doodle-place
doodle-place is a virtual world inhabited by user-submitted, computationally-animated doodles.

For my final project I improved on my drawing project. I added 4 new features: a mini-map, dancing doodles, clustering/classification of doodles, and the island of inappropriate doodles (a.k.a penisland).
Doodle Recognition
I supposed with the prevalence of SketchRNN and Google Quickdraw, there would be ready-made doodle recognition model I can simply steal. But it turned out I couldn’t find one, so I trained my own.
I based my code on the tensorflow.js MNIST example using Convolutional Neural Networks. Whereas MNIST trains on pictures of 10 digits, I trained on the 345 categories of quickdraw dataset.
I was dealing with several problems:
- The Quick, draw! game is designed to have very similar categories to supposedly make the gameplay more interesting. For example, there’re duck, swan, flamingo, and bird. Another example is tornado and hurricane. For many crappy drawings in the dataset, even a non-artificial intelligence like me cannot tell which category they belong to.
- There are also categories like “animal migration” or “beach”, which I think are too abstract to be useful.
- Quick, draw! interrupts the user once it figures out what something is, disallowing them to finish their drawing, so I get a lot of doodles with just 1 stroke or 2. Again as a non-artificial intelligence I have no idea what they represent.
- There are many categories related to the human body, but there is no “human” category itself. This is a pity, because I think the human form is one of the things people tend to draw when they’re asked to doodle. I feel there’s a good reason for Google to not include this category, but I wonder what it is.
Therefore, I manually re-categorized the dataset into 17 classes, namely architecture, bird, container, fish, food, fruit, furniture, garment, humanoid, insect, instrument, plant, quadruped, ship, technology, tool and vehicle. Each class would include several of the original categories, while maintaining the same number of doodles in total in each class. 176 out of the 345 original categories are covered using my method. Interestingly, I find the process of manually putting things into categories very enjoyable.
Some misnomers (not directly related to machine learning/this project):
- I included shark and whale and dolphin in the fish category, because when drawn by people, they look very similar. But I think biology people will be very mad at me. But I also think there’s no English word that I know of for “fish-shaped animals”? The phrase “aquatic animals” would include animals living in water that are not fish-shaped.
- I put worm, spider, snake, etc. in the “insect” category, though they are not insects. There also seems to be no neutral English word that I know of for these small animals. I think “pest/vermin” focuses on a negative connotation. In where I come from, people would call them “蛇虫百脚”.
- Since there’s no “human” category in quickdraw, I combined “angel”, “face”, “teddy bear”, and “yoga” into a “humanoid” category. So my recognizer works not that well with really regular-looking humans, but if you add some ears, or a circle on top of their head, or have them do a strange yoga move, my network has a much larger chance of recognition.
I initially tested my code in the browser, and it seemed that WebGL can train these simple ConvNets really fast so I sticked with it instead of switching to more beefy platforms like Colab / AWS. I rasterized 132600 doodles from quickdraw, downscaled them to 32×32, and fed into the following ConvNet:
model.add(tf.layers.conv2d({
inputShape: [NN.IMAGE_H, NN.IMAGE_W, 1],
kernelSize: 5,
filters: 32,
activation: 'relu'
}));
model.add(tf.layers.maxPooling2d({poolSize: 2, strides: 2}));
model.add(tf.layers.conv2d({kernelSize: 5, filters: 64, activation: 'relu'}));
model.add(tf.layers.maxPooling2d({poolSize: 2, strides: 2}));
model.add(tf.layers.conv2d({kernelSize: 3, filters: 64, activation: 'relu'}));
model.add(tf.layers.flatten({}));
model.add(tf.layers.dense({units: 512, activation: 'relu'}));
model.add(tf.layers.dropout({rate:0.5}));
model.add(tf.layers.dense({units: NUM_CLASSES, activation: 'softmax'}));
This is probably really kindergarten stuff for machine learning people, but since it’s my first time playing with the build up of a ConvNet myself, so I found it pretty cool.
Here is an online demonstration of the doodle classifier on glitch.com:
https://doodle-guess.glitch.me/play.html
It is like a Quick Draw clone, but better! It actually lets you finish your drawings! And it doesn’t force you to draw anything, but only give you some recommendations on the things you can draw!
Here is a screenshot of it working on the 24 quadrupeds:
I also made a training webapp at https://doodle-guess.glitch.me/train.html. It also gives nice visualizations on the training results. I might polish it and release it as a tool. The source code and the model itself are also hosted on glitch: https://glitch.com/edit/#!/doodle-guess
Some interesting discoveries about the dataset:
- People have very different opinions on what a bear looks like.
- Face-only animals prevails over full-body animals.
- Vehicles are so easy to distinguish from the rest because of the iconic wheels.
- if you draw something completely weird, my network will think it is a “tool”.
Check out the confusion matrix:

Doodle Clustering
The idea is that doodles that have things in common would be grouped together in the virtual world, so the world would be more organized and therefore more pleasant to navigate.
I thought a lot about how I go from the ConvNet to this. A simple solution would be to have 17 clusters, with each cluster representing one of the 17 categories recognized by the doodle classifier. However, I feel that that the division of the 17 categories is somewhat artificial. I don’t want to impose this classification on my users. I would like my users to draw all sorts of weird stuff that don’t fall into these 17 categories. Eventually I decided to do an embedding of all the doodles in the database, and use k-means to computationally cluster the doodles. This way I am not imposing anything, it is more like the computer saying: “I don’t know what the heck your doodle is, but I think it looks nice along side these bunch of doodles!”
I chopped off the last layer of my neural net, so for each doodle I pass through, I instead get a 512 dimensional vector representation from the second to last layer. This vector supposedly represent the “features” of the doodle. It encodes what’s so unique about that particular doodle, and in what ways it can be similar to another doodle.
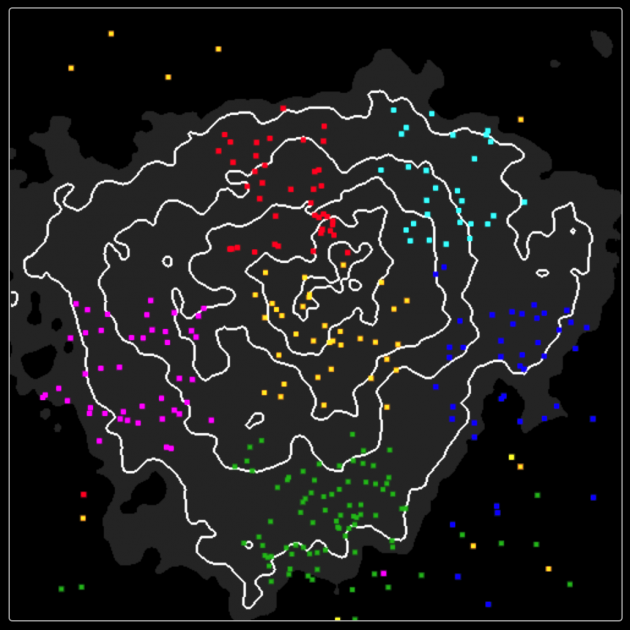
I sent the 512D vectors to a javascript implementation of t-SNE to compress the dimension to 2D, and wrote a k-means algorithm for the clustering. This is what the result looks like:

- The pigs, tigers, horses, cats all got together, nice!
- The bunnies got their own little place
- The trees are near each other, except for the pine tree, which seems very unlike a tree from the AI’s perspective.
- Humanoids are all over the place, blame quickdraw for not having a proper “human” category.
In the virtual world, the doodles will roam around their respective cluster center, but not too far from it, with the exception of fishoids, which will swim in the nearest body of water. You can see the above view at https://doodle-place.glitch.me/overview.html
Doodle Recognition as a hint for animation
So originally I have 4 categories for applying animation to a doodle: mammaloid, humanoid, fishoid, birdoid, and plantoid. The user would click on a button to choose how they animate a doodle. Now that I have this cool neural net, I can automatically choose the most likely category for the user. For those doodles that looks like nothing (i.e. low confidence in all categories from ConvNet’s perspective), my program still defaults to the first category.
Minimap
I received comments from many people that the place is hard to navigate as one feels like they’re in a dark chaotic environment in the middle of nowhere. I added a minimap to address the issue.
I chose the visuals of isopleths to conform with the line-drawing look of the project.
I also considered how I could incorporate information about the clustering. One method would be to plot every doodle on the map, but I didn’t like the mess. Eventually I decided to plot the cluster centers, using the visual symbol of map pins, and when user hovers over the pin, a small panel shows up at the bottom of the minimap, letting you know just what kinds of doodles to expect (by giving some typical examples), and how many doodles there are in the cluster. This GUI is loosely inspired by Google Map.
Golan suggested that if the user clicks on the pins, there should be an animated teleportation to that location. I am yet to implement this nice feature.

Dancing Doodles
Golan proposed the idea that the doodles could dance to the rhythm of some music, so the whole experience can potentially be turned into a music video.
I eventually decided to implement this as a semi-hidden feature: When user is near a certain doodle, e.g. doodle of a gramophone or piano, the music starts playing and every doodle would start dancing to it.
At first I wanted to try to procedurally generate music. I haven’t done this before and know very little about music theory, so I started with this silly model, in the hope of improving it iteratively:
- The main melody is a random walk of the piano keyboard. It starts with a given key, and at each step can go up a bit or down a bit, but not too much. The idea is that if it jumps too much, it sounds less melodic.
- The accompaniment is repeated arpeggios consisting of the major chord depending on the key signature.
- Then I added a part that simply plays the tonic at the beat, to increase the strength of the rhythm
- Finally a melody similar to the main melody but higher in pitch, just to make the music sound richer.
The resultant “music” sounds OK at the beginning, but gets boring after a few minutes. I think an improvement would be to add variations. But then I ran out of time (plus my music doesn’t sound very promising after all) and decided to go in another direction.
I took a MIDI format parser (tonejs/midi) and built a MIDI player into doodle-place. It plays the tune of Edvard Grieg’s In the Hall of the Mountain King by default, but can also play any .midi file the user drags on top of it. (Sounds much better than my procedurally generated crap, obviously, but I’m still interested in redoing the procedural method later, maybe after I properly learn music theory)
My program automatically finds the beat of the midi music using information returned by the parser, and synchronize the jerking of all the doodles to it. I tried several very different midi songs, and was happy that the doodles do seem to “understand” the music.

^ You can find the crazy dancing gramophone by walking a few steps east from the spawn point.
One further improvement would be having the doodles jerk in one direction while the melody is going upwards in pitch, and in the other direction when it is going down.
Island of Inappropriate Doodles (IID)
Most people I talk to seems to be most interested in seeing me implementing this part. They are all nonchalant when I describe all the other cool features I want to add, but only become very excited when I mentioned this legendary island.
So there it is, if you keep going south and continue to do so even when you’re off the minimap, you will eventually arrive at Island of Inappropriate Doodles, situated on the opposite side of the strait, where all the penises and vaginas and swastikas live happily in one place.
I thought about how I should implement the terrain. The mainland is a 256×256 matrix containing the height map, where intermediate values are interpolated. If I include the IID in the main height map, the height map needs to be much much larger than the combined area of the two lands because I want to have decent distance between them. Therefore I made two height maps one for each land, and instead have my sampler take in both as arguments and output the coordinates of a virtual combined geometry.
