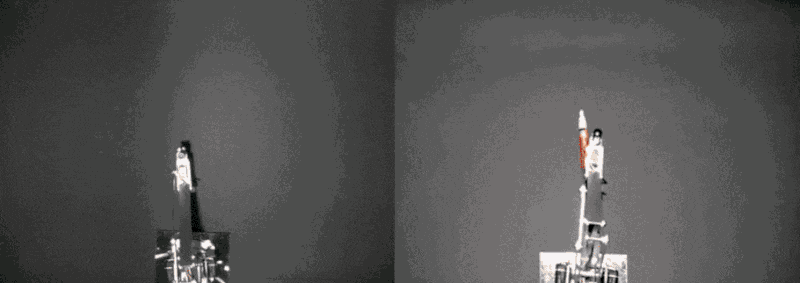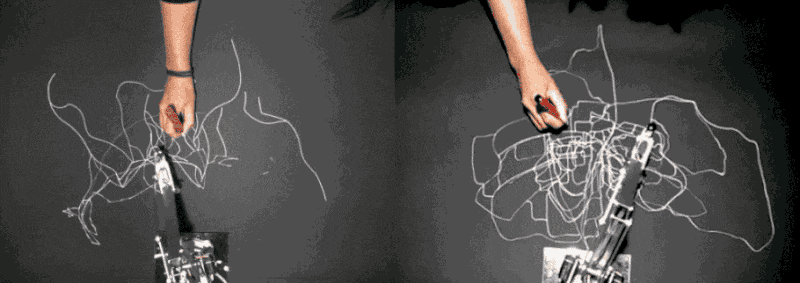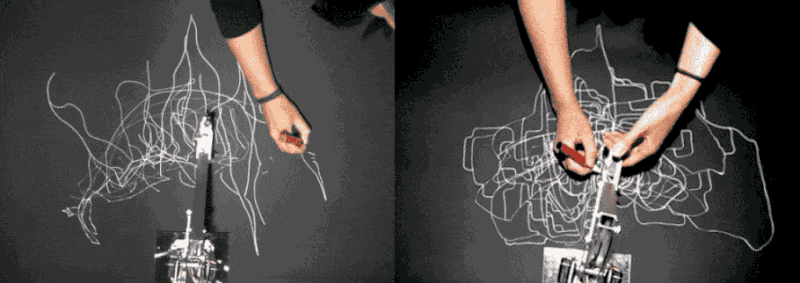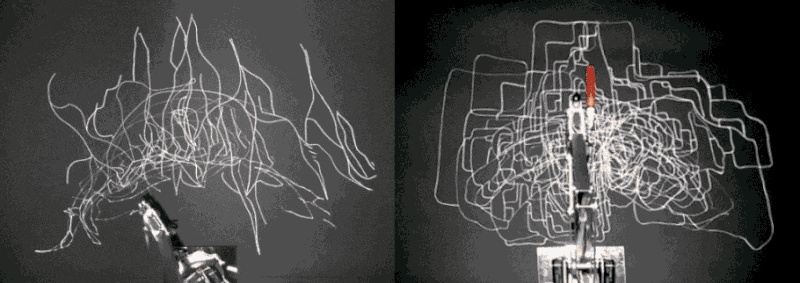I plan to build a system that allows anyone to create their own constellations in virtual reality (VR), and easily save and share their creations with other people. Users would be able to select stars from an interactive 3D star map of our Galaxy that consists of the 2,000 brightest stars in the Hipparcos Catalog, and connect any of the stars together to form a unique custom constellation shape from Earth’s perspective. When the constellation is saved and named, users would be able to select and access detailed information on each star. They would also be able to break away from Earth’s fixed viewpoint to explore and experience their constellation forms in 3D space. The constellation would be added to a database of newly created constellations, which could be toggled on and off from a UI panel hovering in space.
The saved constellation data would also be used to generate a visualization of the constellation on the web, which would provide an interactive 3D view of the actual 3D shape of the constellation, with a list of its constituent stars and detailed information of each star. The visualization may potentially include how the constellation shape would have appeared at a certain point in time, and how it has changed over the years (e.g. a timeline spanning Earth’s entire history).
The core concept of the project is to give people the freedom to draw any shape or pattern they desire with existing stars and create a constellation of personal significance. The generated visualization would be a digital artifact people could actively engage with to uncover the complex, hidden dimensions of their own creations and make new discoveries.
A sketch of the concept below:
A rough sketch of the builder and visualization functionalitiesInteractive 3D star map I built in VRExploring constellation forms in 3D space, and accessing their info
The initial concept was to create a jigsaw puzzle game you can play by scanning barcodes in a certain sequence. The idea was to give a sneak preview of a part of an image(“a puzzle piece”) by scanning a single barcode, and have people piece together the whole image.
To generate the barcodes that correspond to the pieces of an image, we converted an image to ascii code (pixel shade -> char), and split the ascii into strings that were encoded into barcodes for printing, using code-128. Ideally the order of the image pieces will be scrambled. The video shows how the barcode scanning in a specific order reconstructs the whole image.
We thought of various ways of revealing the image pieces encoded in the barcodes. Right now the program continuously appends the decoded image piece from left to right, top to bottom. Another way is to show the most recently scanned image piece on a ‘clue’ canvas, and have parts of the image only revealed on an ‘puzzle’ canvas when two adjacent puzzle pieces were scanned one after the other.
This interaction concept could be expanded to create a drawing tool. The barcode scanner would act as a paintbrush, and the sequences of barcodes would act as a palette. Scanning certain barcodes in a specific order would create unique image patterns, gradients, or edges, which could be combined to paint a picture.
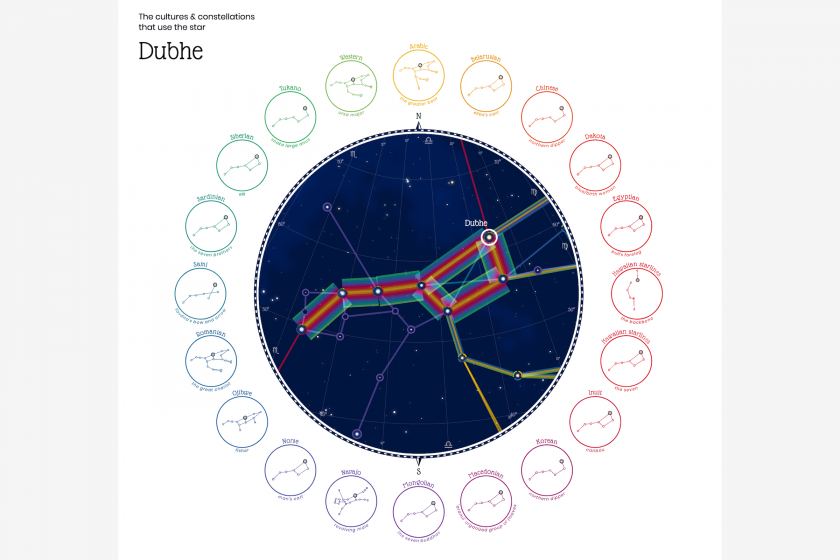
How the star Dubhe is used in constellations of various cultures
A visualization of constellations from 28 sky cultures, based on Stellarium data. It includes focused visualizations of a select number of major stars in the sky, which show overlapping constellation shapes from various sky cultures that include a specific star. The visualization captures how the shapes converge and diverge, and allows users to view the shapes individually. Despite the ambitious aim and scope of the project, I found the lack of cultural contextual information very limiting. It would have been more interesting to be able to view them within a broader sky view, and to learn more about the various mythologies behind the stars and constellation shapes. (Project link)
a selection of major starsThe Hawaiian constellation skyview
Never Lost: Polynesian Navigation (2011)
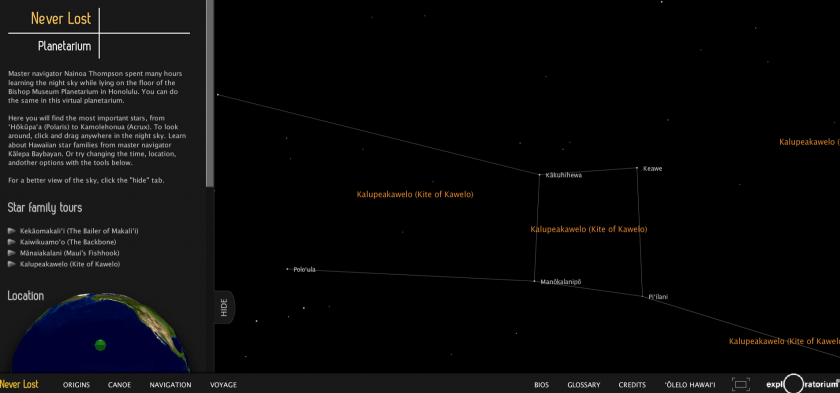
Produced by NASA and Hawaiian collaborators, the project intertwines astronomy, Hawaiian ancestry, and traditional navigation. The project website shows how the ancient Polynesians voyaged across vast expanses of open ocean without maps or compasses by relying on direct observation alone. While the project’s vast scope and content is compelling, the entirely flash-based website has not aged well over the years. The way the content is structured and presented makes it cumbersome to explore and navigate, and many of the video links are no longer working. The views and interactions provided by the virtual planetarium are also pretty standard and lackluster. (Project Link)
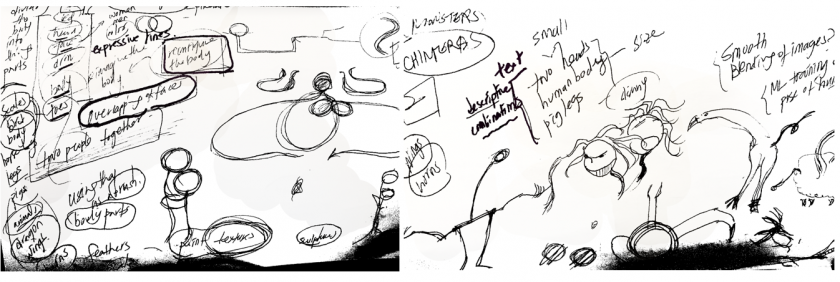
Throughout history, human beings have been fascinated by imaginary, hybrid creatures, which appear in myriad forms in many different cultures. My initial idea was to enable people to merge different parts of human and animal anatomical features, but via the expressive drawings of stick figures.
My approach involved applying different color brushes to represent different animals, and combining different color strokes to give form to wildly divergent hybrid animals that stimulate our imagination.
Concept Development
Assembly based creativity in 3DGANDissect style human body segmentationBody dissection & reconfigurationExplorations on potential methods
MY FIRST FORAY INTO MACHINE LEARNING..
I decided to use Christopher Hesse’s Pix2Pix tensorflow build to train and test a new GAN model specifically designed for chimera creations. It was a great opportunity to become familiar with creatively working and experimenting with ML, including its quirks. Understanding how the training process works in terms of the code was quite a learning curve. Setting up the right environment to run super-long, GPU-intensive tasks was not a straightforward process at all. Every different version of Pix2Pix had its own specific library and version dependencies for python, CUDA toolkit and cuDNN, so there was much trial and error involved in finding compatible, functioning versions to get everything reliably working (as in not crashing every 30 minutes or so).
Dataset Collection & Manipulation
KTH-ANIMALS dataset (2008)Auto-cropping generally resulted in important information being lost – in this case, the giraffe’s head
The dataset I ultimately chose for training was the KTH-ANIMALS dataset, which included approximately 1,500 images of a wide variety of animals (19 different classifications) with the foreground and background regions manually segmented. At first I thought the segmentation data was missing, since I could only see a stream of black png images; it turned out that the creator of the dataset just had a matrix for each mask and saved it in the form of pngs. I had to batch process the files to identify the different pixels (I had to identify the number of unique pixel values to determine the number of masks in the image and the background pixel value, which was most frequently (2,2,2) for images with one animal, (3,3,3) for two animals.)
Data selection was pretty tricky and challenging, because there were not a lot of datasets out there that were suitable for my purposes. I narrowed my search from (specific) animals and humans to just (general) animals, especially since it was difficult to find datasets of nude human beings that were not pornographic. There were no animal datasets I could find with pose or skeleton estimations; the only thing that came closest was research on the pose estimation of animals through deep learning, which consisted of training models to recognize certain parts of the animal’s anatomy by manually marking those parts in selective video frames (DeepLabCut, LEAP). I decided to try experimenting with masks instead of detailed annotated skeletons as a proof of concept.
Since the workable size for pix2pix was constricted to 256×256, the auto-cropping unfortunately cropped much important information from the imagery, such as the head and hind areas. I spent quite some time trying to implement seam carving (context-aware cropping) and replicate the same cropping method for both images and masks, but failed to find convenient ways of achieving this without a deeper understanding to substantially edit the code (I do plan to look deeper into it when I get the chance). I also looked into Facebook’s Detectron object recognition algorithm to automate the mask creation for photos that do not come with masks, for higher quality training data curation in the future.
Training Process
Training was set at 200 max epochs, on an i7 Windows 10 desktop computer with a Nvidia GeForce GTX 1060 GPU. The Pix2Pix-tensorflow version used for training was proven compatible and stable with python 3 + CUDA 10.0 + cuDNN 7.4 + tensorflow-gpu 1.13.1. (As of the timing of this post, the tf-nightly-gpu is too unstable and CUDA 10.1 is incompatible with cuDNN 7.5). Whereas training with tensorflow (CPU version) took 12+ hours to reach only 30 epochs, training for 200+ epochs on a CUDA-enabled GPU took less than 12 hours on the same desktop.
I edited the code to export the model into a pict format on CoLab, since the code was flagged as malicious on every computer I tried running it on.
input output target input output target
very initial resultsTesting shows it works well with some animals more than others
Discussion
Pix2Pix is good at recognizing certain stylistic features of animals, but not so great at differentiating specific features, such as the face. You can see how it often obliterates any facial features when reconstructing animal figures from masks in tests. To isolate features, I believe it would be more beneficial to train the model on detailed annotations of pose estimations that differentiate parts of the anatomy. It would be good to train on model on where the arms begin for instance, and where it ends to see if it can learn how to draw paws or horse hoofs. This approach might also enable the drawer to combine figures with detailed human anatomical parts such as our hands and fingers. I would have to experiment with human poses first (face, general pose, hand poses etc.) to see how robustly this approach works.
The way Pix2Pix works constrains the learning to a specific size, which can be immensely frustrating, since datasets rarely contain just one uniform size, and cropping photographs of animals often sacrifices important details of the animal structure as a whole.
The reconstruction of the background imagery is interesting. I didn’t isolate eliminate the background to train the model, so it applies a hybrid approach to the background as well. I didn’t differentiate one mask from another in the instance of multiple masks in one image, half hoping this might actually help the model combine many of the same creatures at once. I’ll have to compare this model with a model that is trained to differentiate the masks, and see how the results differ.
Ideas for Expansion
I would like to continue experimenting with different approaches of creating hybrids to fully explore the type of imagery each method is capable of creating. (CycleGAN, for example, might be useful for creating wings, horns, etc. from skeletal lines to augment features.) I want to curate my own high-quality animal dataset with context-aware cropping. I also want to play with image selections and filtering, and see if I could train a machine to create images that look more like drawings or sketches.
I would love to build a less rigid interface that allows more expressive gestural strokes, with controllable brush size and physically augmented options such as Dynadraw-type filtering. I would also want to play with combining human (nude) figures with animals, as well as with mechanical objects. I think it would be interesting to explore how GAN could be used to create interesting human-machine hybrids. Would it produce hallucinogenic imagery that only machines are capable of dreaming and bringing into being? Using pose estimations would also allow me to explore a more refined approach to intelligently and deliberately combining specific parts of animals and human beings, which may prove useful for creating particular types of imagery such as those of centaurs.
The work was initially sparked by the idea of mapping the history of myself onto my face. The core concept was to express and encapsulate in these masks the multitude of selves from different points in time, that would allow me to travel back and access what’s been filed away or buried within. I began creating masks from photographs that represented specific pivotal times of my life, that brought back certain moods and emotions. Trying on masks of my own face from the past brought back a flood of mixed emotions and memories, which transported me to a strange mental place. While trying to create a naturally aged version of my face, I was inspired to use my mother’s face to overlap with mine. This led to my creating a series of face masks that represented my mother in critical stages in her life, in tandem with mine. It only made sense, considering how much of an impact my difficult relationship with my mother had in shaping who I am, in more or less all aspects of my life. My mother’s masks enabled me to express voices of her – much of what I have internalized – which continues to be a source of internal strife and conflict. The process of creating the masks itself opened a way for me to untangle complex thoughts and feelings, and give distinct faces and voices to contradictory aspects of my identity.
I created a face texture generator that converts images to base64 and creates uv maps based on the facial landmark vertices. A critical factor guiding my image selection was having a clear, high-res frontal view of the face. Some of the images were then manipulated for improved landmark detection.
The Software
The mask software that evolved from these explorations allows me to rapidly switch between 15 face masks that act as portals to the past and future. The masks are carefully overlaid to my face, and the overlapping facial features
provide an interesting subtle tension, which is amplified in abrupt movement. The masks imbue my face with color and bring it to life. Depending on which mask I have on, I find myself naturally feeling and acting in a different way, and also engaging in private conversations with myself. I can choose to swap masks by speedily flipping through my choices, dramatically transitioning from one to another with visual effects, or simply selecting the one I want from a drop-down menu.
The various types of masks created for the performance
The act of putting on the masks is at once an unsettling self-interrogation and a cathartic form of self-expression. The software allows me to navigate and embody the myriad identities and spectrum of emotional states I have bubbling beneath the surface. The merging of my mother’s face with my own with age, expresses my hope for a certain closure and embrace with time. An image of my grandmother was also used to create an older mask version of my mother. The faces that form the masks span three generations, which reflect a sense of continuity and shared form of identity.
Experiments with different types of blend modes and mask transition effects that took advantage of technical glitchesFace flipping in actionGradual flickering transition testBlurring in and out between swaps
The Beyond Reality Face SDK – v4.1.0 (BRFv4) was used for face detection/tracking and face texture overlay that dynamically changes with eye blinking and mouth openings. Mario Klingemann’s Superfast Blur script / algorithm was used for animated blur effects during mask transitions.
The Performance
The mask performance that I had originally planned was scripted based on my recollections of interactions between me and my mother in different stages of our lives. I wanted the sparse words that make up the dialogues to capture the essence of events and moments in the past that continue to resonate, while not being too detailed in an overly(?) personal and revealing way. I wanted to allow enough room for viewers to be able to relate and reflect on their personal experiences. I had René Watz’s Out Of Space Image Pan playing in the background (a muffled static-like noise), to create an eerie, alien atmosphere.
What I failed to realize until too late, however, was how wrong I was in thinking I could perform this, especially for a public audience. Hearing my own voice out loud made me hyper conscious of how disconcertingly different it was from my inner cacophony of voices, which further alienated me from my own internal experiences I wanted to re-enact. The performance was overall a pretty disastrous experience, despite my repeated attempts to overcome my cognitive dissonance and deficiencies.
The first version of the script roughly reflected the five stages of grief – denial, anger, bargaining, depression and acceptance(reconciliation). Later realizing that the script was too long for a 2 minute performance, I condensed it to a much shorter version, which no longer stuck to a linear temporal narrative. I played with scrambling bits and pieces of the script in a random order, to reflect an inner chaos. My plans to convey this sense of disorientation through my script and acting, however, were effectively squashed during my clumsy attempts in performance.
Excerpts from a rough draft of the script
Ideally I would like to have the script read by someone with a deep, expressive voice, and have records of it playing like a voice-over during the performance. Specific parts of the script would be associated with specific masks, and dynamically played when the mask is put on. Without the dissonance of hearing my own voice, I imagine I would be able to channel my thoughts and feelings through my body language and facial expressions.
It would also be interesting to explore more meaningful ways of selecting and transitioning between masks. I thought of invoking certain masks depending on the similarity of facial expression and emotions, although the library I am currently using is not readily capable of distinguishing such subtle differences and nuances in expression. I also thought of using songs or pieces of music that I associate with a specific time and space to trigger the mask transitions.
Process/Notes
I went through many different ideas and designs before I embarked on the work I described above. Below are some excerpts from my ideation notes that show some of my thought process:
Sougwen Chung, Drawing Operations Unit (Generation 1 & 2, 2017-8)
Drawing Operations Unit: Generation 2 – MEMORY
Sougwen Chung’s Drawing Operations Unit is the artist’s ongoing exploration of how a human and robotic arm could collaborate to create drawings together. In Drawing Operations Unit: Generation 1 (D.O.U.G._1), the robotic arm mimics the artist’s gestural strokes by analyzing the process in real-time through computer vision software and moving synchronously/interpretatively to complement the artist’s mark-making. In D.O.U.G._2, the robotic arm’s movement is generated from neural nets trained on the artist’s previous drawing gestures. The machine’s behavior exhibits its interpretation of what it has learned about the artist’s style and process from before, which functions like a working memory.
I love how the drawing comes into being through a complex dynamic between the human and machine – the act of drawing becomes a performance, a beautiful duet. There is this constant dance of interpretation and negotiation happening between the two, both always vigilant and aware of each other’s motions, trying to strike a balance. The work challenges the idea of agency and creative process. The drawing becomes an artifact that captures their history of interaction.
There are caveats to the work as to what and how much the machine can learn, and whether it could contribute something more than just learned behavior. As I am painfully aware of the limitations of computer vision, I cannot help but wonder how much the machine is capable of ‘seeing’. To what extent could it capture all the subtleties involved in the gestural movements of the artist’s hand creating those marks? What qualities of the gesture and mark-making does it focus on learning? Does it capture the velocity of the gestural mark, the pressure of the pencil against the paper through conjecture? Are there only certain types of drawings one can create through this process?
It would also be wonderful to see people other than the artist draw with the machine, to see the diversity of output this process is capable of creating. The ways people draw are highly individualistic and idiosyncratic, so it would be interesting to see how the machine reacts and interprets these differences. I would also like to see if the machine could exhibit an element of unpredictability that goes beyond data-driven learned behavior, and somehow provoke and inspire the artist to push the drawing in unexpected creative directions.
Ephémère is an immersive, interactive visual/aural experience of spatial poetry, a nature-inspired philosophical meditation of sorts expressed in light, space and sound. The ‘immersant,’ equipped with a virtual reality (VR) Head-Mounted Display (HMD) and a body vest for sensing breathing/balance, floats in the virtual three-dimensional space of Davies’ creation and navigates its many temporal-spatial layers through controlled breathing, like a scuba diver deep in sea. Described in her notes as an embodiment of “the garden in the machine,” the artwork strives to “create an existential vertigo – not narrative, but stripping away to an existential level of being – a spinning in slow motion [1].”
In Ephémère, we find Char Davies approaching the pinnacle of artistry and technical fluidity, experimenting with cutting-edge technologies at the time to explore new forms of expression and ways of experiencing imagery, and expanding our sense of space-time. Her innovative use of transparent texture maps, for instance, creates soft edges and spatial/perceptual ambiguity that achieves a strange dematerializing effect and ethereal quality [2], subverting visual conventions in computer graphics. The custom-made bodily interface allows us to encounter and experience the dynamically changing dreamscape and ephemeral imagery through our bodies. The way she brought together many disparate elements – technical feats, philosophical ideas, symbolic painterly forms – to work as a cohesive whole that speaks to us on so many levels is astonishing.
2
Char Davies never considers her artworks to be solely of her own creation [2]. She had a small, dedicated team working with her to implement her grand vision for this work, and she credits herself for concept, direction, and art direction; George Mauro, computer graphics; John Harrison, custom VR software; Dorota Blaszczak, sonic architecture and programming; and Rick Bidlack, sound composition and programming [3]. The production was co-sponsored by Immersense and Softimage.
Ephémère alone took 2-3 years to create (’96-’98). The work naturally evolved from Osmose, her first immersive virtual artwork, which also took 2-3 years to produce (’93-’95) [2].
3
According to her notes, Char Davies found much inspiration in the later works of English painter J. M. W. Turner (1775-1851), whose landscape and maritime paintings were highly expressive and abstract in its representations of light, time and space [2]. Visual elements in her work are also reflective and evocative of ideas and imagery found in her favorite philosophers and poets such as Heidegger and Rilke. [2]
I find Flanagan’s proposition 2 and 3 equally compelling and relevant to my own creative goals. My work connects to proposition 3 in that it strives to create new types of engagement that challenges our everyday unconscious, reflexive ways of engaging and interacting with our physical and digital environment. It is not so dependent on prior knowledge and mechanism of popular mobile/PC/console games in particular. The challenge is to get people to deeply engage with the work to go beyond the superficial attractions of novelty and create an opportunity for critical reflection as opposed to instantaneous forgetful entertainment.
I am also inspired by the ideas that drive proposition 2 – it lowers the barriers for engagement, in that people can be drawn to readily engage with your virtual creations through familiar mechanisms of play. In games there is a natural race toward the finish line, and people are naturally curious to find out what happens next and stay engaged to a certain level given sufficient incentive. As long as it adheres to a basic structure, I am free to imbue meaning into anything I want – make it the ultimate end goal for the main character to die, promote all kinds of strange or unethical behavior to progress to the next level, open portals to new narratives, etc. Through this framework, I can get people to do the most absurd, nonsensical things, subvert expectations, and in doing so encourage people to think more deeply about things they wouldn’t otherwise. The challenge here would also be to go beyond ephemeral, lukewarm engagement. Critical reflection demands time, which is why it is important to keep people engaged long and deeply enough for that to happen.