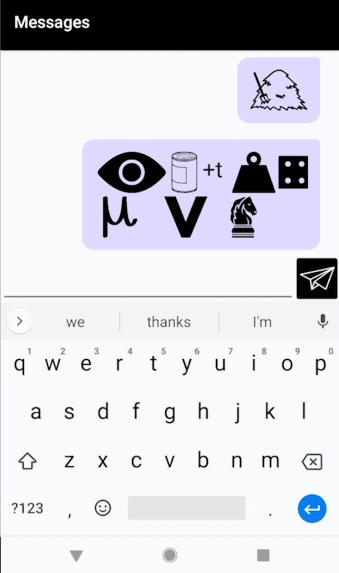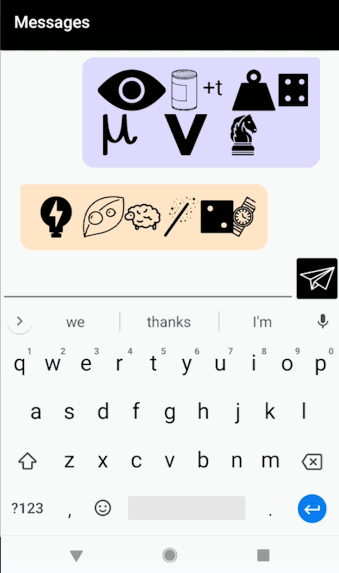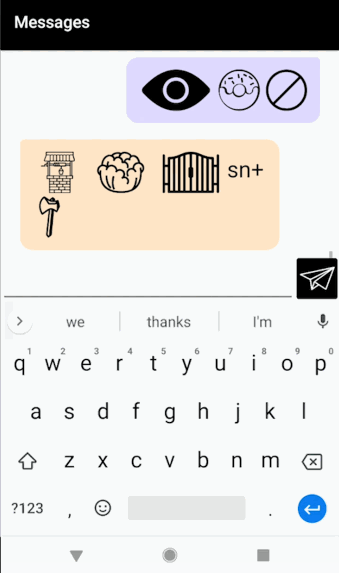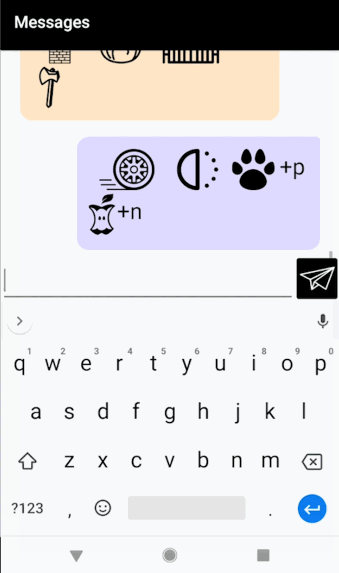
Rebus Chat
Description
My final project is a continuation of my project for the telematic assignment. It’s an Android chat app that automatically converts every message you send into a Rebus puzzle. For those unfamiliar, a Rebus is a puzzle in which words/syllables are replaced with images that depict the pronunciation, rather than the meaning, of the message. Below is an example Rebus of the phrase “To be or not to be.”

As you type, a preview of your Rebus-ified message appears above the text box. Pressing the paper airplane sends your message to the other person. Long pressing on any image generates a “hint” (a popup in the corner containing the title of that image). You can scroll back through past messages to see your chat history.
How it Works
I made Rebus Chat with Android Studio and Firebase (Quick sidenote about Firebase: it’s really amazing and I would recommend it to anyone making an Android app with things like authentication, databases, and ads. It’s very user friendly, it’s integrated with Android Studio, and it’s free!). All of the icons I used came from the Noun Project, and the pronunciations came from the CMU Pronouncing Dictionary.
The most important part of this app, and the one I am most proud of, is the Rebus-ification algorithm, which works as follows:
- All punctuation, except commas, are stripped (I will change this in future iterations)
- The string is split into words and those words are passed through the pronunciation dictionary, ultimately yielding a list of phonemes (words it doesn’t know are given a new “unknown” phoneme)
- The full list of phonemes is passed into a recursive Dynamic-Programming function that tries to get the set of “pieces” (I’ll explain what a piece is in a minute) with the best total score for this message. Working from the back (so that the recursive calls are mostly unchanged as the message is added to, which improves runtime), the function asks “How many (from 1-n, the length of the list) phonemes should make up the last piece, such that the score of that piece plus the score of the rest of the message (via a recursive call) is maximized?” As part of this, each sublist of phonemes is passed into a function that finds the best piece it can become.
- A “piece” is one of three things: Image, Word, or Syllable. The function to find the best piece for a given list of phonemes first checks every image we have to find the one with the best matching score (matching scores will be described next). If the best matching score is above a certain threshold, it’s deemed good enough and returned as an Image piece. If not, we say this list of phonemes is un-Rebusable. If the list contains exactly the phonemes from a full word in the original message–no more, no less–then it is a Word piece and returned as the word it originally was (this is the default when the pronunciation dictionary doesn’t know the word). Otherwise, the list is a Syllable piece and a string is generated to represent how those phonemes should be pronounced. I do this rather than using the letters from the original word because it is more readable in many cases (eg. if “junction” became a “Junk” image and then “ti” and then an “On” image, the “ti” would likely not read right. So in my code I turn it into “sh”).
- To find the matching score between a word and an image, we get the phoneme list for the image. Then we do a second Dynamic Programming algorithm which tries to find the best possible score to assign these two lists. The first sounds of each list can either be matched with each other, in which case we add to our total the sound-similarity score (explained below) for these two sounds, or one of the lists’ first sound can be skipped, in which case we match it with the “empty sound” and add the sound-similarity score for that sound and nothingness. This repeats recursively until we hit the end of the list.
- The sound similarity score is more or less a hard list of scores I made for each pair of sounds in the CMU Pronouncing Dictionary. The better the score, the better the match. In general, sounds that only kind of match (“uh” and “ah”) have slightly negative scores, as we want to avoid them, but can accept them, while sounds that really don’t match (“k” and “ee”) have very negative scores. Soft sounds like “h” have only slightly negative scores for matching with nothingness (ie. being dropped). Perfect matches have very positive scores (but not as positive as the non-matches are negative), and voiced/unvoiced consonant pairs (“s” and “z”, or “t” and “d”) are slightly positive because these actually swap out remarkably well.
- Okay. That’s it. The bottom of the stack of function calls. After all the results of all the functions get passed up to the top, we are left with the best-scoring list of pieces. We then render these one at a time: words are simply inserted as text. Syllables are also inserted as text, with a plus sign next to them if they are part of the same word as an adjacent image piece (syllables are not allowed not to be next to image pieces–there would be no reason to do this). Images are looked up in my folder and then inserted inline as images.
While that was kind of complicated to explain, it’s mostly very simple: it just tries everything and picks the best thing. The only real “wisdom” it has comes from the sound-similarity scores that I determined, and of course the pronunciation dictionary itself.

Reflection
Before I get into my criticisms, I want to say that I love this app. I am so glad I was encouraged to finish it. I genuinely get a lot of enjoyment out of typing random sentences into it and seeing what kind of Rebus it makes. I have already wasted over an hour of my life doing this.
Rebus Chat is missing some basic features, including the ability to log in and choose which user you want to message (in other words, it’s basically one big chat room you can enter as one of two hard-coded “users”). In that respect, it is incomplete. However, the critical feature (the Rebus-ification tool) is pretty robust, and even just as a Rebus-generating app I think it is quite successful.
There are still some bugs with that part to be worked out too. The most important is the fact that some images in my catalog fail to render correctly, and others have too much or not enough padding, causing the messages to look messy (and, when two syllables from separate words get squished together with no space, inaccurate). But I also can and should spend a little more time fine-tuning the weights I put on each sound matching, because it’s doing some more than I would like (eg. it turns “Good” into “Cut” because g->c and d->t and oo->u are all considered acceptable) and others less than I would like.
Still, for how little it was tested, I am really happy with the version that was used in the class showcase. People seemed to have fun, and I scrolled back through the chat history afterwards and saw a lot of really interesting results. It was cool to have gotten so many good test cases from that show! Some of my favorites are below (try to decipher them before reading the answers 😀 ).
 “Carnegie Mellon University Tartan” = Car+Neck+ee / / m+L+on / / Ewe+nuv+S+u+tea / / t+Art+On
“Carnegie Mellon University Tartan” = Car+Neck+ee / / m+L+on / / Ewe+nuv+S+u+tea / / t+Art+On
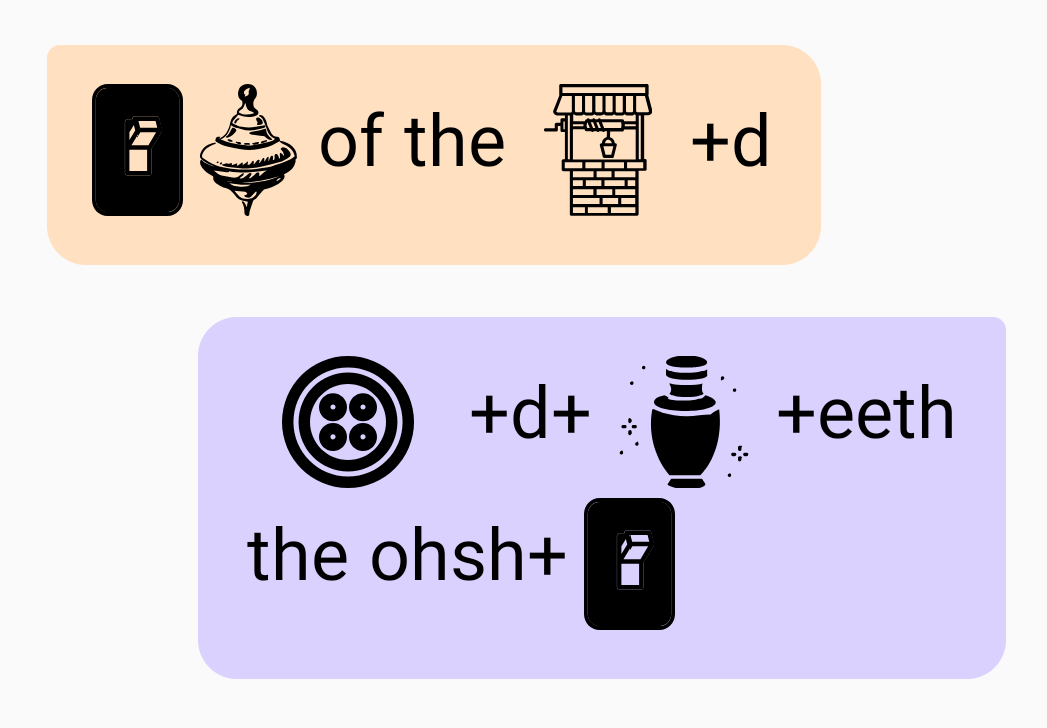 “On top of the world. But underneath the ocean.” = On // Top // of // the // Well+d. Button+d+Urn+eeth // the // ohsh+On
“On top of the world. But underneath the ocean.” = On // Top // of // the // Well+d. Button+d+Urn+eeth // the // ohsh+On
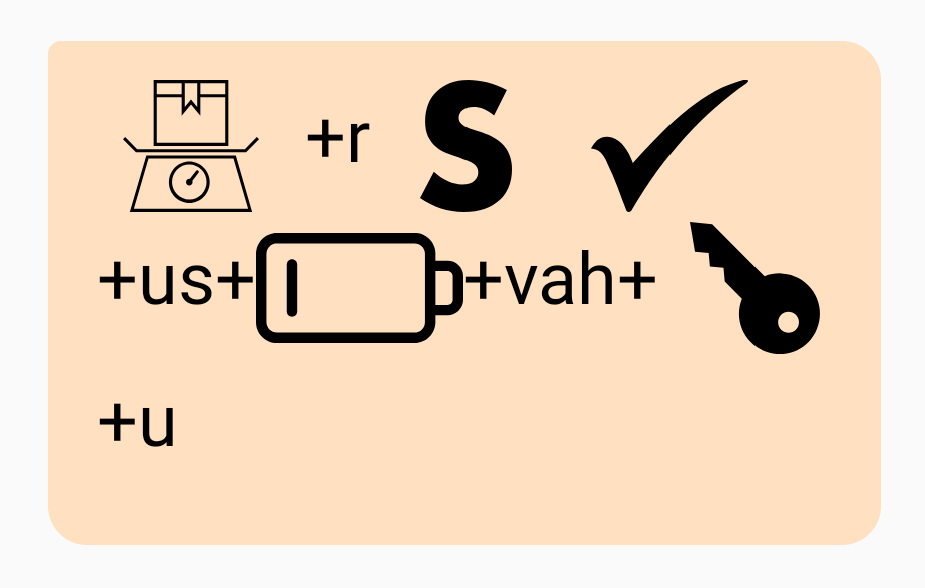 “Where is Czechoslovakia?” = Weigh+r / / S / / Check+us+Low+vah+Key+u
“Where is Czechoslovakia?” = Weigh+r / / S / / Check+us+Low+vah+Key+u
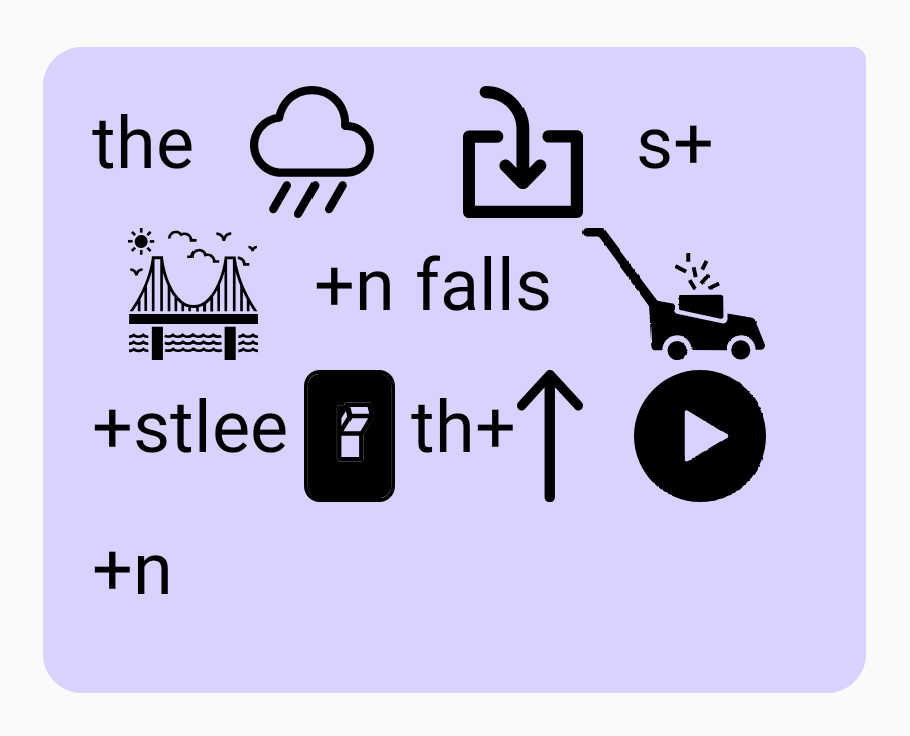 “The rain in Spain falls mostly on the plain.” = The // Rain // In // s+Bay+n // falls // Mow+stlee // On // th+Up // Play+n
“The rain in Spain falls mostly on the plain.” = The // Rain // In // s+Bay+n // falls // Mow+stlee // On // th+Up // Play+n
(I like this one as an example of a letter sound being duplicated effectively: “the plain” into “th+up” and “play+n”)
 “I am typing something for this demo” = Eye // M // Tie+Pin // Sum+Thin // Four // th+S // Day+Mow
“I am typing something for this demo” = Eye // M // Tie+Pin // Sum+Thin // Four // th+S // Day+Mow
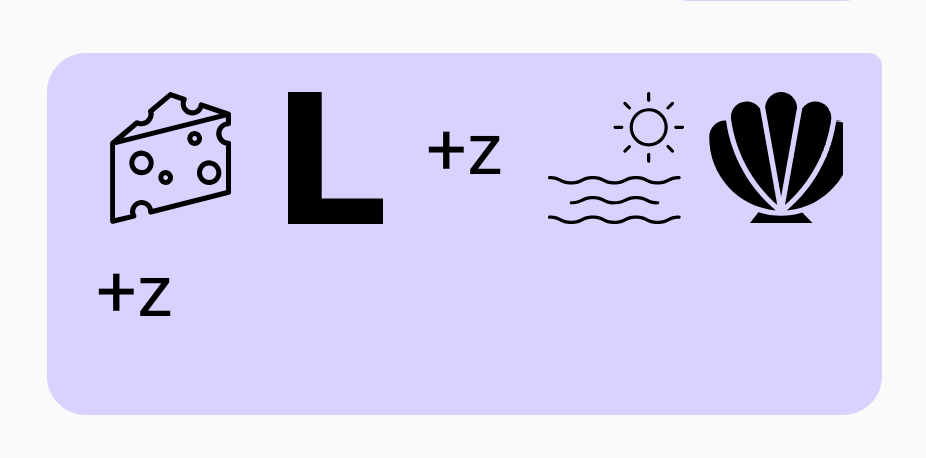 “She sells sea shells” = Cheese // L+z // Sea // Shell+z
“She sells sea shells” = Cheese // L+z // Sea // Shell+z
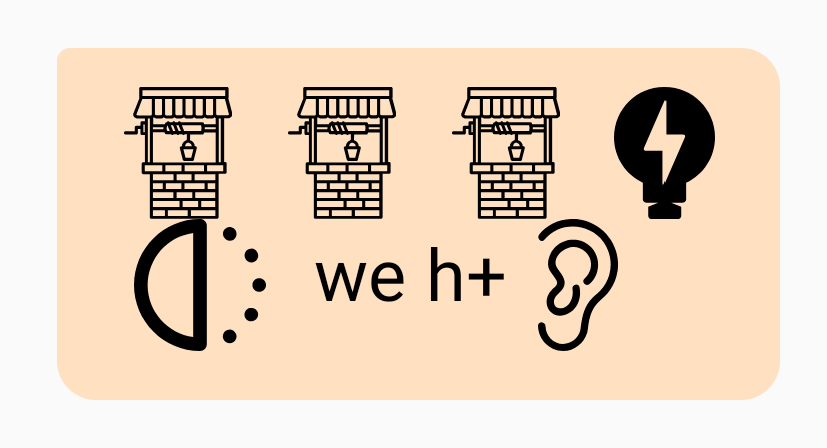 “Well well well, what have we here?” = Well // Well // Well // Watt // Half // we // h+Ear
“Well well well, what have we here?” = Well // Well // Well // Watt // Half // we // h+Ear
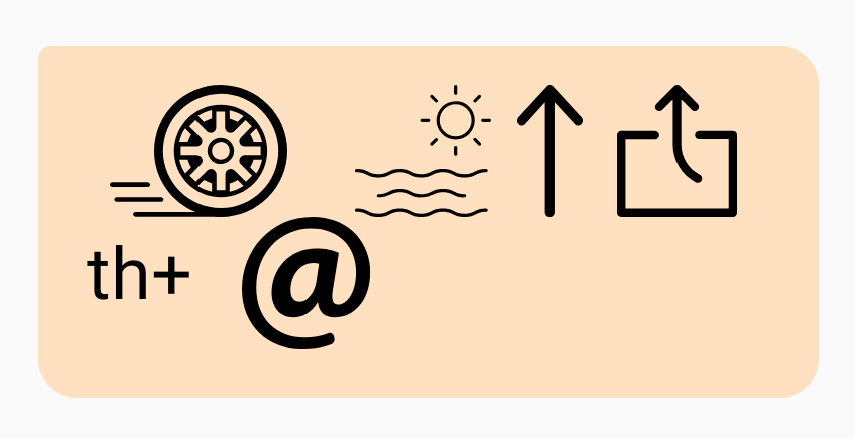 “We’ll see about that” = Wheel // Sea // Up // Out // th+At
“We’ll see about that” = Wheel // Sea // Up // Out // th+At
 “What do you want to watch tonight?” = Watt // Dew // Ewe // Wand // Two // Watch // tu+Knight
“What do you want to watch tonight?” = Watt // Dew // Ewe // Wand // Two // Watch // tu+Knight
 “Golan is a poo-poo head” = Go+Lung // S // Up+oo // Poo // Head
“Golan is a poo-poo head” = Go+Lung // S // Up+oo // Poo // Head
(I like this one as an example of two words merging: “a poo” into “Up+oo.” I was also pleased to find out that the pronunciation dictionary knows many first names)
Moving Forward
I would like to complete this app and release it on the app store, but the authentication parts of it are proving more painful than I thought. It may happen, but something I want to do first is make Rebus Chat into an extension for Messenger and/or email, so that I can share the joy of Rebus with everyone without having to worry about all of the architecture that comes with an actual app. This way, I can focus on polishing up the Rebus-ification tool, which in my opinion is the most interesting part of this project anyway. Whether I ultimately release the app or not, I’m really glad to have learned Android app development through Rebus Chat.


 This gives them a videogame-like 3rd person perspective of themselves and the world. I find this idea very interesting, because I often see myself in videos and in my memories as different than I do in the moment, and because people behave differently when they can see themselves (like in mirrors) than when they can’t. I’d be curious as to how people feel about wearing this, and how it affects their interactions with people (besides the obvious effects of wearing a backpack and VR headset around…).
This gives them a videogame-like 3rd person perspective of themselves and the world. I find this idea very interesting, because I often see myself in videos and in my memories as different than I do in the moment, and because people behave differently when they can see themselves (like in mirrors) than when they can’t. I’d be curious as to how people feel about wearing this, and how it affects their interactions with people (besides the obvious effects of wearing a backpack and VR headset around…).