary) //this for loop is used to get the positive and negative verbs for the advertisement for (var i = 0; i < detect_values.length; i ++){ currentWord = detect_words [i].replace(/\s+/g, ''); if (detect_values[i] > 0){ if (RiTa.isVerb(currentWord)) { pos_verbs.push(currentWord) } if (RiTa.isAdjective(currentWord)){ pos_adj.push(currentWord) } if (RiTa.isAdverb(currentWord)){ pos_adv.push(currentWord) } } if (detect_values[i] <= 5 && detect_values[i] >= 3){ if (RiTa.isVerb(currentWord)) { pos_verbs_high.push(currentWord) } if (RiTa.isAdjective(currentWord)){ pos_adj_high.push(currentWord) } if (RiTa.isAdverb(currentWord)){ pos_adv_high.push(currentWord) } } if (detect_values[i] < 3 && detect_values[i] >= 0){ if (RiTa.isVerb(currentWord)) { pos_verbs_low.push(currentWord) } if (RiTa.isAdjective(currentWord)){ pos_adj_low.push(currentWord) } if (RiTa.isAdverb(currentWord)){ pos_adv_low.push(currentWord) } } } // print("verbs", pos_verbs_5) // print("adj", pos_adj_5) // print("adv",pos_adv_5) ////////////////generating positivity words in general//////////// for (var t = 0; t < original_ary.length; t++){ var newstring =new RiString (original_ary[t]) var posset = newstring.pos() var wordset = newstring.words() var original_ad_ary = original_ary[t].match(/\w+|\s+|[^\s\w]+/g) var current_content = ""; for (var j = 0; j < posset.length; j++){ // if the word is a verb if (/vb.*/.test(posset[j])){ // if the word is not is/are/be if (wordset[j] != "is" && wordset[j] != "are" && wordset[j] != "be"){ //running for all positive word var newverb = round(random(0, pos_verbs.length-1)); var track; if (j>=2){ if (wordset[j-1] == "." ){ track = pos_verbs[str(newverb)][0].toUpperCase()+pos_verbs[str(newverb)].slice(1); }else{ track = pos_verbs[str(newverb)]; } }else{ if (j==0){ track = pos_verbs[str(newverb)][0].toUpperCase()+pos_verbs[str(newverb)].slice(1); }else{ track = pos_verbs[str(newverb)]; } } current_content += track; }else if (wordset[j] == "is"){ current_content += "is"; }else if (wordset[j] == "are"){ current_content += "are"; }else{ current_content += "be"; } }else{ if (/jj.*/.test(posset[j])){ var newadj = round(random(0, pos_adj.length-1)); var track2; if (j>=2){ if (wordset[j-1] == "." ){ track2 = pos_adj[str(newadj)][0].toUpperCase()+pos_adj[str(newadj)].slice(1); }else{ track2 = pos_adj[str(newadj)]; } }else{ if (j==0){ track2 = pos_adj[str(newadj)][0].toUpperCase()+pos_adj[str(newadj)].slice(1); }else{ track2 = pos_adj[str(newadj)]; } } current_content += track2; } else if (/rb.*/.test(posset[j])){ var newadv = round(random(0, pos_adv.length-1)); var track3; if (j>=2){ if (wordset[j-1] == "." ){ track3 = pos_adv[str(newadv)][0].toUpperCase()+pos_adv[str(newadv)].slice(1); }else{ track3 = pos_adv[str(newadv)]; } }else{ if (j==0){ track3 = pos_adv[str(newadv)][0].toUpperCase()+pos_adv[str(newadv)].slice(1); }else{ track3 = pos_adv[str(newadv)]; } } current_content += track3; }else{ current_content += wordset[j]; } } if (wordset[j+1] != "." && wordset[j+1] != "!" && wordset[j+1] != "," && wordset[j+1] != "?"){ current_content += " "; } } output.push(current_content); if (t<2) { currentT1.push(current_content) }else if (t>=2 && t<4){ currentT2.push(current_content) }else{ currentT3.push(current_content) } } append(pagearray, output); ////////////////generating high positivity words//////////// for (var t1 = 0; t1 < original_ary.length; t1++){ lexicon = new RiLexicon(); var newstring1 =new RiString (original_ary[t1]) var posset1 = newstring1.pos() var wordset1 = newstring1.words() var current_content1 = ""; for (var j1 = 0; j1 < posset1.length; j1++){ // getting the positive adj,adv,verbs //print("1", wordset1[j1]) // if the word is a verb if (/vb.*/.test(posset1[j1])){ //print("4",wordset1[j1]) // if the word is not is/are/be if (wordset1[j1] != "is" && wordset1[j1] != "are" && wordset1[j1] != "be"){ //print("**", wordset1[j1]) //running for all positive word var newverb1 = round(random(0, pos_verbs_high.length-1)); var trackb1; if (j1>=2){ //print("***", wordset1[j1], wordset1[j1-1]) if (wordset1[j1-1] == "." ){ //print("****", wordset1[j1]) trackb1 = pos_verbs_high[str(newverb1)][0].toUpperCase()+pos_verbs_high[str(newverb1)].slice(1); }else{ //print("*!", wordset1[j1]) trackb1 = pos_verbs_high[str(newverb1)]; } }else{ if (j1==0){ trackb1 = pos_verbs_high[str(newverb1)][0].toUpperCase()+pos_verbs_high[str(newverb1)].slice(1); }else{ trackb1 = pos_verbs_high[str(newverb1)]; } } current_content1 += trackb1; }else if (wordset1[j1] == "is"){ current_content1 += "is"; }else if (wordset1[j1] == "are"){ current_content1 += "are"; }else{ current_content1 += "be"; } }else{ if (/jj.*/.test(posset1[j1])){ //print("2",wordset1[j1]) var newadj1 = round(random(0, pos_adj_high.length-1)); var trackb2; if (j1>=2){ //print("2*", wordset1[j1], wordset1[j1-1]) if (wordset1[j1-1] == "." ){ //print("2**", wordset1[j1]) trackb2 = pos_adj_high[str(newadj1)][0].toUpperCase()+pos_adj_high[str(newadj1)].slice(1); }else{ //print("2!", wordset1[j1]) trackb2 = pos_adj_high[str(newadj1)]; } }else{ if (j1==0){ trackb2 = pos_adj_high[str(newadj1)][0].toUpperCase()+pos_adj_high[str(newadj1)].slice(1); }else{ trackb2 = pos_adj_high[str(newadj1)]; } } current_content1 += trackb2; } else if(/rb.*/.test(posset1[j1])){ //print("3",wordset1[j1]) var newadv1 = round(random(0, pos_adv_high.length-1)); var trackb3; if (j1>=2){ //print("3*", wordset1[j1], wordset1[j1-1]) if (wordset1[j1-1] == "." ){ //print("3**", wordset1[j1]) trackb3 = pos_adv_high[str(newadv1)][0].toUpperCase()+pos_adv_high[str(newadv1)].slice(1); }else{ //print("3!", wordset1[j1]) trackb3 = pos_adv_high[str(newadv1)]; } }else{ if (j1==0){ trackb3 = pos_adv_high[str(newadv1)][0].toUpperCase()+pos_adv[str(newadv1)].slice(1); }else{ trackb3 = pos_adv_high[str(newadv1)]; } } current_content1 += trackb3; }else{ //print("5",wordset1[j1]) current_content1 += wordset1[j1]; } } if (wordset1[j1+1] != "." && wordset1[j1+1] != "!" && wordset1[j1+1] != "," && wordset1[j1+1] != "?"){ current_content1 += " "; //print("6",wordset1[j1]); } } output1.push(current_content1); if (t1<2) { currentT4.push(current_content1) }else if (t1>=2 && t1<4){ currentT5.push(current_content1) }else{ currentT6.push(current_content1) } } append(pagearray, output1); //print("arraybig",pagearray); ////////////////generating low positivity words//////////// for (var t2 = 0; t2 < original_ary.length; t2++){ lexicon = new RiLexicon(); var newstring2 =new RiString (original_ary[t2]) var posset2 = newstring2.pos() var wordset2 = newstring2.words() var current_content2 = ""; for (var j2 = 0; j2 < posset2.length; j2++){ // getting the positive adj,adv,verbs //print("1", wordset2[j2]) // if the word is a verb if (/vb.*/.test(posset2[j2])){ //print("4",wordset2[j2]) // if the word is not is/are/be if (wordset2[j2] != "is" && wordset2[j2] != "are" && wordset2[j2] != "be"){ //print("**", wordset2[j2]) //running for all positive word var newverb2 = round(random(0, pos_verbs_low.length-1)); var trackc1; if (j2>=2){ //print("***", wordset2[j2], wordset2[j2-1]) if (wordset2[j2-1] == "." ){ //print("****", wordset2[j2]) trackc1 = pos_verbs_low[str(newverb2)][0].toUpperCase()+pos_verbs_low[str(newverb2)].slice(1); }else{ //print("*!", wordset2[j2]) trackc1 = pos_verbs_low[str(newverb2)]; } }else{ if (j2==0){ trackc1 = pos_verbs_low[str(newverb2)][0].toUpperCase()+pos_verbs_low[str(newverb2)].slice(1); }else{ trackc1 = pos_verbs_low[str(newverb2)]; } } current_content2 += trackc1; }else if (wordset2[j2] == "is"){ current_content2 += "is"; }else if (wordset2[j2] == "are"){ current_content2 += "are"; }else{ current_content2 += "be"; } }else{ if (/jj.*/.test(posset2[j2])){ //print("2",wordset2[j2]) var newadj2 = round(random(0, pos_adj_low.length-1)); var trackc2; if (j2>=2){ //print("2*", wordset2[j2], wordset2[j2-1]) if (wordset2[j2-1] == "." ){ //print("2**", wordset2[j2]) trackc2 = pos_adj_low[str(newadj2)][0].toUpperCase()+pos_adj_low[str(newadj2)].slice(1); }else{ //print("2!", wordset2[j2]) trackc2 = pos_adj_low[str(newadj2)]; } }else{ if (j2==0){ trackc2 = pos_adj_low[str(newadj2)][0].toUpperCase()+pos_adj_low[str(newadj2)].slice(1); }else{ trackc2 = pos_adj_low[str(newadj2)]; } } current_content2 += trackc2; } else if(/rb.*/.test(posset2[j2])){ //print("3",wordset2[j2]) var newadv2 = round(random(0, pos_adv_low.length-1)); var trackc3; if (j2>=2){ //print("3*", wordset2[j2], wordset2[j2-1]) if (wordset2[j2-1] == "." ){ //print("3**", wordset2[j2]) trackc3 = pos_adv_low[str(newadv2)][0].toUpperCase()+pos_adv_low[str(newadv2)].slice(1); }else{ //print("3!", wordset2[j2]) trackc3 = pos_adv_low[str(newadv2)]; } }else{ if (j2==0){ trackc3 = pos_adv_low[str(newadv2)][0].toUpperCase()+pos_adv_low[str(newadv2)].slice(1); }else{ trackc3 = pos_adv_low[str(newadv2)]; } } current_content2 += trackc3; }else{ //print("5",wordset2[j2]) current_content2 += wordset2[j2]; } } if (wordset2[j2+1] != "." && wordset2[j2+1] != "!" && wordset2[j2+1] != "," && wordset2[j2+1] != "?"){ current_content2 += " "; //print("6",wordset2[j2]); } } output2.push(current_content2); if (t2<2) { currentT7.push(current_content2) }else if (t2>=2 && t2<4){ currentT8.push(current_content2) }else{ currentT9.push(current_content2) } } //append(pagearray, output2); for (var h = 1; h < 10; h++){ if (h<4){ currentlevel = "Generally Positive" }else if (h>=4 && h < 7){ currentlevel = "Highly Positive" }else { currentlevel = "Barely Positive" } var page = {level: currentlevel, phone: window["currentT"+str(h)], image: str("random"+round(random(1,20))+".jpg")} //print(page) final_array.push(page); } // print("hi") // page1.phone = currentT1; // page+str(h).image = str("random"+round(random(1,20))+".jpg") // // page2.phone = currentT2; // // page2.image = str("random"+round(random(1,20))+".jpg") // // page3.phone = currentT3; // // page3.image = str("random"+round(random(1,20))+".jpg") // final_array.push(page+str(h)) // // final_array.push(page2) // // final_array.push(page3) // } } function draw() { background(100,0,100); textAlign(RIGHT); textSize(36); //text(output, 280, 40); textAlign(LEFT); textSize(10); textLeading(14); text(output, 30, 20, 500, 1000); text(output1, 30, 220, 500, 1000); text(output2, 30, 420, 500, 1000); createButton('SAVE POEMS BUTTON') .position(10, 10) .mousePressed(function() { saveJSON(final_array, 'test.json'); }); } |
sepho-book
Title: Exploration?
Description: A generated log/diary of a sailor/explorer.
Zip: https://drive.google.com/open?id=1TessDSHxPt30Q2uxnF5K0VLUhlkLHVRu
Example Chapter: https://drive.google.com/open?id=1u6jQYzeuN5EQFFpsqIsgdtsZk0qZzJu6
nixel-book
Title: Fake Love
Description: A collection of hypocritical songs and ill-fated stars.
PDF zip: here
Chapter sample: here


This project was of interest to me since I've spent a considerable amount of time writing fiction. In the beginning brainstorming phases, I considered making a generative chapter based on my own writing, but I quickly deviated from that idea after browsing the projects from previous years, and this one stood out to me. It was fun and relatable content. I didn't want to remake the same project (although it was tempting), so I thought about how I could apply the same format to my interests. I remembered seeing posts from this twitter account going around, and I really liked the aesthetic of it.
So, the resulting idea was to combine the imagery of Kpop music videos about love with corresponding lyrics. Something that has always struck me as strange is that Kpop idols sing about love all the time, yet they are signed under contracts to never date, or to never fall in love in other words. This is pretty ironic, and I wonder about the validity of their love songs if choosing to date someone is seen as a huge offense. In response to that, this project heavily favors artists who have gone through dating scandals and corrupts lyrics mentioning love.
In terms of coding, this project was less generative, perhaps, and more corruptive. For a while, I tried to work with Rita and Wordnik before realizing I didn't need a new libraries to achieve what I wanted. In this case, less was more.
For grabbing screenshots:
var video; function setup(){ createCanvas(1080, 700); video = createVideo('taeyeon-make-me-love-you.mp4'); video.size(1080, 720); setInterval(takeSnap, 5000); } function takeSnap(){ save('0.jpg'); } function draw(){ image(video, 0, 0) } function mousePressed(){ video.loop(); } |
For corrupting lyrics & exporting JSON:
var myVersesArray = []; var lyricsArray = []; var verseArray = []; var verseObjectArr = []; var data; var newWords; var currVerse = ""; var currentVerse = ""; var corruptedLove = ["ḽ̴̼̃͒̀̽́̔̚̚ơ̶͚͛̿̕̕v̵͓̻͚͔̒͑͛̓͝e̸̼̱̟̖̳̼͙͘", "l̷̙̮̻̚͝ŏ̴̰͍̩̆̔v̸̨̀͂͝e̸̺̜̱̎̃͘", "l̸̥̍̽͐͗̑̊ơ̵͓͓͖̘͖̒̈̀͜v̷̛͇̾͂̔́͆̃̓̈̿̈́͊̉̕͘e̸̼̓̍̍̊̒͐̓͠͠", "ľ̵̡̨̧̢̡̰̺̰͈͇̞̞̺̭͇̞̠̯̬̬̓͝ͅo̴̧̢̲͇̥̟͎̦̝͓͖̗̣͌̅̎̅̈̎̊̃͑̀͒͆͐̍́͊̋̐͋̆͛͐̔͘̚ͅͅṿ̵̧̨̧̲͚̙̙̻̟̝̤̬̟͖̭̮̃̔́͑̀̀̋̓̑̄̄̈̒̅̿̾͆̚͝ę̵̞̩̖̣͔̱͉̻̳̘͉͙͍̆̑͊̈̏͛͊̈̿̕͜͝ͅ", "l̶͈̹̘̹̫̄̓̓̀̀̿̉͌͝͠͝ǒ̵̘̲̩̖̹͎̻̝̐̑̄ͅv̸̧͍̻͙̗̠̜̱̹̖̠͇͚͛͋̓̈́͂̀̆͋̓́̎̕ȩ̵̢̭̻̙̤̪̫̳̤͇͓̎͋̀̍̾̊͋", "l̷̴̛o͏v̸̸́e̡", "l͓̟̗̻̞̪̙̘̹͇̍̋̍̅̋́̉̿̕ơ̡̼̹͓͚̹̎́͊̏͌̍͂̽̓͟v̜̬̭̪̝̽̋̆̅͊e̶̮͔̟̪͍̼̦̐̓̀̄͞ͅ", "ǝʌol", "l̶o̶v̶e̶", "l̶o̶v̶e̶", "☐☐☐☐", "☐☐☐☐", "☐☐☐☐", "----", "¿¿¿¿"] var corruptedLoved = ["l̶o̶v̶e̶d̶", "l̵͏o̧͟v̵͏e̸d̛͟", "ḽ̸̛̪̎̅͗́̄͝͠o̵̗̹͕̗̹̾̕̕͜v̵͍͈̲̙̤͔̩͉̟͈̆̉̋͛͌͠e̶̦̲̖͉̋́̔̓͗̔d̸̩̬̮͙̦̲̬̲͈̳̈́", "☐☐☐☐☐","¿¿¿¿¿"] class Verse { constructor(verse) { this.verse = verse; } } function setup() { createCanvas (300, 100); background(200); data = loadStrings('lyrics.txt'); createButton('SAVE LYRICS BUTTON') .position(10, 10) .mousePressed(function() { saveJSON(myJsonObject, 'myVerses.json'); }); } function replaceLove(){ for (var i = 0; i < data.length; i++){ var mapObj = { love: corruptedLove[Math.floor(random(0, corruptedLove.length))], loved: corruptedLoved[Math.floor(random(0, corruptedLoved.length))] }; var words = data[i]; newWords = words.replace(/love|loved/gi, function(matched){return mapObj[matched];}); lyricsArray.push(newWords); } for (var z = 0; z < lyricsArray.length; z++){ verseArray.push(lyricsArray[z]); } for (var y = 0; y < verseArray.length; y++){ if (verseArray[y] != " "){ currVerse = currVerse + "\n" + verseArray[y]; } else { myVersesArray.push(currVerse); var aVerse = new Verse(currVerse); verseObjectArr[y] = aVerse; currVerse = ""; } } } var myJsonObject = {}; myJsonObject.verses = verseObjectArr; function mousePressed(){ replaceLove(); console.log(lyricsArray) } |
For layout in InDesign:
#include "../../bundle/basil.js"; var jsonString; var jsonData; //-------------------------------------------------------- function setup() { jsonString = b.loadString("Verse1.json"); b.clear (b.doc()); jsonData = b.JSON.decode( jsonString ); b.println("Number of elements in JSON: " + jsonData.length); var captionX = 300; var captionY = b.height/2-50; var captionW = b.width/2 + 210; var captionH = 136; var imageX = 0; var imageY = 0; var imageW = 72*8.5; var imageH = 72*8.5; for (var i = 0; i < 12; i++) { b.addPage(); b.rotate(-1.57); b.noStroke(); var imgNum1 = b.floor(b.random(1,200)); var imgNum2 = b.floor(b.random(201,208)); var anImageFilename1 = "images2/" + imgNum1 + ".jpg"; var anImage1 = b.image(anImageFilename1, imageX, imageY, imageW, imageH); var anImageFilename2 = "images2/" + imgNum2 + ".jpg"; var anImage2 = b.image(anImageFilename2, imageX, imageY, imageW, imageH); anImage1.fit(FitOptions.PROPORTIONALLY); anImage2.fit(FitOptions.PROPORTIONALLY); b.transformImage(anImage1, 0, 0, 615, 900); b.transformImage(anImage2, imageX + 800, 0, 615, 900); b.pushMatrix(); b.fill(0); b.rect(72*6.7,72*12,72*13,140); b.popMatrix(); b.fill(255); b.textSize(20); b.textFont("Helvetica","Italic"); b.textAlign(Justification.CENTER_ALIGN, VerticalJustification.TOP_ALIGN ); var text = Math.floor(Math.random(1, 39)); b.text(jsonData[text].verse, captionX,captionY,captionW,captionH); }; } b.go(); |
weirdie-book
Title: Extraterrestrial
Description: A randomly generated planetary system, some more odd than others.
ZIP file: https://drive.google.com/file/d/1yUczalct7xfK-ImtEHVy2psxaDYRlB W0/view?usp=sharing
Sample Chapter: https://drive.google.com/file/d/1Fiws_jW0sUUF4xBt384MC7pvyvD-mh4f/view?usp=sharing

For the generative text project, I knew that I wanted to create something related to sci-fi, as I've been taking a sci-fi literature class and was inspired by the idea of using generated text and image to explore "the unknown".
As someone who doesn't find writing natural, I began with the image generator. To make the images of the planets, I randomly generated two colors. I then used p5.js' "lerpColor" function to create a gradient between these two that would determine the color palette for each planet. I then used perlin noise to decide the ranges for 3 colors along that gradient. Each planet was also given a random number of moons, and a random radius size. Later on, this became attached to the random moons and radii that the text itself was generating. 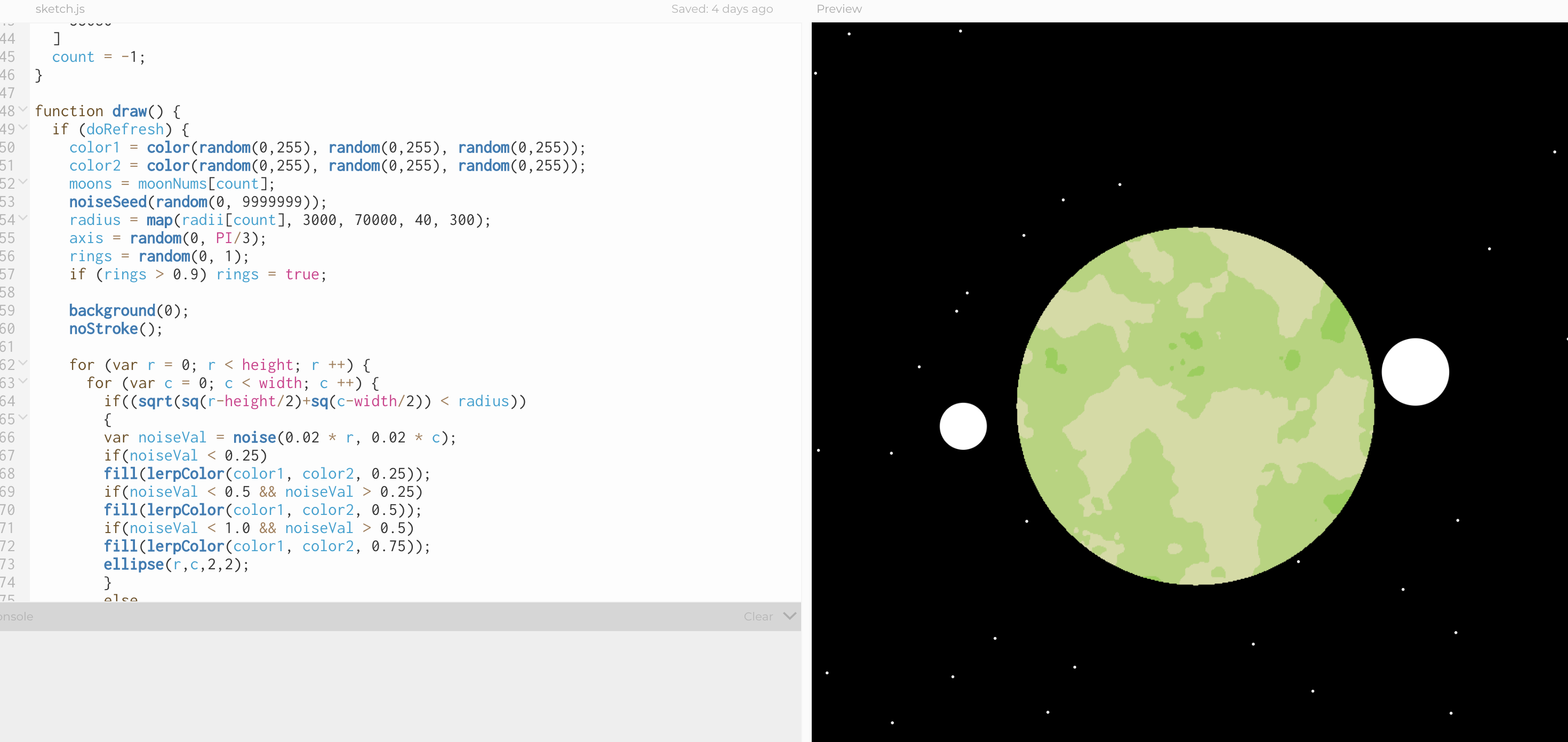
Generating the text itself proved to be a bit frustrating. I first started by generating the name of the planets themselves. The text corpora had a list of planets, and I used wikipedia to find an additional list of minor planets and moons. From these, I randomly generated names for the planets by randomly choosing two names, and splicing random amounts of their characters together. For the name of each system, I simply chose a name from the list.
For the generated text, I used context-free grammar through Rita.js. For each planet, the name, number of moons, moon names, and radius of the planet would be randomly chosen. Then a type of planet (exoplanet, ice planet, terrestrial, etc) would be chosen, and a corresponding climate would be selected. Based on the climate, the habitability and the types of flora and fauna would be selected. Finally, a the generator would choose from a list of possible "other interests" of the planet, such as it being a location that is good for mining, choosing a material from a list from the text corpora of metals.

I would love to revisit this project in the future to dive deeper into the complexity of the generative text. While the results are different from one to the next, they clearly all follow the same structure, which isn't that interesting. I'd be interested to try using Wikipedia's API to potentially use Markov chaining and Rita.js to filter through descriptions of planets from sci-fi novels. I think this project has the potential for something interesting, but it's definitely not there yet.

Code:
Images:
// noprotect var radius; var color1; var color2; var doRefresh; var moons; var axis; var rings; var moonNums; var radii; var count; function setup() { createCanvas(800, 800); doRefresh = true; rings = false; moonNums =[ 3, 2, 1, 2, 3, 0, 2, 2, 3, 0, 1 ] radii =[ 66083, 48507, 44055, 44710, 68424, 4328, 46568, 40628, 67003, 23938, 55680 ] count = -1; } function draw() { if (doRefresh) { color1 = color(random(0,255), random(0,255), random(0,255)); color2 = color(random(0,255), random(0,255), random(0,255)); moons = moonNums[count]; noiseSeed(random(0, 9999999)); radius = map(radii[count], 3000, 70000, 40, 300); axis = random(0, PI/3); rings = random(0, 1); if (rings > 0.9) rings = true; background(0); noStroke(); for (var r = 0; r < height; r ++) { for (var c = 0; c < width; c ++) { if((sqrt(sq(r-height/2)+sq(c-width/2)) < radius)) { var noiseVal = noise(0.02 * r, 0.02 * c); if(noiseVal < 0.25) fill(lerpColor(color1, color2, 0.25)); if(noiseVal < 0.5 && noiseVal > 0.25) fill(lerpColor(color1, color2, 0.5)); if(noiseVal < 1.0 && noiseVal > 0.5) fill(lerpColor(color1, color2, 0.75)); ellipse(r,c,2,2); } else { var star = random(0,1); if(star < 0.00005) { fill(255); ellipse(r,c,3,3); } } } } for(var m = 0; m < moons; m++) { fill(lerpColor(color1, color(255), 1/m)); var rad = random(radius*0.15, radius*0.4); var x = random(10, rad*2); var y = random(height/2-50, height/2+50); if(m % 2 == 0) { ellipse(width/2-radius-x+20, y, rad, rad); } else { ellipse(width/2+radius+x-20, y, rad, rad); } } } doRefresh = false; } function keyPressed() { saveCanvas('planet' + count, 'png'); } function mousePressed() { count++; doRefresh = true; } |
Text Generator:
var rg; var button; var result; var x, y; var moons; var names; var Planets = []; var system; var size; var sizes = []; var moonNums = []; class Planet { constructor(name, moonNum, size, description) { this.name = name; this.moonNum = moonNum; this.size = size; this.description = description; } } function setup() { result = "click to generate" createCanvas(400, 400); background(250); x = 100; y = 100; text(result, x, y, 400, 400); names = (insert very long list of names here) ]; system = names[floor(random() * names.length)]; rg = new RiGrammar(); rg.loadFrom('grammar_yay.json', grammarReady); function grammarReady() { console.log('ready'); // console.log(result); } var myJsonObject = {}; myJsonObject.system = system; myJsonObject.planetarySystem = Planets; myJsonObject.sizes = sizes; myJsonObject.moonNums = moonNums; // Make a button. When you press it, it will save the JSON. createButton('SAVE POEMS BUTTON') .position(10, 10) .mousePressed(function() { saveJSON(myJsonObject, 'planetDescriptions.json'); }); } function mousePressed() { var numPlanets = 11; for (var i = 0; i < numPlanets; i++) { var n1 = names[floor(random() * names.length)]; var n2 = names[floor(random() * names.length)]; var n3 = names[floor(random() * names.length)]; var l1 = floor(random(2, n1.length-1)); var l2 = floor(random(2, n2.length-1)); var l3 = floor(random(2, n2.length-1)); var aName = n1.substring(0,l1) + n2.substring(1, l2) + n3.substring(1, l3); var m = random(0, 1); var aMoonNum; if (m < 0.3) { aMoonNum = 0; } else if (m >= 0.3 && m < 0.6) { aMoonNum = 1; } else if (m >= 0.6 && m < 0.8) { aMoonNum = 2; } else { aMoonNum = 3; } var aMoons = []; for (var a = 0; a < aMoonNum; a++) { aMoons[a] = names[floor(random() * names.length)]; } var diameter = floor(random(2000, 70000)); var aDescription = ""; newPlanet(); if(i == 0) { aDescription = aName + " is the 1st planet in the " + system + " System. It has "; } else if(i == 1) { aDescription = aName + " is the 2nd planet in the " + system + " System. It has "; } else if(i == 2) { aDescription = aName + " is the 3rd planet in the " + system + " System. It has "; } else { aDescription = aName + " is the " + (i+1) + "th planet in the " + system + " System. It has "; } if(aMoonNum == 0) { aDescription = aDescription + "no moons. "; } else if(aMoonNum == 1) { aDescription = aDescription + aMoonNum + " moon, which is called " + aMoons[0] + ". "; } else if(aMoonNum == 2) { aDescription = aDescription + aMoonNum + " moons, which are named " + aMoons[0] + " and " + aMoons[1] + ". "; } else if(aMoonNum == 3) { aDescription = aDescription + aMoonNum + " moons, which are named " + aMoons[0] + ", " + aMoons[1] + ", and " + aMoons[2] + ". "; } size = floor(random(3000, 70000)); aDescription = aDescription + "It has a radius of " + size + " kilometers. "; aDescription = aDescription + aName + " is " + result; var aPlanet = new Planet(aName, aMoonNum, size, aDescription); Planets[i] = aPlanet; sizes[i] = size; moonNums[i] = aMoonNum; } } function newPlanet() { result = rg.expand(); result = result.replace(/% /g, '\n'); console.log("\n" + result); drawPlanet(); } function drawPlanet() { background(250); text(result, x, y, 200, 200); } |
Grammar.js file:
{ "": [ "" ], "": [ "" ], "" : [ "", "The planet's deposits make it the location of a valuable mining colony.", "", "The planet is a popular tourist desination in the solar system.", "", "Attempts have been made to begin terraforming here.", "It has the potential for colonization in the future.", "", "It is unlikely humans will ever visit." ], "" : [ "", "", "", "" ], "" : [ "Due to the high amount of in the atmosphere, nothing can survive. ", "Although beautiful, is incapable of sustaining life. ", "It is incapable of sustaining life. ", "No life has been found. ", "There is little chance of life. ", "There is no chance of life. " ], "" : [ "frigid temperatures", "freezing temperatures", "constant snowstorms", "constant blizzards", "constant hail" ], "" : [ "Its proximity to the sun and thin atmosphere cause the heat to be almost unbearable. ", "The planet is known for its constant violent sandstorms. " ], "" : [ "The surface is covered with boiling lava. " ], "" : [ "There is very little life here. The climate mainly consists of <1>, and as such only small shrubs and trees are able to grow. ", "There is very little life here. The climate is entirely <1H>, and as such life here consists mainly of shrubs and small mammals. " ], "": [ "There is some life here. The planet is mainly covered with <2>, with a variety of , , and . " ], "" : [ "There is an abundance of life here. It is known for its <3>, which are home to many types of and . " ], "" : [ "birds", "bats", "small animals", "butterflies", "mammals", "reptiles", "insects", "arachnids" ], "" : [ "trees", "flowers", "mosses", "plants" ], "" : [ ], "" : [ " It is also home to -like aliens who , and are known for being , creatures. ", " It is also home to -like aliens who , and are known for being , creatures. ", " It is also home to -like aliens who , and are known for being , creatures. " ], "" : [ "are highly intelligent and advanced", "are pretty stupid", "have only begun to develop tools" ], "<1>" : [ "tundras", "dry deserts", "hot deserts", "semiarid deserts" ], "<1H>" : [ "dry deserts", "deserts", "semiarid deserts" ], "<2>" : [ "savannas", "forests" ], "<3>" : [ "tropical forests", "deciduous forests", "tropical regions", "forests", "swamps" ], "" : [ "The waters here house numerous species of plants and animals, both large and small. ", "Here, the fauna include many species of fish and some mammals, such as whales and dolphins. Much of the sea life here feeds on the abundant plankton. ", "Flora are represented primarily by seaweed while the fauna, since it is very nutrient-rich, include all sorts of bacteria, fungi, sponges, sea anemones, worms, sea stars, and fishes. ", "Chemosynthetic bacteria thrive near these vents because of the large amounts of hydrogen sulfide and other minerals they emit. These bacteria are thus the start of the food web as they are eaten by invertebrates and fishes. " ], "" : [ "a chthonian planet. ", "a carbon planet. ", "a coreless planet. ", "a gas dwarf. ", "a helium planet. ", "an ice giant. The make it uninhabitable.", "an ice planet. The climate is exlusively tundra, and it is known for its . ", "an iron planet. ", "a puffy planet. ", "a silicate planet. ", "a terrestrial planet. ", "a gas giant. ", "a giant. ", "an exoplanet. ", "a lava planet. ", "a mesoplanet. ", "a telluric planet. ", "a rocky planet. ", "a protoplanet.", "an ocean planet. ", "a desert planet. The climate is mostly <1H>, with little life other than the which call it home." ], "" : [ "cacti", "shrubs", "spiders", "scorpions", "moths", "herbs", "small trees", "bushes" ], "" (insert list of poisons here) "" (insert long list of animals here) |
breep-book


URL Link to to Zip file:
https://drive.google.com/open?id=1mXvIeBIjU3qrf3-heWDO1dSfpWrZdWjk
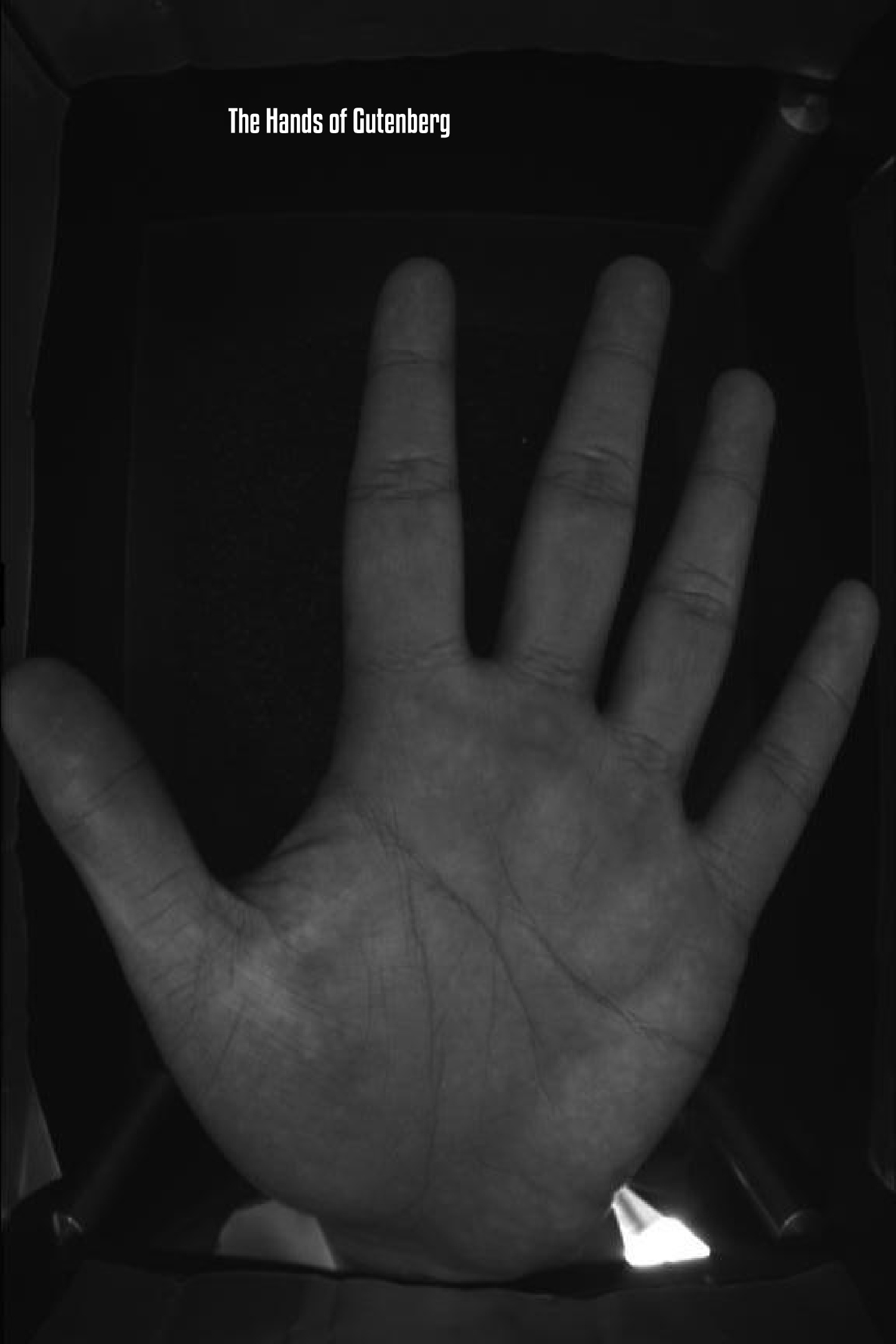
Title: The Hands of Gutenberg
Chapter Description: A series of sonnets with first lines containing the word 'hand' generated from the Gutenberg Poetry corpus overlaid on images of multispectral palmprints. (EDIT: I later notices the that the hand lines have moved down the sonnet as the poems progress)
Using the Gutenberg Poetry corpus as my starting point, I wanted to explore ways to generate or find Iambic pentameters. The primary basis for this was that I wanted my final poems to make some semblance of rhyming sense, using the stress structure of the Iambic pentameter to act as a platform in assisting this.
Taking the some 3 millions lines of poetry in the corpus, I created two programs: One to filter out all the Iambic Pentameters that had the word 'Hand' in it (taking primary inspiration for this from a dataset of handprint images that I wanted to use), and another to filter out all the Iambic Pentameters. I discovered that there were only 18 lines that possessed the word hand, nowhere near enough to use to generate all my poems as I initially intended. Instead, I decided to use these lines as the starting lines for 18 poems, creating a structure of starting point that could connect all 25 iterations of the chapter (a notion I was a big fan of).
From this I started to find rhymes for these lines in the larger Iambic line corpus I had found, and again was woefully short of lines. From this I decided to create the structure of randomly finding a line with the body of Iambics and swapping out the last word (which I filtered out with matching structure (noun, adjective etc) with the line before to make the replacement more sensible) with a word that rhymed with the line before and had the Iambic stress structure. From this I had to use RiTa to find rhymes for the lines, from which I ran into a snag of rhyming with plurals (which made rhyming but not grammatical sense) which I sorted by removing the final 's' on each one (it also didn't like old english use of apostrophes, for example walk'd, which I largely also swapped out for e) . With this all completed, I had 18 pairs of lines which I felt could be extended, hence the continuation to 14 lines in the structure of a sonnet using another 6 random line pairings found from the corpus. With these generated, I then had to create a program to filter these collections into JSON files to be used for the generative layouts.
With this completed, I started to sort through all the and images, and divided them into left and right facing hands, and using this divide randomly generated hand pairings for the pages of the book such that the thumbs faced toward the spine and the space left above them could be used to place the text within.
Overall, I had initially intended to use an image set as a starting point but found that for the sake of poetic sense I should use the text. Having generated the Iambics, I sorted through image sets at hand to determine what pairings between image and text could be made, and thus the connection between the hands came about.
I am particularly happy with the outcome, especially the extent to which the poetic license of the sonnets is pushed. However, I feel that this could definitely be taken further, where instead of randomly finding new lines to fill in the sonnets, I would filter the Iambics for their content and generate poems whose lines connected more with the content they possessed. Through this, my swapping of final words to rhymes could also be greater filtered in connection to the line it is being swapped into to ensure more sense as well.
Finding Iambics with Hand (Initially in P5Js):
var data; function preload(){ data = loadStrings("finger.txt") } function setup() { createCanvas(400, 400); final = createIambs(); print(final); } function createIambs() { var stressList = []; var finalIambs = []; for (var i = 0; i < data.length; i++){ currentStress = RiTa.getStresses(data[i]); currentStress = currentStress.replace("/", " "); currentStress = currentStress.replace(" , ", " "); currentStress = currentStress.replace("1/0", "1 0"); currentStress = currentStress.replace("1/1", "1 1"); currentStress = currentStress.replace("0/1", "0 1"); stressList.push(currentStress); if (currentStress == "0 1 0 1 0 1 0 1 0 1"){ finalIambs.push(data[i]); } } return finalIambs; } |
Sonnet Builder (Processing):
import rita.*; String startLines[]; String buildLines[]; PrintWriter outputter; String[] finalWords = new String[18]; String[] testerRhymes = new String[20]; String[][] dictionary = new String[18][15]; String[] finalPairings = new String[18]; void setup(){ startLines = loadStrings("handIambs.txt"); buildLines = loadStrings("gutenbergIambics.txt"); outputter = createWriter("data/finalPoems.txt"); int numberStartLines = startLines.length; int numberBuildLines = buildLines.length; for (int i = 0; i < numberStartLines; i++){ String currentStartLine = startLines[i]; String[] dataRows = currentStartLine.split(" "); String finalWord = dataRows[dataRows.length-1]; finalWords[i] = finalWord; String[] rhymes = RiTa.rhymes(finalWord); String currentType = ""; if (RiTa.isNoun(finalWord)){ currentType = "Noun"; } if (RiTa.isVerb(finalWord)){ currentType = "Verb"; } if (RiTa.isAdjective(finalWord)){ currentType = "Adjective"; } if (RiTa.isAdverb(finalWord)){ currentType = "Adverb"; } String currentStress = RiTa.getStresses(finalWord); //for (int k = 0; k < rhymes.length; k ++){ int k = 0; while ( k < rhymes.length){ String currentRhyme = rhymes[k]; String currentRhymeType = ""; if (RiTa.isNoun(finalWord)){ currentRhymeType = "Noun"; } if (RiTa.isVerb(finalWord)){ currentRhymeType = "Verb"; } if (RiTa.isAdjective(finalWord)){ currentRhymeType = "Adjective"; } if (RiTa.isAdverb(finalWord)){ currentRhymeType = "Adverb"; } String currentRhymeStress = RiTa.getStresses(currentRhyme); if (currentRhymeType != currentType){ rhymes = concat(subset(rhymes, 0, k-1), subset(rhymes, k+1, rhymes.length-1 - k)); } /*if (currentStress != currentRhymeStress){ rhymes = concat(subset(rhymes, 0, k-1), subset(rhymes, k+1, rhymes.length-1 - k)); }*/ k += 1; } //print(rhymes); Boolean wordFound = false; while (wordFound == false){ int randomIndex = floor(random(405)); String currentRandomLine = buildLines[randomIndex]; String[] randomLine = currentRandomLine.split(" "); String randomFinalWord = randomLine[randomLine.length-1]; String currentRhymeType = ""; if (RiTa.isNoun(randomFinalWord)){ currentRhymeType = "Noun"; } if (RiTa.isVerb(randomFinalWord)){ currentRhymeType = "Verb"; } if (RiTa.isAdjective(randomFinalWord)){ currentRhymeType = "Adjective"; } if (RiTa.isAdverb(randomFinalWord)){ currentRhymeType = "Adverb"; } if (currentRhymeType == currentType){ String randomRhyme = rhymes[floor(random(rhymes.length))]; randomLine[randomLine.length-1] = randomRhyme; print(randomLine); wordFound = true; } finalPairings[i] = currentStartLine + "\n" + randomLine; } } } void draw(){ } |
JSON Builder (Processing):
JSONArray json; String[] lines; JSONObject[] jsonList = new JSONObject[20]; void setup() { for (int a = 0; a < 25; a++){ lines = loadStrings("testingFinalSonnets" + a + ".txt"); json = new JSONArray(); for (int i=0; i < 20; i++){ JSONObject currentSonnet = new JSONObject(); if (i == 0){ currentSonnet.setInt("Id", 0); currentSonnet.setString("text", "The Hands of Gutenberg"); json.setJSONObject(i, currentSonnet); continue; } if (i == 19){ currentSonnet.setInt("Id", 19); currentSonnet.setString("text", ""); json.setJSONObject(i, currentSonnet); continue; } String currentString = join(subset(lines, i*14, 14), "\n"); currentSonnet.setInt("Id", i); currentSonnet.setString("text", currentString); json.setJSONObject(i, currentSonnet); } saveJSONArray(json, "data/finalSonnets" + a + ".json"); } } |
Generative Layout (Processing) (Starter Code courtesy of Golan Levin):
// Export a multi-page PDF alphabet book. import processing.pdf.*; boolean bExportingPDF; // See https://processing.org/reference/libraries/pdf/index.html int nPages; PImage imageArray[]; JSONArray jsonPages; int outputPageCount = 0; PFont highQualityFont32; PFont highQualityFont100; float inch = 72; String pdfName; //======================================================= void setup() { // The book format is 6" x 9". // Each inch is 72 pixels (or points). // 6x72=432, 9*72=648 // USE THESE COMMANDS WHEN YOU'RE NOT EXPORTING PDF, // AND YOU JUST WANT SCREEN DISPLAY: //size(432, 648); bExportingPDF = false; size(432, 648, PDF, "24-breep.pdf"); bExportingPDF = true; int m = 24; if (m / 10 == 0){ pdfName = "0" + m + "-breep.pdf"; } else{ pdfName = m + "-breep.pdf"; } //size(432, 648, PDF, "00-breep.pdf"); //bExportingPDF = true; //-------------------- // For high-quality (vector) typography: // See https://processing.org/reference/libraries/pdf/index.html // "Another option for type, is to use createFont() with a TrueType font // (some OpenType fonts also work). Any font that shows up in PFont.list() // should work, or if not, adding a .ttf file to the data directory // and calling createFont("fontname.ttf") will also work. highQualityFont32 = createFont("vag.ttf", 32); highQualityFont100 = createFont("vag.ttf", 100); jsonPages = loadJSONArray("text/finalSonnets" + m + ".json"); nPages = jsonPages.size(); // Load the images from the data folder, // Using the filenames from the JSON array. imageArray = new PImage[nPages]; for (int i=0; i<nPages; i++) { JSONObject aPage = jsonPages.getJSONObject(i); int currentHand = (i + 1) + (m*10); String imageFileName = ""; if (i % 2 == 0){ imageFileName = "images/joint/" + "rightHand" + currentHand + ".jpg"; } else{ imageFileName = "images/joint/" + "leftHand" + currentHand + ".jpg"; } imageArray[i] = loadImage(imageFileName); } } //======================================================= void draw() { if (bExportingPDF) { drawForPDFOutput(); } else { drawForScreenOutput(); } } //======================================================= void drawForPDFOutput() { // When finished drawing, quit and save the file if (outputPageCount >= nPages) { exit(); } else { drawPage(outputPageCount); PGraphicsPDF pdf = (PGraphicsPDF) g; // Get the renderer if (outputPageCount < (nPages-1)) { pdf.nextPage(); // Tell it to go to the next page } } outputPageCount++; } //======================================================= void drawForScreenOutput() { int whichPageIndex = (int) map(mouseX, 0, width, 0, nPages); drawPage(whichPageIndex); } //======================================================= void drawPage(int whichPageIndex) { background(255); whichPageIndex = constrain(whichPageIndex, 0, nPages-1); JSONObject whichPageObject = jsonPages.getJSONObject(whichPageIndex); // Fetch and render image PImage whichImage = imageArray[whichPageIndex]; float imgWRaw = whichImage.width; float imgHRaw = whichImage.height; float imgW = max(imgWRaw, width*0.85); float imgScale = imgW/imgWRaw; float imgH = imgHRaw* imgScale; float imgX = (width - imgW)/2.0; float imgY = height - imgH - inch*1.5; image(whichImage, 0, 0, width, height); // Assemble body text String captionString = whichPageObject.getString("text"); // Display body text textFont(highQualityFont32); fill(255); textAlign(CENTER); textSize(15); if (whichPageIndex % 2 == 0){ text(captionString, (width/3) + 20, height/10); } else{ text(captionString, ((width/3) * 2) - 20, height/10); } } |
ocannoli-Book
John Mulaney's Comedy Hour By Dr. Suess
This is a generative Dr.Suess book but with a twist. It's a mashup of standup comedy John Mulaney in the stylings of Dr. Suess.




Most of my ideas involved mashing two genres of literature together and eventually I decided I really wanted to make a Dr. Suess book. However, just making a Dr. Suess book seemed boring, so my initial idea was to make a dirty version of Dr. Suess. After hearing the lectures by Parrish and Sloan, the concept of specificity stuck with me, so I decided to combine Dr.Suess with one of my favorite stand-up comedians John Mulaney. Initially, I spent a lot of time trying to use stresses, syllables, and creating rhyme schemes to replicate the style of Dr. Suess more accurately. However, the results seemed stale, too forced, and most importantly were not that interesting. So I decided to scratch that idea and start experimenting more with markov chains. Ultimately, I liked the results but did not delve into it as much as I wanted too. If I was to continue this project, I would want to manipulate the results from the markov chain more to fit a better rhyme scheme and have a standardized stress pattern that could be different for each book. Additionally, the images were not as in depth as I wanted for originally I wanted to generate unique Dr. Suess "shapes" or simple illustrations, but instead they are just images taken from online. Overall, I think this is a good starting point but needs work in the execution for a final product.
var rhyme,rhymeBunch,line1, markov, data1, data2, x = 160, y = 240; var img; function preload() { data1 = loadStrings('john.txt'); data2 = loadStrings('suess.txt'); //data3 = loadStrings('Readme_en.txt'); //data4 = loadStrings('ReadMe.txt'); } function setup() { createCanvas(500, 500); textFont('times', 16); textAlign(LEFT); line1 = ["click to (re)generate!"]; // create a markov model w' n=4 markov = new RiMarkov(2); // load text into the model markov.loadText(data1.join(' ')); markov.loadText(data2.join(' ')); //markov.loadText(data3.join(' ')); //markov.loadText(data4.join(' ')); drawText(); } function drawText() { background(250); text(line1, x, y, 400, 400); } function mouseClicked() { x = y = 50; var repeat=true; while (repeat==true){ line1 = markov.generateSentence(1); line1= new RiString(line1); line1.toLowerCase(); line1.replaceChar(0, line1.charAt(0).toUpperCase()); line1=String(line1) line1=line1.replace(/[\[\]']+/g,''); linesList=line1.split(" "); rhyme=linesList[(linesList.length)-1]; rhymeBunch=RiTa.rhymes(rhyme); if (rhymeBunch.length>2){ repeat=false; } } for (i=0;i<1;i++){ var nLine = markov.generateSentence(1); var nList=nLine.split(" "); var spot=int(random(rhymeBunch.length-1)); var newRhyme=rhymeBunch[spot]; var oldSpot=(nList.length); nLine=new RiString(nLine); nLine.replaceWord(oldSpot,newRhyme); nLine.toLowerCase(); nLine=String(nLine); nLine=nLine.replace(/[\[\]']+/g,''); line1=line1+" "+nLine; var testLength=line1.split(" "); if (testLength.length < 12){ i-=1; } } drawText(); } |