Pizza Time
Pizza Time transforms a foam core structure into a Pizza Food Truck!
60212: INTERACTIVITY & COMPUTATION
CMU School of Art, Fall 2018 • Prof. Golan Levin / TA: Char Stiles
Pizza Time transforms a foam core structure into a Pizza Food Truck!
Intro:

Part 1:

Part 2:

Part 3:
Part 4:

Part 5:
part 6:
part 7:
part 8:
part 9:
part 10:
part 11:
part 12:

part 13:
part 14:
part 15:
What stuck with me about Parrish's talk was the overall theme of the exploration of uncertainty. It's something thats commonly done in science/math areas, yet not so much in the humanities. Parrish gives many options to exploring the unknown, from the most literal way--for example, mapping out semantic space through n-grams, and finding the empty spaces--to more abstract ways, such as creating new words through splicing existing words together and generating new definitions. It was something I thought about a lot as I was working on the book project as well, since I felt pulled towards making something more generative/abstract, yet ultimately made something that explored connections between existing language. These two sides of the spectrum feel like the two types of infinity, one that exists between numbers and goes towards the infinitely small, and the other one that exists towards infinite largeness.
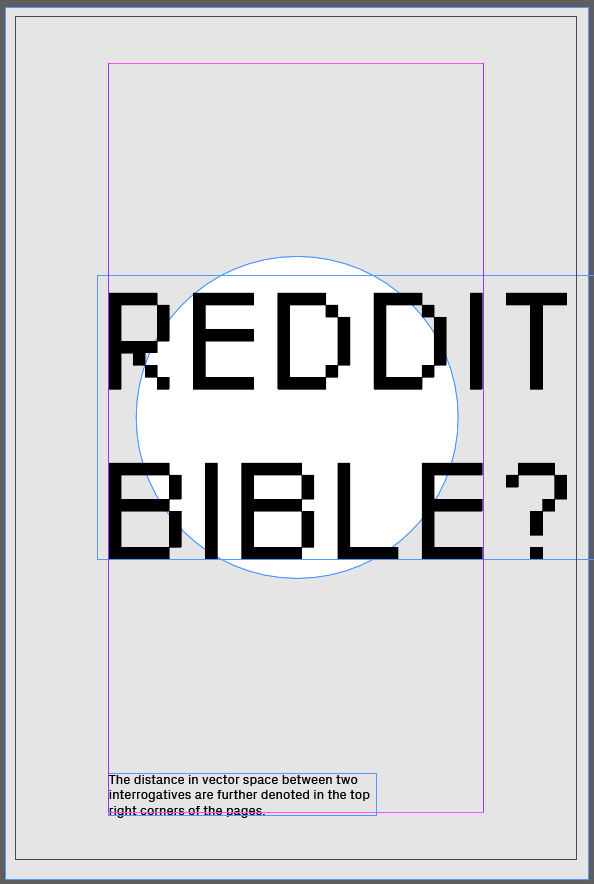
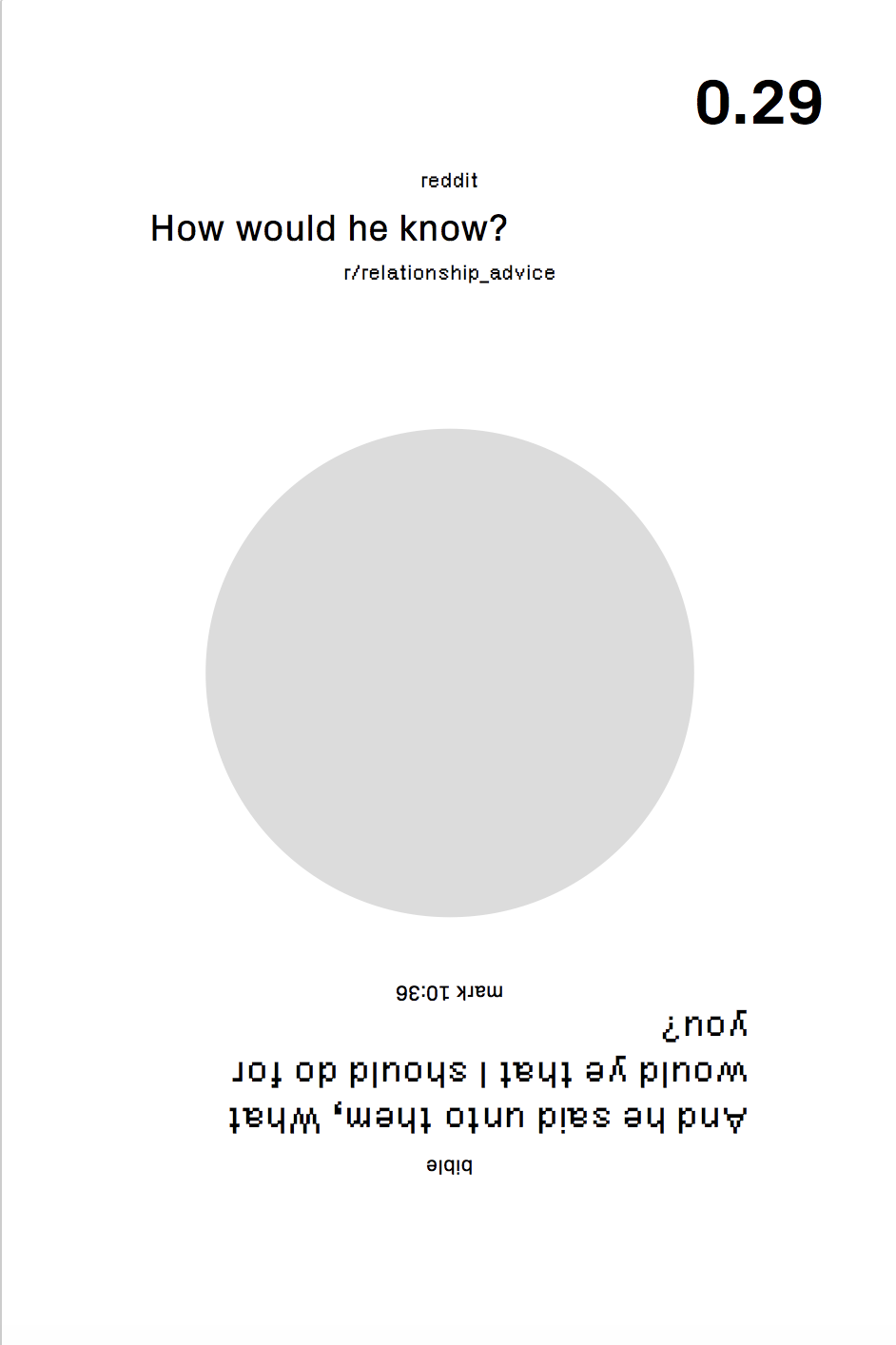
In short, the Reddit Bible compares questions found on 8 advice boards of reddit with interrogative sentences found in the bible.
After much wrangling with religious-text based concepts, I decided to create a "Reddit Advice" board by answering biblical questions with Reddit content. I scraped the Bible for interrogative sentences, and found similarities in questions scraped from Reddit advice boards, using sentence embedding. From there, I wanted to to answer the Bible Questions with Markov-chain generated answers based on the thread responses of the respective Reddit questions.
Unexpectedly, I loved the results of the "similar" reddit and bible questions--the seeming connections between the two almost hint at some sort of relation between the questions people are asking now and in Biblical times. Though I did go through with the Markov chained responses, the results were a bit jumble-y and seemed to take away from what I liked about the juxtaposed questions. Ultimately, I made the decision to cut the Markov chains, and to highlight the contrast in pairs of questions, as well as how similar the computer thinks the question pairs are.
I originally wanted to generate some sort of occult text, ie. Chinese Divination. I ended up pivoting to the more normative of religious texts, the Bible to be specific, since I have a lot of personal experience with this one. Prior to the "reddit advice" board, I actually had the opposite idea, of making a "christian advice" board where I would gather 4chan questions, and answer them with markov chain generated responses based on real christian advice forums. I scraped a christian advice forum, but the results were too few and inconsistent, so I knew I had to pivot a bit. That's when I flipped the idea and decided to reverse it to answering bible questions with reddit data. (4chan's threads were a little too inconsistent and lacking compared with reddits thousand-count response threads).
If anyone ever wants buttloads of responses from a christian forum: https://github.com/swlsheltie/christian-forum-data
Once I solidified my concept, it was time to execute, one step at a time.
# REDDIT QUESTIONS X BIBLE QUESTIONS # ENTER A SUBREDDIT # FIND ALL QUESTIONS # INFERSENT WITH BIBLE QUESTIONS # GET LIST OF [DISTANCE, SUBREDDIT, THREAD ID, SUBMISSION TEXT, BIBLE TEXT] # HIGHLIGHT SPECIFIC QUESTION # load 400 iterations # format [distance, subreddit, reddit question, bible verse, bible question] # get bible questions from final_bible_questions import bible_questions from split_into_sentences import split_into_sentences # write to file data_file= open("rqbq_data.txt", "w") rel_advice_file = open("rel_advice.txt", "w") legal_advice_file = open("legal_advice.txt", "w") tech_support_file = open("tech_support.txt", "w") need_friend_file = open("needfriend.txt", "w") internetparents_file = open("internetparents.txt", "w") socialskills_file = open("socialskills.txt", "w") advice_file = open("advice.txt", "w") needadvice_file = open("needadvice.txt", "w") files = [rel_advice_file, legal_advice_file, tech_support_file, need_friend_file, internetparents_file, socialskills_file, advice_file, needadvice_file] # libraries import praw import re # reddit keys reddit = praw.Reddit(client_id='---', client_secret='---', user_agent='script: http://0.0.0.0:8000/: v.0.0(by /u/swlsheltie)') # enter subreddit here ------------------------------------------------------------------------------------action required list_subreddits = ["relationship_advice", "legaladvice", "techsupport", "needafriend", "internetparents", "socialskills", "advice", "needadvice"] relationshipadvice = {} legaladvice={} techsupport={} needafriend={} internetparents={} socialskills={} advice={} needavice={} subreddit_dict_list=[relationshipadvice, legaladvice, techsupport, needafriend, internetparents, socialskills, advice, needavice] relationshipadvice_questions = [] legaladvice_questions =[] techsupport_questions=[] needafriend_questions=[] internetparents_questions=[] socialskills_questions=[] advice_questions=[] needavice_questions=[] questions_list_list=[relationshipadvice_questions, legaladvice_questions, techsupport_questions, needafriend_questions, internetparents_questions, socialskills_questions, advice_questions, needavice_questions] # sub_reddit = reddit.subreddit('relationship_advice') for subreddit in list_subreddits: counter=0 print(subreddit) i = list_subreddits.index(subreddit) sub_reddit = reddit.subreddit(subreddit) txt_file_temp = [] for submission in sub_reddit.top(limit=1000): # print(submission) print("...getting from reddit", counter) submission_txt = str(reddit.submission(id=submission).selftext.replace('\n', ' ').replace('\r', '')) txt_file_temp.append(submission_txt) counter+=1 print("gottem") for sub_txt in txt_file_temp: print("splitting") sent_list = split_into_sentences(sub_txt) for sent in sent_list: print("grabbing questions") if sent.endswith("?"): questions_list_list[i].append(sent) print("writing file") files[i].write(str(questions_list_list[i])) print("written file, next") # for list_ in questions_list_list: # print("\n") # print(list_subreddits[questions_list_list.index(list_)]) # print(list_) # print("\n") |
file = open("bible.txt", "r") empty= open("bible_sent.txt", "w") bible = file.read() from nltk import tokenize import csv import re alphabets= "([A-Za-z])" prefixes = "(Mr|St|Mrs|Ms|Dr)[.]" suffixes = "(Inc|Ltd|Jr|Sr|Co)" starters = "(Mr|Mrs|Ms|Dr|He\s|She\s|It\s|They\s|Their\s|Our\s|We\s|But\s|However\s|That\s|This\s|Wherever)" acronyms = "([A-Z][.][A-Z][.](?:[A-Z][.])?)" websites = "[.](com|net|org|io|gov)" # final_output=[] def split_into_sentences(text): text = " " + text + " " text = text.replace("\n"," ") text = re.sub(prefixes,"\\1",text) text = re.sub(websites,"\\1",text) if "Ph.D" in text: text = text.replace("Ph.D.","PhD") text = re.sub("\s" + alphabets + "[.] "," \\1 ",text) text = re.sub(acronyms+" "+starters,"\\1 \\2",text) text = re.sub(alphabets + "[.]" + alphabets + "[.]" + alphabets + "[.]","\\1\\2\\3",text) text = re.sub(alphabets + "[.]" + alphabets + "[.]","\\1\\2",text) text = re.sub(" "+suffixes+"[.] "+starters," \\1 \\2",text) text = re.sub(" "+suffixes+"[.]"," \\1",text) text = re.sub(" " + alphabets + "[.]"," \\1",text) if "”" in text: text = text.replace(".”","”.") if "\"" in text: text = text.replace(".\"","\".") if "!" in text: text = text.replace("!\"","\"!") if "?" in text: text = text.replace("?\"","\"?") text = text.replace(".",".") text = text.replace("?","?") text = text.replace("!","!") text = text.replace("",".") sentences = text.split("") sentences = sentences[:-1] sentences = [s.strip() for s in sentences] return (sentences) # final_output.append(sentences) print(split_into_sentences(bible)) # with open('christian_forums1.csv', newline='') as csvfile: # reader = csv.reader(csvfile) # for row in reader: # for i in range(2): # if (i==1) and (row[i]!= ""): # input_txt = row[0] # # print(text) # # list_sent = tokenize.sent_tokenize(text) # # sentences.append(list_sent) # list_sent= split_into_sentences(input_txt) # final_output.append(list_sent) # list_sent = split_into_sentences(bible) # for sent in list_sent: # # print(sent) # empty.write(sent+"\n") # empty.close() # print(list_sent) |
submission = reddit.submission(pair["thread_id"]) for top_level_comment in submission.comments: if isinstance(top_level_comment, MoreComments): continue # print(top_level_comment.body) comment_body.append(top_level_comment.body) comment_body_single_str="".join(comment_body) comment_body = split_into_sentences(comment_body_single_str) # print(" ".join(comment_body)) text_model = markovify.Text(comment_body) for i in range(10): print(text_model.make_sentence()) |
Submission Data: {'thread_id': '7zg0rt', 'submission': 'Deep down, everyone likes it when someone has a crush on them right? So why not just tell people that you like them if you do? Even if they reject you, deep down they feel good about themselves right? '}
Markov Result: Great if you like it, you generally say yes, even if they have a hard time not jumping for joy.
Us guys really do love it when someone has a crush on them right?
I think it's a much more nuanced concept.
In an ideal world, yesDepends on the maturity of the art.
But many people would not recommend lying there and saying "I don't like you", they would benefit from it, but people unequipped to deal with rejection in a more positive way.
If it's not mutual, then I definitely think telling them how you feel, they may not be friends with you or ignore you, or not able to answer?
I've always been open about how I feel, and be completely honest.
In an ideal world, yesDepends on the maturity of the chance to receive a big compliment.
So while most people would argue that being honest there.
I think that in reality it's a much more nuanced examples within relationships too.
import numpy import torch import json from rel_advice import rel_advice from legal_advice import legal_advice from techsupport import techsupport from needfriend import needfriend from internetparents import internet_parents from socialskills import socialskills from advice import advice from needadvice import needadvice from final_bible_questions import bible_questions from bible_sent import bible_sentences final_pairs= open("final_pairs.txt", "w") # final_pairs_py= open("final_pairs_py.txt", "w") with open("kjv.json", "r") as read_file: bible_corpus = json.load(read_file) rqbq_data_file = open("rqbq_data.txt", "w") subreddit_questions = [rel_advice, legal_advice, techsupport, needfriend, internet_parents, socialskills, advice, needadvice] list_subreddits = ["relationship_advice", "legaladvice", "techsupport", "needafriend", "internetparents", "socialskills", "advice", "needadvice"] bible_verses=[] # for from models import InferSent V = 2 MODEL_PATH = 'encoder/infersent%s.pkl' % V params_model = {'bsize': 64, 'word_emb_dim': 300, 'enc_lstm_dim': 2048, 'pool_type': 'max', 'dpout_model': 0.0, 'version': V} print("HELLO", MODEL_PATH) infersent = InferSent(params_model) infersent.load_state_dict(torch.load(MODEL_PATH)) W2V_PATH = 'dataset/fastText/crawl-300d-2M.vec' infersent.set_w2v_path(W2V_PATH) with open("encoder/samples.txt", "r") as f: sentences = f.readlines() infersent.build_vocab_k_words(K=100000) infersent.update_vocab(bible_sentences) print("embed bible") temp_bible = bible_questions embeddings_bible = infersent.encode(temp_bible, tokenize=True) normalizer_bible = numpy.linalg.norm(embeddings_bible, axis=1) normalized_bible = embeddings_bible/normalizer_bible.reshape(1539,1) pairs = {} for question_list in range(len(subreddit_questions)): pairs[list_subreddits[question_list]]={} print("setting variables: ", list_subreddits[question_list]) temp_reddit = subreddit_questions[question_list] #TRIM THESE TO TEST SMALLER LIST SIZES print("embed", list_subreddits[question_list], "questions") embeddings_reddit = infersent.encode(temp_reddit, tokenize=True) print("embed_reddit dim: ",embeddings_reddit.shape) print("embed_bible dim: ", embeddings_bible.shape) normalizer_reddit = numpy.linalg.norm(embeddings_reddit, axis=1) print("normalizer_reddit dim: ", normalizer_reddit.shape) print("normalizer_bible dim: ", normalizer_bible.shape) temp_tuple = normalizer_reddit.shape normalized_reddit = embeddings_reddit/normalizer_reddit.reshape(temp_tuple[0],1) print("normalized_reddit dim:", normalized_reddit) print("normalized_bible dim:", normalized_bible) print("normed normalized_reddit dim: ", numpy.linalg.norm(normalized_reddit, ord=2, axis=1)) print("normed normalized_bible dim: ", numpy.linalg.norm(normalized_bible, ord=2, axis=1)) reddit_x_bible = numpy.matmul(normalized_reddit, normalized_bible.transpose()) print("reddit x bible", reddit_x_bible) matrix = reddit_x_bible.tolist() distances = [] distances_double=[] distances_index = [] bible_indeces=[] for reddit_row in matrix: closest = max(reddit_row) bible_indeces.append(reddit_row.index(closest)) distances.append(closest) distances_double.append(closest) cur_index = matrix.index(reddit_row) final_pairs.write("\n-------\n" + "distance: "+ str(closest)+"\n" +str(list_subreddits[question_list])+"\n"+subreddit_questions[question_list][cur_index]+"\n"+ bible_questions[reddit_row.index(closest)]+"\n-------\n") distances.sort() distances.reverse() for distance in distances: inde_x = distances_double.index(distance) distances_index.append(inde_x) pairs[list_subreddits[question_list]]["distances"]=distances pairs[list_subreddits[question_list]]["distances_indexer"]=distances_index pairs[list_subreddits[question_list]]["bible_question"]=bible_indeces # print(pairs) rqbq_data_file.write(str(pairs)) rqbq_data_file.close() # for pair in pairs: # # print( "\n-------\n", reddit_questions[pair],"\n", bible_questions[pairs[pair]], "\n-------\n") # # export_list.append([max_nums[counter], pair, pairs[pair], reddit_questions[pair], bible_questions[pairs[pair]]]) # counter+=1 # # final_pairs_py.write(str(export_list)) # # final_pairs_py.close() # final_pairs.close() # nums.append(closest) # max_nums.append(closest) # for distance in max_nums: # row = nums.index(distance) #matrix row # column = matrix[row].index(distance) # pairs[row]= column # pairs[list_subreddits[question_list]][closest]={} # reddit_bodies.append() # export_list = [] # nums=[] # max_nums = [] # max_nums.sort() # max_nums.reverse() # load 400 iterations # format [distance, subreddit, reddit question, bible verse, bible question] # build dictionary in loop, and keep list of min distances # final_pairs.write(str(pairs)) # counter = 0 # bible_x_reddit = numpy.matmul(embeddings_bible, reddit_trans) # print(bible_x_reddit) |
from rqbq_data import rqbq_dictionary from bibleverses import find_verse import random import csv from rel_advice import rel_advice from legal_advice import legal_advice from techsupport import techsupport from needfriend import needfriend from internetparents import internet_parents from socialskills import socialskills from advice import advice from needadvice import needadvice from final_bible_questions import bible_questions # print(len(rqbq_dictionary)) # print(rqbq_dictionary.keys()) list_subreddits = ["relationship_advice", "legaladvice", "techsupport", "needafriend", "internetparents", "socialskills", "advice", "needadvice"] subreddit_questions = [rel_advice, legal_advice, techsupport, needfriend, internet_parents, socialskills, advice, needadvice] write_csv=[] def getPage(): subreddit_index=random.randint(0,7) subreddit = list_subreddits[subreddit_index] print("subreddit: ", subreddit) length = len(rqbq_dictionary[subreddit]["distances"]) print("length: ", length) random_question = random.randint(0,500) #SPECIFY B AS CUT OFF FOR REDDIT/BIBLE ACCURACY. 1=MOST ACCURATE, LENGTH-1 = LEAST ACCURATE print("random question num: ", random_question) print("distance of random question: ", rqbq_dictionary[subreddit]["distances"][random_question]) print("index of random question: ", rqbq_dictionary[subreddit]["distances_indexer"][random_question]) index_rand_q=rqbq_dictionary[subreddit]["distances_indexer"][random_question] index_rand_q_bible = rqbq_dictionary[subreddit]["bible_question"][index_rand_q] # print(index_rand_q, index_rand_q_bible) print("question: ", subreddit_questions[subreddit_index][index_rand_q]) print("verse: ", bible_questions[index_rand_q_bible]) verse = find_verse(bible_questions[index_rand_q_bible]) write_csv.append([rqbq_dictionary[subreddit]["distances"][random_question], subreddit, subreddit_questions[subreddit_index][index_rand_q], verse, bible_questions[index_rand_q_bible]]) # getPage() for i in range(15): getPage() with open('redditxBible.csv', 'w', newline='') as f: writer = csv.writer(f) writer.writerow(["distance", "subreddit", "reddit_question", "verse", "bible_question"]) writer.writerows(write_csv) |
import json with open("kjv.json", "r") as read_file: bible_corpus = json.load(read_file) sample = " went up against the king of Assyria to the river Euphrates: and king Josiah went against him; and he slew him at Megiddo, when he had seen him." def find_verse(string): for x in bible_corpus["books"]: for chapter in x["chapters"]: # print(chapter["verses"]) for verse in chapter["verses"]: if string in verse["text"]: return (verse["name"]) |






Overall, i really enjoyed making this book. This project was super interesting in that I feel like I really had to apply more programming knowledge than previous projects in order to combine all the parts to get fully usable code. They couldn't only work disparately, they had to able to work all together too. Piping all the parts together was definitely the toughest part. I only wish I had more time to design the book, but i will probably continue working on that onwards.
by nannon & chaine
How it works:
Seated Catalog of Feelings
I came across this exhibit recently at the Cooper Hewitt, and loved how simple yet exciting this experiential piece was. It is a solo experience, yet not isolated, as the artists Eric Gunther + Sosolimited carefully show you what the user is experiencing through communicative + artful projections.

In these disembodied days, where the majority of the experiences we're tuned into happen from the neck up, I am attracted to things that remind us to listen to the world with our bodies.
This piece is not only fun + whimsical, but also smart because it relinquishes so much to the viewer. It relies on the viewers' own imagination to create for themselves in their heads the feeling of "a cricket rubbing its arms together, or "making love to a snail on a bicycle seat." With the piece's carefully crafted physical + auditory sensations, it asks the viewer to take the extra step by placing themselves in the context of a given text. The text is often ambiguous enough that the viewer needs to jump to an immediate conclusion about what the sentence means (in the case of the snail example, are you a human, snail, or the bicycle seat?)
However, what I think makes the piece go above and beyond is the consideration for creating a visualization that outside/passing participants can also see. It extends the experience just a little bit (and the viewer themselves cannot see this), so that the experience remains vague, yet enticing.
https://medium.com/sosolimited/organized-vibrations-db2c782534c6
Face Face Revolution
Vimeo
(sadly the "levels" label disappears!!)
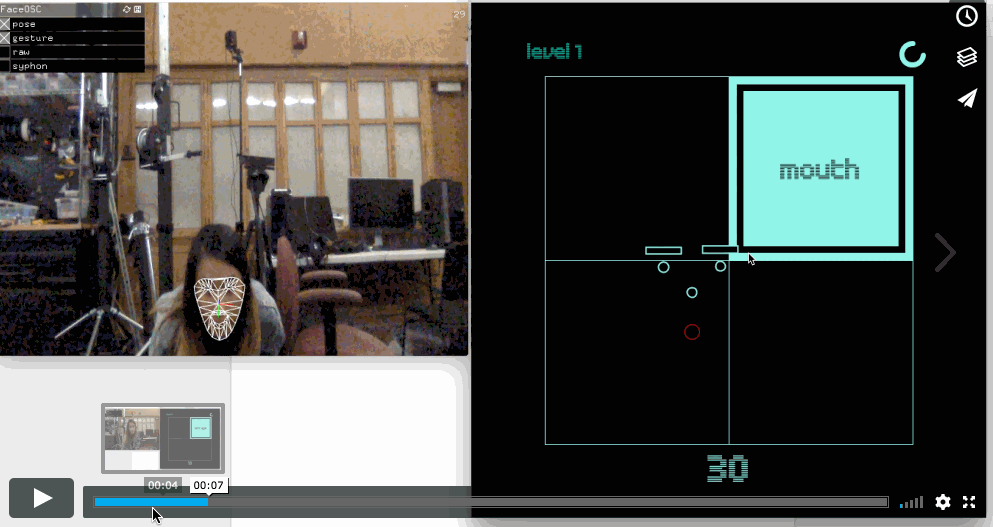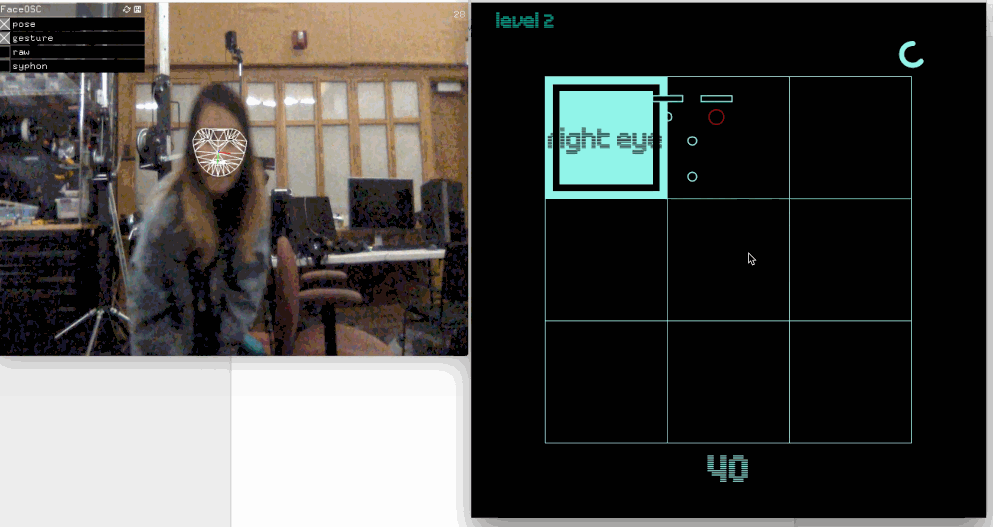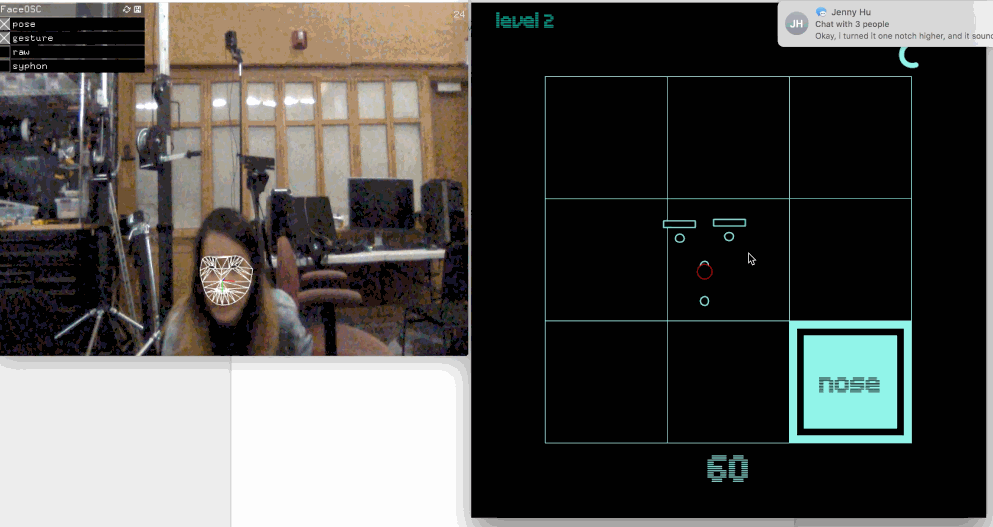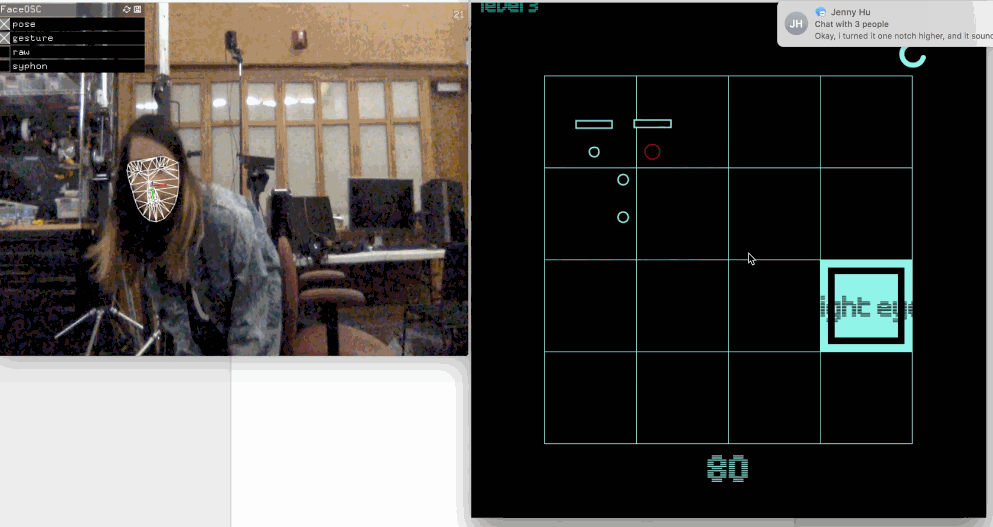
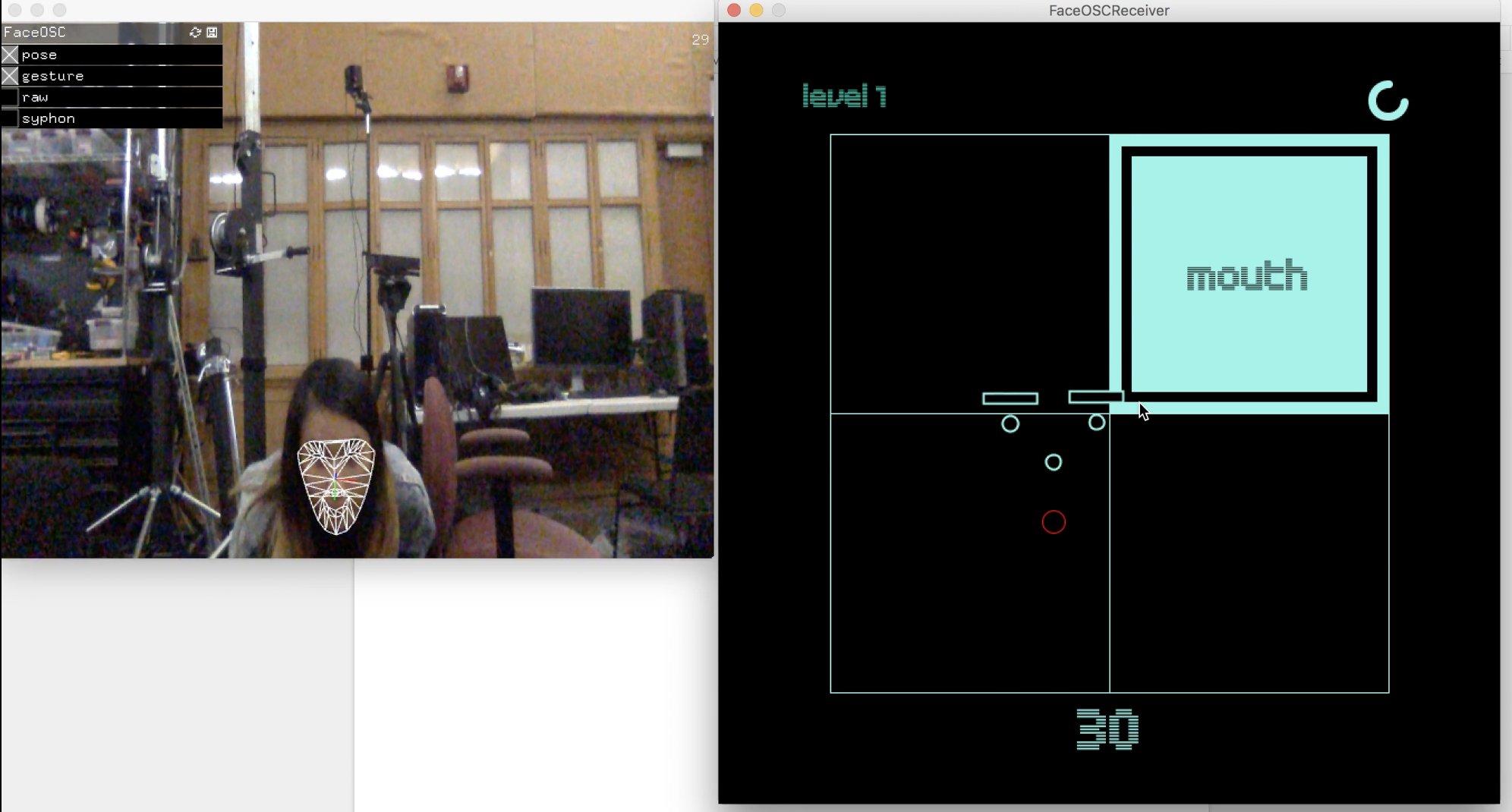
// // a template for receiving face tracking osc messages from // Kyle McDonald's FaceOSC https://github.com/kylemcdonald/ofxFaceTracker // // 2012 Dan Wilcox danomatika.com // for the IACD Spring 2012 class at the CMU School of Art // // adapted from from Greg Borenstein's 2011 example // http://www.gregborenstein.com/ // https://gist.github.com/1603230 // import oscP5.*; OscP5 oscP5; PFont intersect50; PFont intersect25; //game bools boolean pressplay =false; boolean gameOver = false; int level; // num faces found int found; // pose float poseScale; PVector posePosition = new PVector(); PVector poseOrientation = new PVector(); // gesture float mouthHeight; float mouthWidth; float eyeLeft; float eyeRight; float eyebrowLeft; float eyebrowRight; float jaw; float nostrils; //mouth, left eye, right eye, nose String[] parts = {"mouth", "left eye", "right eye","nose"}; int partsActive; // grid variables int[][] grid = new int[10][10]; int gridNum = 2; int gridSize = 700; int margin = 100; int sqSize; int randX; int randY; int points; //timer int time; int wait = 8000; float countdown; void setup() { // Uncomment the following two lines to see the available fonts //String[] fontList = PFont.list(); //printArray(fontList); //String[] fontList = PFont.list(); //for (int i =300;i<700; i++) { // println(fontList[i]); //} intersect50 = createFont("IntersectB44Solid", 120); intersect25 = createFont("IntersectB24", 30); translate(0,0); size(700,700); frameRate(30); oscP5 = new OscP5(this, 8338); oscP5.plug(this, "found", "/found"); oscP5.plug(this, "poseScale", "/pose/scale"); oscP5.plug(this, "posePosition", "/pose/position"); oscP5.plug(this, "poseOrientation", "/pose/orientation"); oscP5.plug(this, "mouthWidthReceived", "/gesture/mouth/width"); oscP5.plug(this, "mouthHeightReceived", "/gesture/mouth/height"); oscP5.plug(this, "eyeLeftReceived", "/gesture/eye/left"); oscP5.plug(this, "eyeRightReceived", "/gesture/eye/right"); oscP5.plug(this, "eyebrowLeftReceived", "/gesture/eyebrow/left"); oscP5.plug(this, "eyebrowRightReceived", "/gesture/eyebrow/right"); oscP5.plug(this, "jawReceived", "/gesture/jaw"); oscP5.plug(this, "nostrilsReceived", "/gesture/nostrils"); points = 0; getNewRand(); //timer time = millis();//store the current time println("time", time); //game level =1; partsActive = int(random(4)); } void draw() { if (!pressplay && !gameOver) { gameStart(); } else if (pressplay && !gameOver){ game(); } else if (pressplay && gameOver) { gameend(); } } void gameStart(){ background(1, 34, 160); textAlign(CENTER, CENTER); textFont(intersect50); fill(133,242,231); text("face", width/2-3,height/2-100); text("face", width/2-3, height/2); fill(0,222,190); text("face", width/2, height/2-100+3); text("face", width/2, height/2+3); textFont(intersect25); int passedMillis = millis() - time; // calculates passed milliseconds if(passedMillis >= 300){ time = millis(); fill(1, 34, 160); // if more than 215 milliseconds passed set fill color to red } else { fill (0,222,190); } text("free play", width/2, 490); if (keyPressed) { if (key=='p' || key=='P') { pressplay = true; } } } void gameend() { background(1, 34, 160); textAlign(CENTER, CENTER); textFont(intersect50); fill(133,242,231); text("game", width/2-3,height/2-100); text("over", width/2-3, height/2); fill(0,222,190); text("game", width/2, height/2-100+3); text("over", width/2, height/2+3); textFont(intersect25); int passedMillis = millis() - time; // calculates passed milliseconds if(passedMillis >= 300){ time = millis(); fill(1, 34, 160); // if more than 215 milliseconds passed set fill color to red } else { fill (0,222,190); } text("good bye", width/2, 490); if (keyPressed) { if (key=='s' || key=='S') { gameOver =false; pressplay = false; //level =0; //points =0; setup(); } } } void game() { if (points<40) { level =1; } else if (points<70) { level =2; } else if (points<100) { level =3; } else if (points<130) { level =4; } else { level =5; } pushMatrix(); background(0); translate(sqSize/2,sqSize/2); fill(0); gridNum=level+1; sqSize = (gridSize-margin*2)/gridNum; //500/3 // println(sqSize); for (int i=0; i<gridNum; i++) { for (int j=0; j<gridNum; j++) { //size/ grid size stroke(133,242,231); //noFill();222 //println(i, j, sqSize, sqSize*j+margin); rect(sqSize*j+margin, sqSize*i+margin, sqSize, sqSize); } } textFont(intersect25); fill (0,222,190); textAlign(LEFT); text("level "+str(level), -50,-50); fill(133,242,231); rect(sqSize*randX+margin, sqSize*randY+margin, sqSize, sqSize); fill(0); rect(sqSize*randX+margin, sqSize*randY+margin, sqSize-20, sqSize-20); fill(133,242,231); rect(sqSize*randX+margin, sqSize*randY+margin, sqSize-40, sqSize-40); //rect(300,300,40,40); popMatrix(); pushMatrix(); textFont(intersect25,40); textAlign(CENTER,CENTER); fill(0); text(parts[partsActive], sqSize*randX+margin+sqSize/2, sqSize*randY+margin+sqSize/2); popMatrix(); //write points count fill(133,242,231); textSize(60); //println(points); text(str(points), 350, 630); //timer if(millis() - time >= wait){ gameOver = true; //also update the stored time } else { countdown = (millis()-time); //println("wait", wait); //println("test", millis()-time); countdown = countdown/wait; //println("countdown", countdown); } //println((3*PI)/2, ((3*PI)/2)*countdown); pushMatrix(); noFill(); stroke(133,242,231); strokeWeight(7); arc(600, 70, 30,30, 3*(PI/2)*countdown, 3*(PI/2), OPEN); popMatrix(); strokeWeight(1); //translate(width,0); // scale(-1,1); //facial data if(found > 0) { pushMatrix(); translate(posePosition.x, posePosition.y); scale(poseScale); noFill(); ellipse(-20, eyeLeft * -9, 7, 7); ellipse(20, eyeRight * -9, 7, 7); ellipse(0, 20, 7, 7); ellipse(0, nostrils * -1, 7, 7); rectMode(CENTER); fill(0); rect(-20, eyebrowLeft * -5, 25, 5); rect(20, eyebrowRight * -5, 25, 5); popMatrix(); //gamify your LEFT eye float realMouthX = (posePosition.x); float realMouthY = posePosition.y+((eyeLeft*7)*poseScale); //gamify your LEFT eye float realLeftEyeX = (posePosition.x-(20*poseScale)); float realLeftEyeY = posePosition.y+((eyeLeft*-9)*poseScale); //gamify your RIGHT eye float realRightEyeX = (posePosition.x+(20*poseScale)); float realRightEyeY = posePosition.y+((eyeLeft*-9)*poseScale); //gamify your NOOOSE float realNoseX = (posePosition.x); float realNoseY = posePosition.y+((eyeLeft*-1)*poseScale); //translate(125,125); stroke(255,0,0); //MOUTH POINTS if (partsActive==0) { ellipse(realMouthX, realMouthY, 20,20); if (realMouthX >= sqSize*randX+margin && realMouthX <= sqSize*randX+sqSize+margin && realMouthY>= sqSize*randY+margin && realMouthY<= sqSize*randY+sqSize+margin) { //println("hello"); points+=10; getNewRand(); } } //LEFT EYE POINTS if (partsActive==1) { ellipse(realLeftEyeX, realLeftEyeY, 20,20); if (realLeftEyeX >= sqSize*randX+margin && realLeftEyeX <= sqSize*randX+sqSize+margin && realLeftEyeY>= sqSize*randY+margin && realLeftEyeY<= sqSize*randY+sqSize+margin) { //println("hello"); points+=10; getNewRand(); } } //RIGHT EYE POINTS if (partsActive==2) { ellipse(realRightEyeX, realRightEyeY, 20,20); if (realRightEyeX >= sqSize*randX+margin && realRightEyeX <= sqSize*randX+sqSize+margin && realRightEyeY>= sqSize*randY+margin && realRightEyeY<= sqSize*randY+sqSize+margin) { //println("hello"); points+=10; getNewRand(); } } if (partsActive==3) { ellipse(realNoseX, realNoseY, 20,20); if (realNoseX >= sqSize*randX+margin && realNoseX <= sqSize*randX+sqSize+margin && realNoseY>= sqSize*randY+margin && realNoseY<= sqSize*randY+sqSize+margin) { //println("hello"); points+=10; getNewRand(); } } } } void getNewRand() { randX = int(random(0,gridNum)); randY = int(random(0,gridNum)); partsActive = int(random(4)); time = millis(); } void mouseClicked() { randX = int(random(0,gridNum)); randY = int(random(0,gridNum)); partsActive = int(random(4)); time = millis(); } // OSC CALLBACK FUNCTIONS public void found(int i) { //println("found: " + i); found = i; } public void poseScale(float s) { //println("scale: " + s); poseScale = s; } public void posePosition(float x, float y) { //println("pose position\tX: " + x + " Y: " + y ); posePosition.set(x, y, 0); } public void poseOrientation(float x, float y, float z) { //println("pose orientation\tX: " + x + " Y: " + y + " Z: " + z); poseOrientation.set(x, y, z); } public void mouthWidthReceived(float w) { //println("mouth Width: " + w); mouthWidth = w; } public void mouthHeightReceived(float h) { //println("mouth height: " + h); mouthHeight = h; } public void eyeLeftReceived(float f) { //println("eye left: " + f); eyeLeft = f; } public void eyeRightReceived(float f) { //println("eye right: " + f); eyeRight = f; } public void eyebrowLeftReceived(float f) { //println("eyebrow left: " + f); eyebrowLeft = f; } public void eyebrowRightReceived(float f) { //println("eyebrow right: " + f); eyebrowRight = f; } public void jawReceived(float f) { //println("jaw: " + f); jaw = f; } public void nostrilsReceived(float f) { //println("nostrils: " + f); nostrils = f; } // all other OSC messages end up here void oscEvent(OscMessage m) { if(m.isPlugged() == false) { println("UNPLUGGED: " + m); } } |
Spectacle is most easily recognized in works that milk the most out of current technology--it's usually flashy, engaging, easy to understand, for capital gain.
Speculation pushes the edge of understanding + technology--it is not self conscious, can also be flashy, but also confusing, uncomfortable, in the midst of coming to terms with itself.
Trimalchio, AES+F, 2010

AES+F is an art collective that plays a lot of faux realistic 3D through 3D modeling and photo manipulation. This particular piece, Trimalchio, was made in 2010. It's hard to categorize this as either speculation or spectacle because I think it's so much both (maybe it does reclaim spectacle into speculation). At first glance, the aesthetic is very beautiful, with many references to renaissance/greek god type imagery. But as you watch the videos, the references to all kinds of humanity + culture come out of nowhere, seamlessly blending into this utopic world. I think AES+F uses 3D in an interesting way because it's not the tip top frontier of 3D imaging, yet the blend of photo+manipulation makes it look extremely real. It's the photography that brings it out of uncanny valley, and the very intentional play with scale, imagery, and context that bring it into the weird, which I think is awesome.
At first thought, I want to say that my interests lie with last word art. There's something extremely daunting about making something that radically transforming from a medium or concept that most people already take for granted. At the same time, people around me are often very first-word oriented; looking at my recent work for this class, I believe that I've been drawn into the first-word realm of things.
Technology has shaped culture at almost every step of the way--of course, the obvious examples are things such as agriculture, industrial revolution, the internet, etc. But something I think that is very interesting happening in our culture today is the way the internet has shaped very different cultures in the West and in China. Technology today being tied up largely in software has also widened an intellectual + educational gap, exacerbating existing income/wage/socioeconomic gaps. On the flip side, I think small sub cultures can drive technologies as well. For example, niche music and art tech is drive by those who need it and make the case and perhaps build it.
The phrase technologically novel immediately brings to mind countless examples that exist in today's world. AR/VR, blockchain, etc are examples of technologies that people are working immensely hard to try to find uses for, but 99% of what's made/exists will not be remembered beyond the year its made. However, I do think that this kind of research will influence the 1% of products that are the last word, and that the last word wouldn't have existed without the first word. In addition, obsoletism has never been more pervasive than today, and software changes so fast that the foundational value of products can't be based purely on its technology. I think last word stuff is not only technologically novel, but also conceptually, philosophically, and aesthetically challenging.




(Different possibilities of chairs)
Sept 28: I wanted this chat room to be a literal room where users could move around and chat with each other. However, one of the biggest obstacles was getting the images to load correctly. In addition, I had a lot of trouble keeping track of who was in the room--as such, when a new user joins a room, they won't see people who arrived previously, but users can see new people joining the room live. To be continued.
I wanted this chat room to be a literal room where users could move around and chat with each other. However, one of the biggest obstacles was getting the images to load correctly. In addition, I had a lot of trouble keeping track of who was in the room--as such, when a new user joins a room, they won't see people who arrived previously, but users can see new people joining the room live. To be continued.
Oct 2 Update:
The chat works! Used the agar.io template as a base, instead of the drawing template. Helped a lot, since I realized the agar.io template solved all my previous problems with users showing up. The hardest part was learning how it worked, and understanding the socket code. Will be adding new chairs (currently only 3), and a prettier log in page, including explanations for each chair) soon.