doodle-place
Check it out at https://doodle-place.glitch.me
doodle-place is an online world inhabited by user-submitted, computationally-animated doodles. You can wander around and view doodles created by users around the globe, or contribute your own.
Process
To make this project, I first made a software that automatically rigs and animates any doodle made by users. It does so using some computer vision. Then I wrote server-side and client-side software to make the world and the database behind it running. The process is explained below.
doodle-rig
Skeletonization
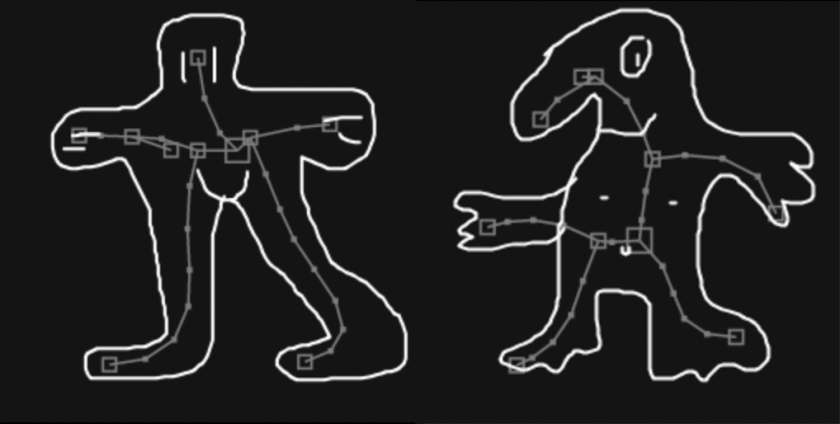
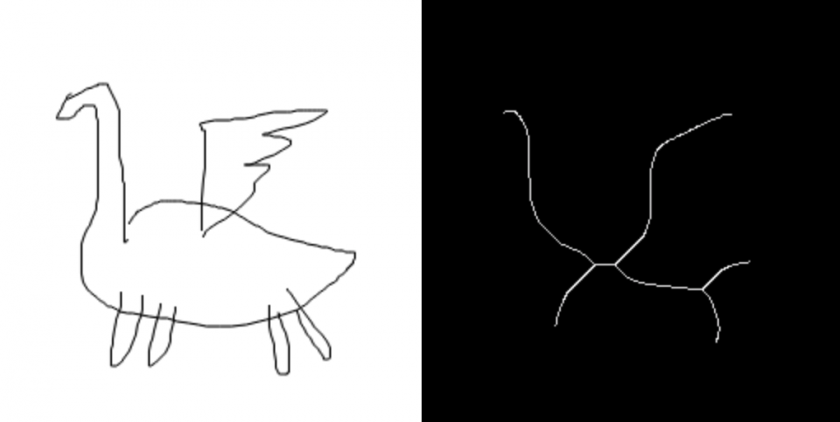
To rig/animate a doodle, I first need to guess the skeleton of it. Luckily, there’s something called “skeletonization” that does just that. Thanks to Kyle McDonald for telling me about it one day.
The idea of skeletonization is to make the foreground thinner and thinner until it’s 1px thick.
At first I found a OpenCV implementation, but it was quite bad because the lines are broken at places. Then I found a good implementation in C++. I ported it to javascript. However it runs very slow in the browser, because it iterates through every pixel in the image multiple times and modifies them. However, I discovered gpu.js, which can compile kernels written using a subset of javascript into WebGL shaders. So I rewrote the skeletonization algorithm with gpu.js
The source code and demo can be found at:
https://skeletonization-js.glitch.me
You can also import it as a javascript library to use in whatever js project, which is what I’m doing for this project.
Inferring rigs
Since the skeletonization is a raster operation, there is still the problem on how to make sense of the result. We humans can obviously see the skeleton meant by a resultant image, but for computers to understand I wrote something that extracts it.
The basic idea is that I scan the whole image with a 8×8 window for non-empty patches, and I mark the first one I found as root.
I check all 4 edges of the root patch, and see which of the 8 directions have outgoing lines. I’ll follow these lines and mark the patches they point to as children. Then I do this recursively to extract the whole tree.
Afterwards, an aggressive median-blur filter is applied to remove all the noise.
The source code and demo can be found at:
https://doodle-rig.glitch.me
Again, this can be used as a library, which is what I did for this project.

Inferring limbs & Animation
I made 5 categories for doodles: mammal-oid, humanoid, bird-oid, fish-oid, and plant-oid. For each of them, I have a heuristic that looks at the shape of skeleton and decide which parts are legs, arms, heads, wings, etc. Though it works reasonably well on most doodles, the method is of course not perfect (because it doesn’t use machine learning). But since the doodle can be anything (the user might submit say a banana as a humanoid, in which case no method will be correct in telling which parts are legs), I embraced the errors as something playful.
Then I deduced separate animation for different limbs. For example a leg should move rapidly and violently when walking, but a head might just bob around a little bit. I also tried just totally random animation, and I almost liked insane randomness better. I’m still working on the sane version.
Database & Storage
Structure
I use SQLite to store the doodles. This is my first time using SQL. I find learning it interesting. Here is a sqlite sandbox I made to teach myself:
https://ld-sql-lab.glitch.me
Anything you post there will be there forever for everyone to see…
But back to this project, I encode the strokes and structure of each submitted doodle into a string, and insert it as a row along with other meta data:
- uuid: Generated by the server, universally unique identifier to identify the doodle.
- userid: The name/signature of a certain user to put on their doodles, doesn’t need to be unique
- timestamp: time at which the doodle is created, also contains the time zone information, which is used to estimate the continent where the user is on without tracking them.
- doodlename: The name of the doodle given by user
- doodledata: strokes and structural data of the doodle.
- appropriate: whether the doodle contains inappropriate imagery. All doodles are born as appropriate, and I’ll check the database periodically to mark inappropriate ones.

Management
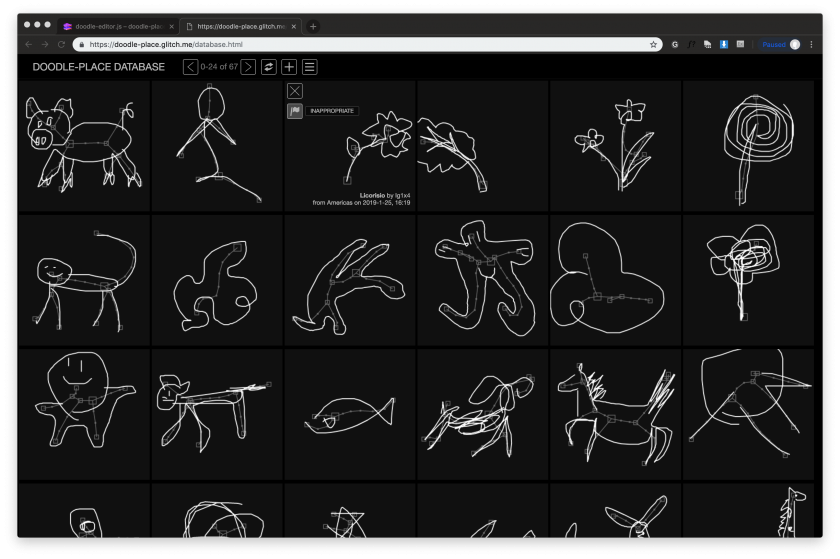
I made a separate page (https://doodle-place.glitch.me/database.html) to view and moderate the database. Regular users can also browse that page and see all doodles aligned in a big table, but they won’t have the password to flag or delete doodles.
Golan warned me that the database is going to be full of penises and swastikas. I decided that instead of deleting them, I’ll keep them but also flag them as inappropriate so they will not spawn. When I’ve collected enough of these inappropriate doodles, I’ll create a separate world so all these condemned doodles can live together in a new home, while the current world will be very appropriate all the time.
Engine
GUI
The default HTML buttons and widgets looks very generic, so I wrote my own “skin” for the GUI using JS and CSS.
Turns out that modern CSS support variables which can be programmatically set with JS. This recent discovery made my life a lot easier.
I created an entire set of SVG icons for the project. I used to use Google’s Material Icon font, but it turns out that what I need this time is too exotic.
Making the doodle editor GUI was more time-consuming than writing actual logic / developing algorithms.

3D
At first I thought I could get away with P5.js 3D rendering. Turns out to be slow as crawl. After switching to three.js, everything is fast. I wonder why, since they both use WebGL.
The lines are all 1px thick because of Chrome/Firefox WebGL implementation doesn’t support line width. I would be happier if they can be 2px so things look more visible, but I thick currently it’s fine. Workaround such as to render lines as “strip of triangles” is way too slow.
Terrain

I’ve generated a lot of terrains in my life so generating this one isn’t particularly hard. But in the future I might give it more care to make it look even better. Currently it is a 2D gaussian function multiplied with a perlin noise. This way the middle part of the terrain will be relatively high, with all the far-away parts having 0 height. The idea is that the terrain is an island surrounded by waters, so the players can’t just wander off the edge of the world.
The plant-oids will have a fixed place on land, the humanoids and mammal-oids will be running around on land, the bird-oids will be flying around everywhere, and the fish will be swimming in the waters around the island.
The terrain is generated by the server as a height map. The height map is a fixed-size array, with the size being its resolution. The y coordinate of anything on top of the terrain is calculated from its x and z coordinates, and non-integer positions are calculated using bilinear-interpolation. This way mesh collision and physics stuff are avoided.
Initially I planned to have the terrain look just like a wireframe mesh. Golan urged me to think more about it, such as outlining the hills instead so the look will be more consistent with doodles. I implemented this by sampling several parallel lines on the height map normal to the camera’s direction. It’s quick, but it sometimes misses out the top of the hills. So I still kept the wireframe as a hint. In the future I might figure out a fast way, perhaps with some modified toon shader to draw exactly the outline.
Control
The user can control the camera’s rotation on y axis. The other two rotations are inferred by the terrain beneath the user’s feet, with some heuristics. There’s also a ray-caster that acts like a cursor, which determines where new user-created doodles will be placed. The three.js built-in ray caster on meshes is very slow, since I have really really big mesh that is the terrain. However since terrains are not just any mesh and have very special geometric qualities, I wrote my own simple ray caster based on these qualities.
I want the experience to be playable on desktop and mobile devices. So I also made a touch-input gamepad and drag-the-screen-with-finger-to-rotate-camera.
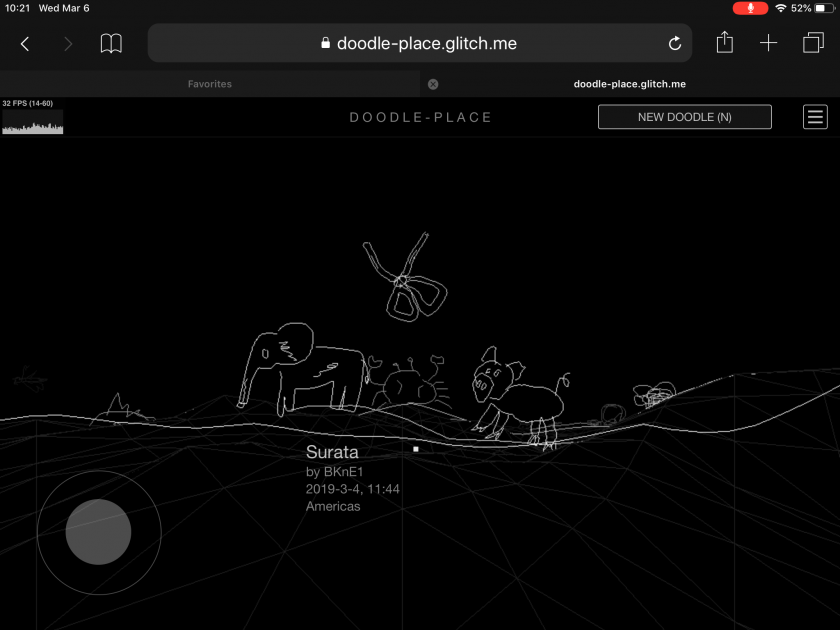
^ On iPad

^ On iPhone
Libraries:
- three.js
- OpenCV.js
- gpu.js
- node.js
- sqlite
- socket.io
- express
Evaluation
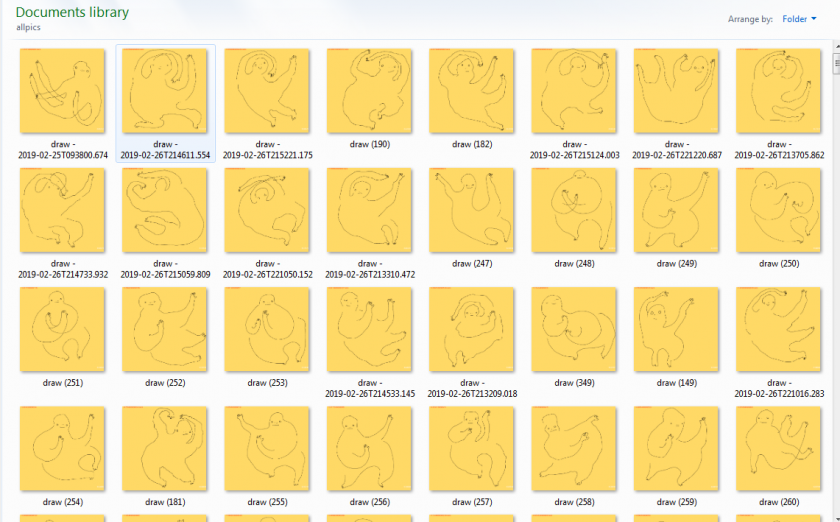
I like the result. However I think there are still bugs to fix and features to add. Currently there are ~70 doodles in the database, which is very few, and I’ll need to see how well my app will perform when there are many more.
Some more doodles in the database, possibly by Golan: