in progress
Category: Projects
gray-mask
Facial mapping to song stem control
Jackajackalope-DrawingSoftware
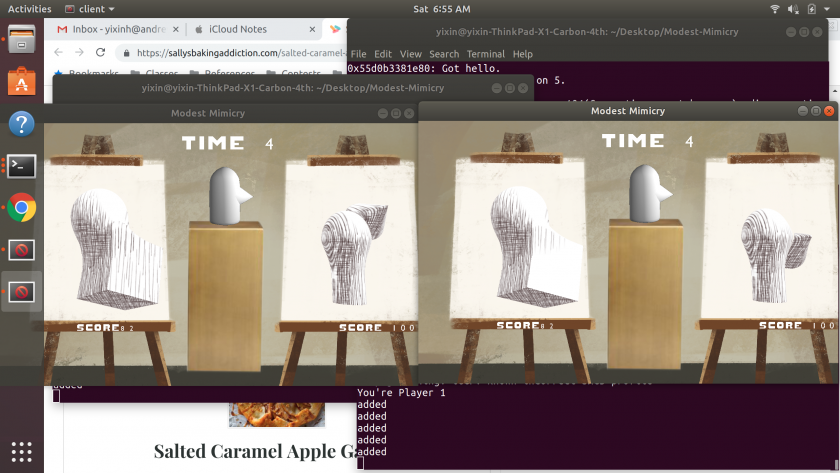
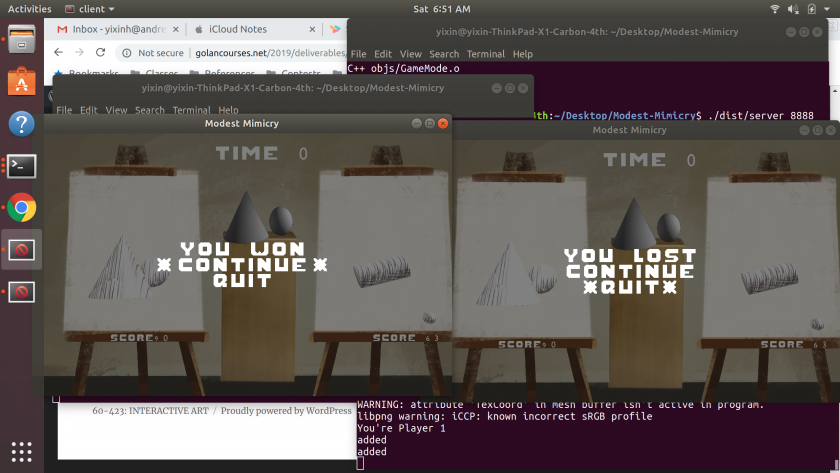
 (This nose was from earlier, before I implemented scoring and timer)
(This nose was from earlier, before I implemented scoring and timer)
I was thinking about a combination of Sloppy Forgeries and the importance of thinking about how simple shapes make up more complex forms when making paintings with dimensionality. I wanted to make this game so that people could learn to think about that kind of thing so in some ways I wanted this to be a “Learning to Draw Software” as well as a “Drawing Software”.
Disaster struck nearish to the official deadline of the project in the form of realizing that what I set out to make this project in (Three.js) was a billion times too slow for the updates and calculations raymarching required. So here I am now, 17 days late turning this in.
Overall I’m pretty proud of this. I learned a lot; I implemented a raymarching shader (by implement I mean shamelessly stole from Íñigo Quílez), added some real-time hatching (again shamelessly stolen, this time from Jaume Sanchez Elias’s implementation of the Microsoft Research paper), and learned more about OpenGL (such as the very useful glGetTexImage). I’m also happy that I pushed through and finished this for my own sake.
Things that still need improvement: polish continues to be a struggle for my impatience. There’s no music or sound effects currently. UI remains my greatest enemy. The overall aesthetic could definitely be improved and made more unified. The comparison algorithm is hacky at best. Finally, the code is a mess with no added comments and old, completely irrelevant comments left in. That’ll have to wait until some other day though.
Here’s some initial planning

tli-DrawingSoftware

My project for the drawing software assignment is a DDR-inspired drawing game. A cursor moves at a constant rate on a canvas. You must hit D (left), F (down), J (up), K (right) or SPACE (draw/stop) according to the arrow prompts in order to direct the cursor and draw an image. I prototyped this idea in Unity.
My conceptual starting point was agency in drawing. I thought about paint-by-numbers, trace-the-line games–activities that simulate drawing without any of the creativity and decision-making associated with drawing. I also thought about the distinction between art and craft, which is a tension I am very familiar with as someone who is more of a maker than a creator. I was reminded of instruction-based games like Dance Dance Revolution and typing games, which lead to a natural connection to chain codes in vector drawings. After switching back and forth between project ideas that only frustrated me, I settled on my final idea: a DDR-inspired drawing game.
As I developed the prototype, I became excited about unexpected conditions that the DDR system enforced. The importance of timing in rhythm games translated to the importance of proportions and length with contour drawing. The sequential nature of the instruction prompts forces mistakes to stack–one missed draw/stop prompt can invert the drawn lines and the travel lines for the rest of the level. Additionally, I chose to implement diagonal movement as hitting two arrows at the same time. If these two arrows are not hit simultaneously, the cursor will travel in the direction of the last arrow hit instead of the resulting diagonal.
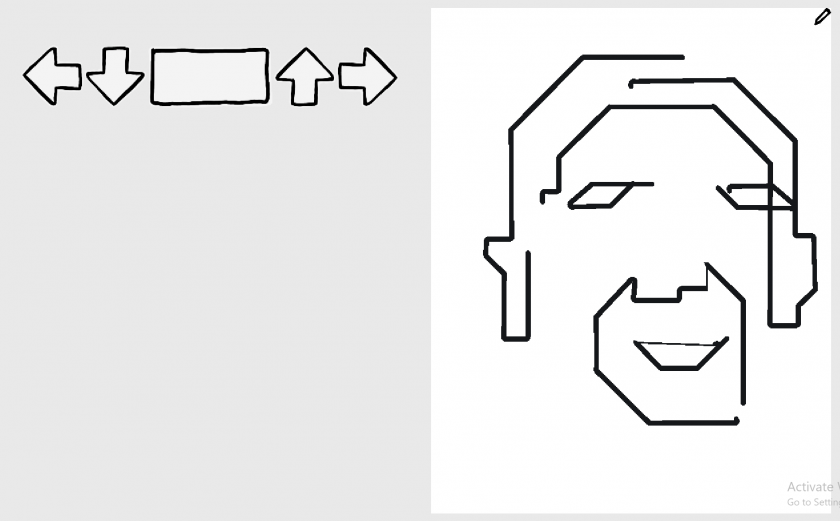
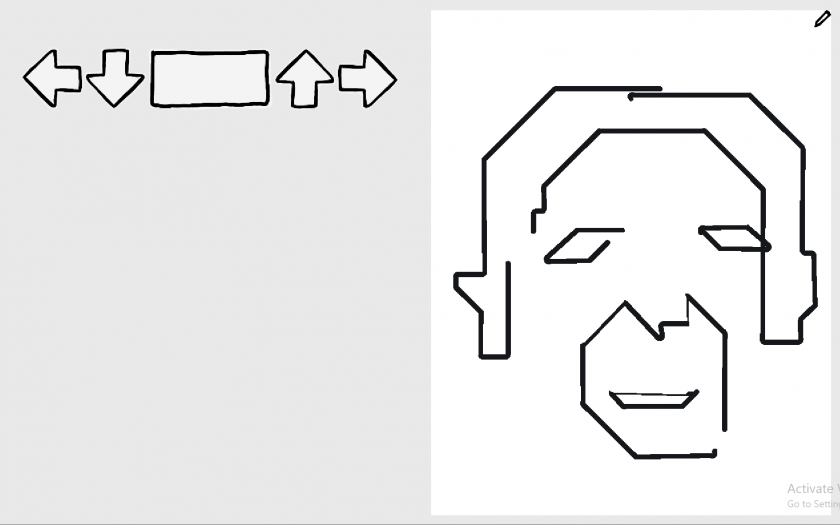
These gameplay conditions that arise from just a rough reimplementation of DDR mechanics are already exciting, so I hope to expand this project either as a personal undertaking or as a capstone in the future. I hope to open this idea to sharing, collaboration and multiplayer play. My primary goal would be to create an interactive level-builder tool in order to allow people to create their own drawing sequences and share them. I also hope to explore paint-fill combo mechanics and utilizing non-Cartesian mappings.
a & conye — DrawingSoftware
For this project, I collaborated with a, and our documentation can be found here: https://ems.andrew.cmu.edu/2019/a/03/06/conye-a-drawingsoftware/
conye & a — DrawingSoftware
Mldraw from aman tiwari on Vimeo.
origin
Mldraw was born out of seeing the potential of the body of research done using pix2pix to turn drawings into other images and the severe lack of a usable, “useful” and accessible tool to utilize this technology.
interface
Mldraw’s interface is inspired by cute, techy/anti-techy retro aesthetics, such as the work of Sailor Mercury and the Bubblesort Zines. We wanted it to be fun, novel, exciting and deeply differentiated from the world of arxiv papers and programmer-art. We felt like we were building the tool for an audience who would be appreciative of this aesthetic, and hopefully scare away people who are not open to it.
dream
Our dream is for Mldraw to be the easiest tool for a researcher to integrate their work into. We would love to see more models put into Mldraw.
future
We want to deploy Mldraw to a publicly accessible website as soon as possible, potentially on http://glitch.me or http://mldraw.com. We would like to add a mascot-based tutorial (see below for sketch of mascot). In addition, it would be useful for the part of the Typescript frontend that communicates with the backend server to be split out into its own package, as it is already independent of the UI implementation. This would allow, for instance, p5 sketches to be mldrawn.
process & implementation
Mldraw is implemented as a Typescript frontend using choo.js as a UI framework, with a Python registry server and a Python adapter library, along with a number of instantiations of the adapter library for specific models.
The frontend communicates with the registry server using socket.io, which then passes to the frontend a list of models and their URLs. The frontend then communicates directly to the models. This enables us e.g. to host a registry server for Mldraw without having to pay the cost of hosting every model it supports.
Mldraw also supports models that run locally on the client (in the above video, the cat, Pikachu and bag models run locally, whilst the other models are hosted on remote servers).
In service of the above desire to make Mldraw extensible, we have made it easy to add a new model – all that is required is some Python interface* to the model, and to define a function that takes in an image and returns an image. Our model adapter will handle the rest of it, including registering the model with the server hosting an Mldraw interface.
*This is not actually necessary. Any language that has a socket.io library can be Mldrawn, but they would have to write the part that talks to the registry server and parses the messages themselves
process images
The first image made with Mldraw. Note that this is with the “shoe” model.

The first sketch of the desired interface.

The first implementation of the real interface, with some debug views.

The first implementation of a better interface.

The first test with multiple models, after the new UI had been implemented (we had to wait for the selector to choose models to be implemented first).


The current Mldraw interface.

Our future tutorial mascot, with IK’d arm.

Some creations from Mldraw, in chronological order.






geebo-DrawingSoftware
The aim of this project is to leverage a surprisingly available technology, the Wacom tablet, in order to change one’s perspective on drawing. By placing you’re view right at the tip of the pen, mirroring your every tiny hand gesture, scale changes meaning and drawing becomes a lot more visceral.
Part of this is every micro movement of your hand (precision limited by the wacom tablet) becoming magnified to alter the pose of your camera. Furthermore, having such a direct, scaled connection between your hand and your POV allows you to do interesting things with where your looking.


Technical Implementation
I wrote a processing application that uses the tablet library to read the wacom’s data as you draw. From there, it also records the most precise version of your drawing to the canvas as well as sends the pen’s pose data to the VR headset over OSC.
Note: One thing that the wacom cannot send right now is the pen’s rotation, or absolute heading. However, the wacom art pen can enable this capabilities with one line of code.
The VR app interprets the OSC messages and poses a camera accordingly. The Unity app also has a drawing canvas inside as well, and your drawing is mirrored to that canvas through the pen position + pen down signals. This section is still a work in progress, as I only found too late (and after much experimentation) that it’s much easier to smooth the cursors path in screen space and then project it onto the mesh.
The sound was done using granulation of pre recorded audio of pens and pencils writing in Unity3D. This causes some performance issues on Android and I may have to look into scaling this back.
sjang-DrawingSoftware
CHIMERA MACHINE EXPERIMENTS
(work-in-progress)

Sample Results



Process: Ideations & Explorations

Throughout history, human beings have been fascinated by imaginary, hybrid creatures, which appear in myriad forms in many different cultures. My initial idea was to enable people to merge different parts of human and animal anatomical features, but via the expressive drawings of stick figures.
My approach involved applying different color brushes to represent different animals, and combining different color strokes to give form to wildly divergent hybrid animals that stimulate our imagination.
Concept Development



MY FIRST FORAY INTO MACHINE LEARNING..
I decided to use Christopher Hesse’s Pix2Pix tensorflow build to train and test a new GAN model specifically designed for chimera creations. It was a great opportunity to become familiar with creatively working and experimenting with ML, including its quirks. Understanding how the training process works in terms of the code was quite a learning curve. Setting up the right environment to run super-long, GPU-intensive tasks was not a straightforward process at all. Every different version of Pix2Pix had its own specific library and version dependencies for python, CUDA toolkit and cuDNN, so there was much trial and error involved in finding compatible, functioning versions to get everything reliably working (as in not crashing every 30 minutes or so).
Dataset Collection & Manipulation


The dataset I ultimately chose for training was the KTH-ANIMALS dataset, which included approximately 1,500 images of a wide variety of animals (19 different classifications) with the foreground and background regions manually segmented. At first I thought the segmentation data was missing, since I could only see a stream of black png images; it turned out that the creator of the dataset just had a matrix for each mask and saved it in the form of pngs. I had to batch process the files to identify the different pixels (I had to identify the number of unique pixel values to determine the number of masks in the image and the background pixel value, which was most frequently (2,2,2) for images with one animal, (3,3,3) for two animals.)
Data selection was pretty tricky and challenging, because there were not a lot of datasets out there that were suitable for my purposes. I narrowed my search from (specific) animals and humans to just (general) animals, especially since it was difficult to find datasets of nude human beings that were not pornographic. There were no animal datasets I could find with pose or skeleton estimations; the only thing that came closest was research on the pose estimation of animals through deep learning, which consisted of training models to recognize certain parts of the animal’s anatomy by manually marking those parts in selective video frames (DeepLabCut, LEAP). I decided to try experimenting with masks instead of detailed annotated skeletons as a proof of concept.
Since the workable size for pix2pix was constricted to 256×256, the auto-cropping unfortunately cropped much important information from the imagery, such as the head and hind areas. I spent quite some time trying to implement seam carving (context-aware cropping) and replicate the same cropping method for both images and masks, but failed to find convenient ways of achieving this without a deeper understanding to substantially edit the code (I do plan to look deeper into it when I get the chance). I also looked into Facebook’s Detectron object recognition algorithm to automate the mask creation for photos that do not come with masks, for higher quality training data curation in the future.
Training Process
Training was set at 200 max epochs, on an i7 Windows 10 desktop computer with a Nvidia GeForce GTX 1060 GPU. The Pix2Pix-tensorflow version used for training was proven compatible and stable with python 3 + CUDA 10.0 + cuDNN 7.4 + tensorflow-gpu 1.13.1. (As of the timing of this post, the tf-nightly-gpu is too unstable and CUDA 10.1 is incompatible with cuDNN 7.5). Whereas training with tensorflow (CPU version) took 12+ hours to reach only 30 epochs, training for 200+ epochs on a CUDA-enabled GPU took less than 12 hours on the same desktop.
I edited the code to export the model into a pict format on CoLab, since the code was flagged as malicious on every computer I tried running it on.
input output target input output target



Discussion
Pix2Pix is good at recognizing certain stylistic features of animals, but not so great at differentiating specific features, such as the face. You can see how it often obliterates any facial features when reconstructing animal figures from masks in tests. To isolate features, I believe it would be more beneficial to train the model on detailed annotations of pose estimations that differentiate parts of the anatomy. It would be good to train on model on where the arms begin for instance, and where it ends to see if it can learn how to draw paws or horse hoofs. This approach might also enable the drawer to combine figures with detailed human anatomical parts such as our hands and fingers. I would have to experiment with human poses first (face, general pose, hand poses etc.) to see how robustly this approach works.
The way Pix2Pix works constrains the learning to a specific size, which can be immensely frustrating, since datasets rarely contain just one uniform size, and cropping photographs of animals often sacrifices important details of the animal structure as a whole.
The reconstruction of the background imagery is interesting. I didn’t isolate eliminate the background to train the model, so it applies a hybrid approach to the background as well. I didn’t differentiate one mask from another in the instance of multiple masks in one image, half hoping this might actually help the model combine many of the same creatures at once. I’ll have to compare this model with a model that is trained to differentiate the masks, and see how the results differ.
Ideas for Expansion
I would like to continue experimenting with different approaches of creating hybrids to fully explore the type of imagery each method is capable of creating. (CycleGAN, for example, might be useful for creating wings, horns, etc. from skeletal lines to augment features.) I want to curate my own high-quality animal dataset with context-aware cropping. I also want to play with image selections and filtering, and see if I could train a machine to create images that look more like drawings or sketches.
I would love to build a less rigid interface that allows more expressive gestural strokes, with controllable brush size and physically augmented options such as Dynadraw-type filtering. I would also want to play with combining human (nude) figures with animals, as well as with mechanical objects. I think it would be interesting to explore how GAN could be used to create interesting human-machine hybrids. Would it produce hallucinogenic imagery that only machines are capable of dreaming and bringing into being? Using pose estimations would also allow me to explore a more refined approach to intelligently and deliberately combining specific parts of animals and human beings, which may prove useful for creating particular types of imagery such as those of centaurs.
sheep – drawing software
 Antispace
Antispace
Link: https://perebite.itch.io/antispace-prototype
This project was made in Unity, initially inspired by Snake, Starseed Pilgrim, and Shift.



I worked with Unity’s tile engine. I was interested in trying to make a game out of the concept of building negative and positive space in an environment. Eventually, it was Ho Chi’s suggestion to scale down the playing field that made me reconsider what scale meant to the game.
In a sense, the game could also be interesting on a large scale. Due to missteps on my part prototypes on a larger scale are lost, but they were enjoyable so I’d like to go back and try scaling up. I ran into a lot of problems when I tried to get the crawling mechanic working. 2D platformers get complicated if characters can run and jump all over the walls. I identified two main problems: walls and ledges. Cliffs were easy to manage. I used Unity’s ridgidbody system and made a custom gravity script, which rather than pull in a global down, it pulls in the local down. Teetering off the side of a cliff will stick it to the side of it, rather than careen off it. However, climbing walls was more difficult. Eventually, I used a grid based system to look for corners, and used raycasting to check if i was close enough to a corner while also standing on a floor. I checked for all cases and if I was in such a position, I would rotate up. However, this lead to movement bugs. I instead decided to go for a constant speed for my own sanity moving in a single direction. Right now, you can only go left. In the future, the choice could be left or right. Personally, I like the idea of a one button controller. But I think one can get more nuance with more movement too.
I checked for all cases and if I was in such a position, I would rotate up. However, this lead to movement bugs. I instead decided to go for a constant speed for my own sanity moving in a single direction. Right now, you can only go left. In the future, the choice could be left or right. Personally, I like the idea of a one button controller. But I think one can get more nuance with more movement too.
In the end, my project came out of abstract squares very quickly. I decided on the Space Ant heroine in an exhausted state. I think the idea of making Anti Space trails is pretty cool, and I think this could also be interesting if I ever tried to do this on a larger scale (multiple puzzles).


Demo:
jamodei-DrawingSoftware
Exploring Depth Capture Collage Tools
Collages Created:


The aim of this project is to activate the depth camera now included in new iPhones, and turn it into a tool to collage everyday life – to be able to draw a circle around a segment of reality and let the drippy point clouds be captured for later reconcatenation in a 3D/AR type space. This turned out to be quite a challenging process, and it is still ongoing. At this point, I have pieces of three different sketches running, and I am working to house everything under one application. I spent a lot of time in my research phase doing Swift tutorials so that I could get these developer sketches running. I am continuing this research as I move towards making my own app by combining and piping together the pieces of all of the research featured in this post.
In the video ‘Point Cloud Streamer Example,’ you can see an example of the live streaming point cloud capture that I am striving to implement. This was the piece of research that first set me down this path. This Apple developer sketch has by far the best detail of any of the depth cameras wrap-ups that I have seen, and is of the fidelity that I want to use in the final app.
In the video ‘Depth Capture Background Removal Example,’ you can see another developer sketch that uses the depth camera to remove the background and offer the viewer the chance to replace it with a picture of their choice – a sort of live green-screening via depth effect. In the final version of the app, I hope to give the user the freedom to scale the ‘Z’ value and select how much depth (meaning distance from the lens to the back of the visible frame) they want to maintain in the captured selection, for later collage.
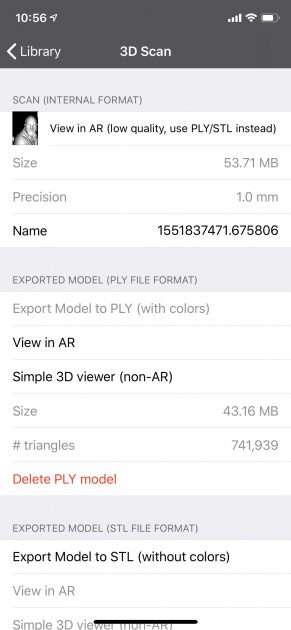
Finally, I found an app called ‘Heges’ that possesses an onboard depth camera capture apparatus. It captures depth in a proprietary format, and then allows users the option to export the depth data into .PLY sketches. This is what I used to make my collages, and to mock up the type of space I hope to manipulate in a final version for 3D creation. I had to use MeshLab to open the .PLY files, and then I rotated and adjusted them before exporting stills that I collaged in Photoshop. This app was pretty effective, but the range of its depth capture was less extensive than what seemed available in the ‘Point Cloud Streamer Example.’ It does have built-in 3D and AR viewports which are also a plus and I will try to eventually incorporate such viewports into my depth capture tool.
Point Cloud Streamer Example
Depth Capture Background Removal Example
Heges Application Documentation