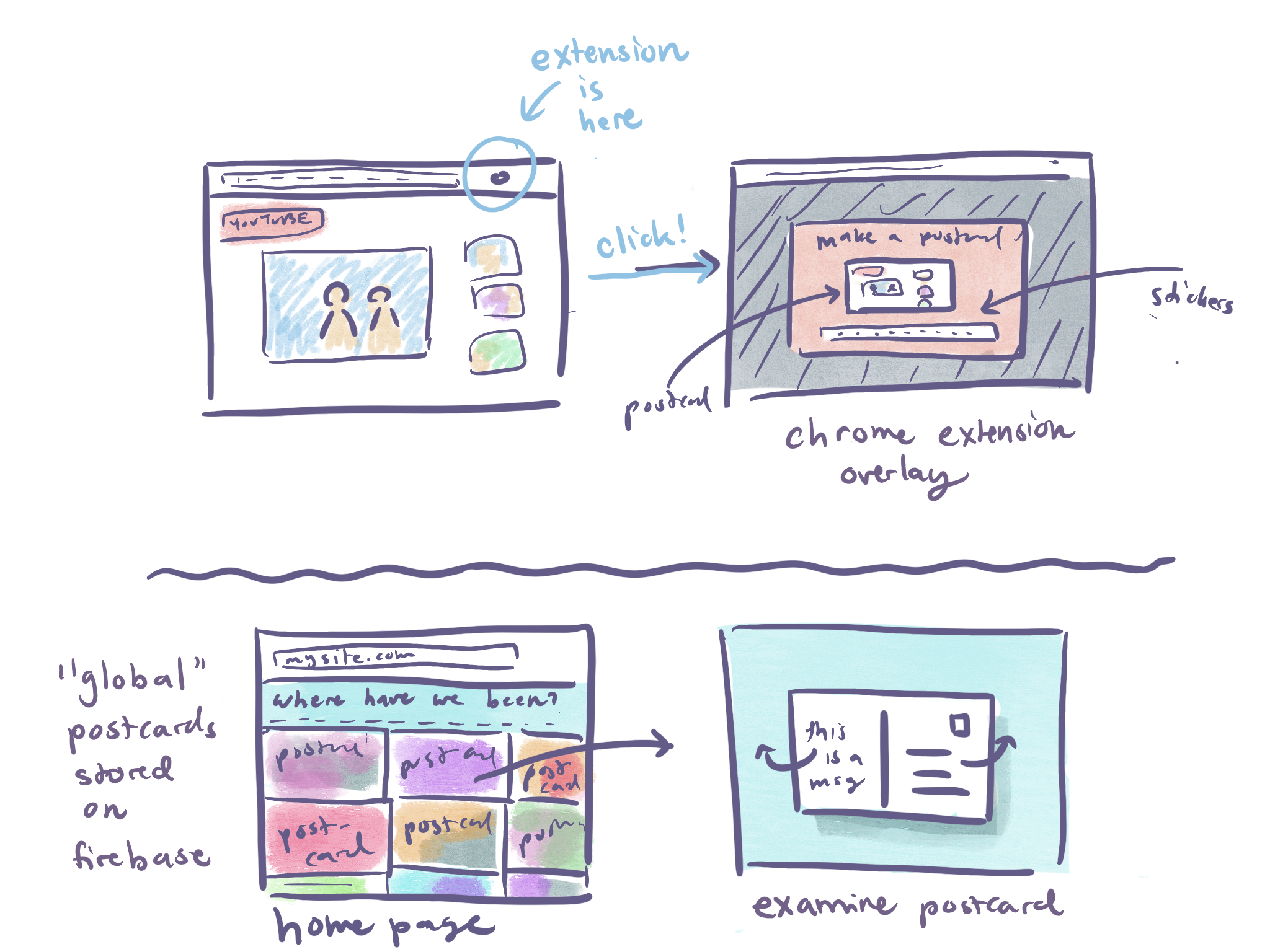
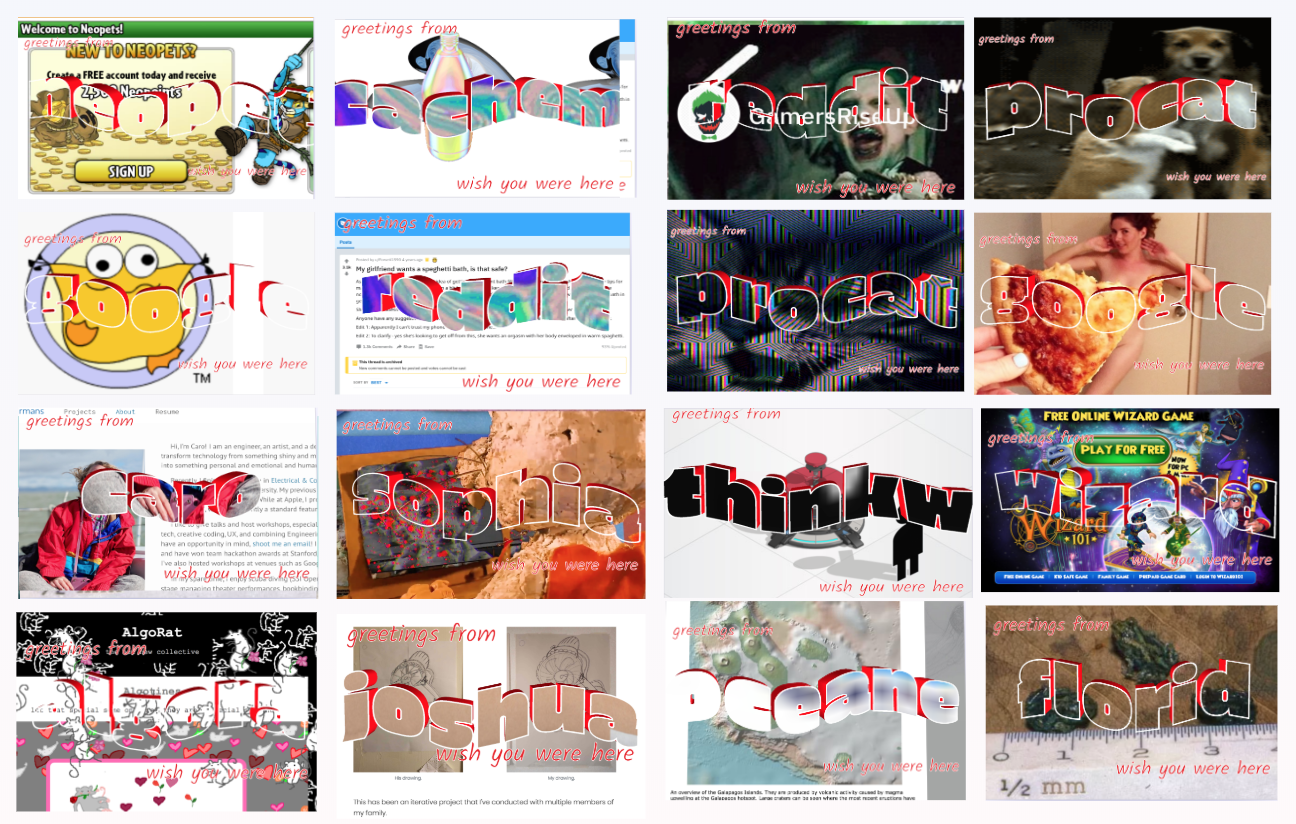
Internet Postcards: Travels from the World Wide Web
Internet Postcards is a chrome extension that allows you to generate physical, mailable postcards from your internet adventures.
“We live on the internet, so why not share your travels?” – Lumar
More specifically, this chrome extension takes a screenshot of the webpage that you are currently browsing, and opens an overlay in which you can postcard-ify the postcard with some decorative text, leave a message on the back and send the postcard result to a real physical address using an online direct mailing service.
This project was inspired by my nostalgia for the physical artifacts that result from traveling. Although I love sending postcards home to my mom, I rarely travel away from the university campus and my room. This project is my solution to that predicament. If the only places that I visit are online, then why not send postcards from those locations instead?
Early prototypes / ideas:
This project began as an idea for a telecommunications system / manufactory. Below is an early prototype I made demonstrating how I imagined it might function.
I also hoped that I could keep a global homepage of all of the postcards that were made (only shown if the user opted in to show their work on the page)!
I developed this tool using some base code that I found for a screen capture chrome extension by Simeon Velichkov. I spent a good amount of the time working on making the generative decorative text that shows up on postcards. I made it using three.js, but plan to work on the url-hyphenation part, along with the overall shape of this text as well.
Although still incomplete, I’m really glad that I was able to show this at the exhibit and actually see people use my extension. Although the printing process wasn’t as streamlined as I was hoping for, the fact that they could sit down, use my extension, and walk away with a real, mailable postcard with a stamp on it excites me and makes me really happy!
I’m also so grateful for all of the feedback during the final crit-all of it was incredibly helpful, and it was exactly what I needed.
Future Directions:
I plan on continuing this project and releasing it as a real extension for public usage! Before that, I need to:
add in direct mailers
add in paypal so i don’t go b r o k e
email receipts of transaction
address book
address verification
post to twitter / have a global homepage
impose NSFW filter
make a better documentation video
Exhibition Documentation
Below is a compilation of where people visited during my exhibit.
Special Thanks to:
Golan Levin for his advice during the creation of my project
the Studio for Creative Inquiry and Tom Hughes for their support and the funding through the Frank Ratchye Fund for Arts @ the Frontier
everyone who stopped by to try the project during the exhibit
Simeon Velichkov for making a screenshot capture extension under the MIT license (https://github.com/simov/screenshot-capture)
A collection of depth-capture collages from daily life arranged into an altar for personal reflection and recombination.
Overview:
This project was inspired to take the drippy tools of depth capture and create a means for using this technology to facilitate a daily drawing practice with point clouds. As I worked on creating this, ideas of rock gardens and altars came to me from a desire to create personal intimate spaces for archive, arrangement, and rest. How can I have the experience of my crystal garden in my pocket? A fully functional mobile application is the next step of this project. What are the objects in one’s everyday depth garden? For me, it was mostly my friends and interesting textures. What would you like to venerate in your everyday?
Narrative:
This project was a continuation of my drawing software, with the aim of activating the depth camera now included in new iPhones as a tool to collage everyday life – to draw a circle around a segment of reality and capture the drippy point clouds for later reconcatenation in a 3D/AR type space.
In this version of the project, I focused the scope of my project to create a space that could be navigated in 3D, a space that would allow viewers to ‘fly’ through the moments captured from life. In a world where there is so much noise and image-overload, I wanted to create a garden space that would allow people to collect, arrange and take care of reflections from their everyday – to traverse through senses of scale and arranged amalgamations outside of our material reality.
In developing this project, I had to face the challenges of getting the scans in .PLY format from the app Heges into my Unity-based driving space. Figuring out how to make this workflow possible was a definite challenge for me. The final pipeline solution was to use Heges to capture the scan in an unknown PLY format; then to bring it unto Meshlab to decimate the amount of data as well as convert it to the PLY binary little-endian format file that would allow Keijiro Takahashi’s PCX Unity package to work. From there I could start to collage and build space in Unity that could then be explored during gameplay mode.
While I was happy with the aesthetics of the result, I wanted to take this project much further in the following ways: I wanted to have the process described above be able to happen ‘offscreen’ in one click. I also wanted the garden space to be editable as well as traversable. Lastly, in the stretch-goal version I wanted it to be a mobile application that could be carried around in one’s pocket. I think as I continue to explore depth capture techniques and their everyday applications these steps are things I will strive towards.
Above is video documentation of a fly through in the point cloud garden.
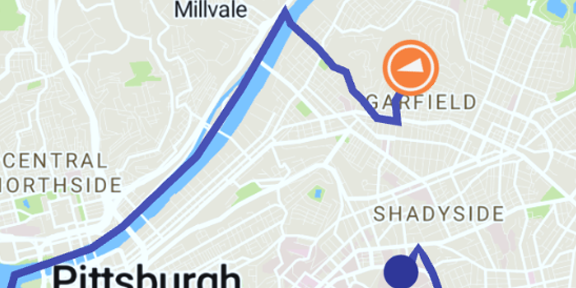
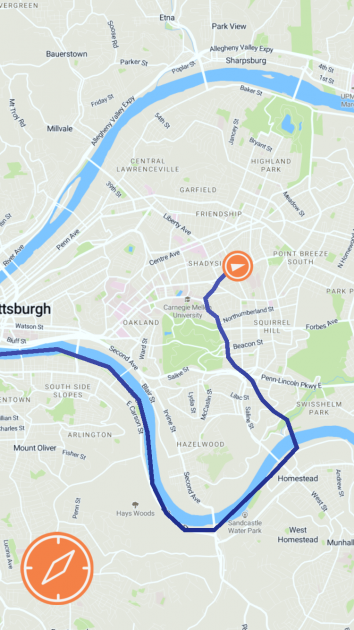
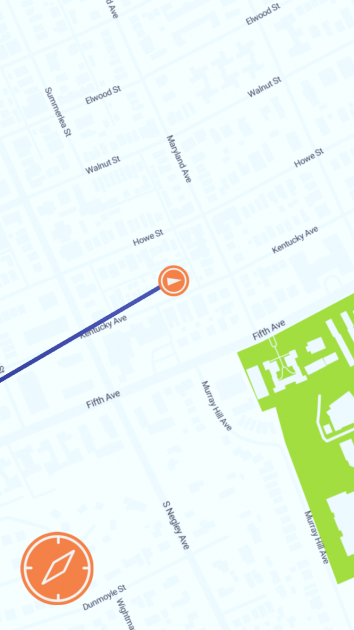
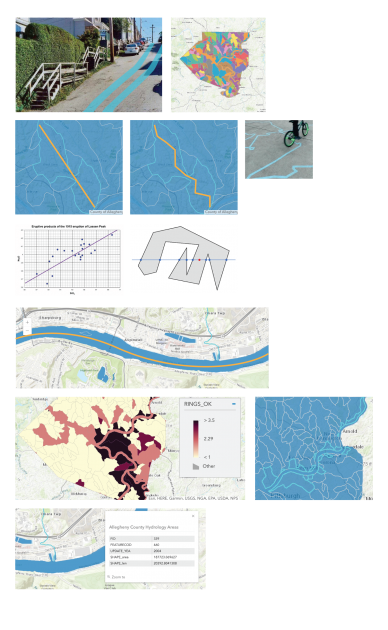
Waterline encourages responsible water use by drawing a line of where water would flow if you kept pouring it on the ground in front you.
Waterline is an app that shows you where water would go if you kept pouring it on the ground in front of you. Its goal is to demonstrate all the areas that you affect with your daily use of water, to encourage habits that protect the natural environment and the public health of everywhere downstream of you. In Pittsburgh, for example, the app maps the flow of water downhill from your current location to the nearest of the city’s three rivers, and from there continues the line downstream. The app provides a compass which always points downstream, making your device a navigation tool to be used to follow the flow of water in the real world. By familiarizing you with the places that you might affect when your wastewater passes through them, Waterline encourages you to adjust your use of potential pollutants and your consumption of water to better protect them.
Waterline was inspired by the Water Walks events organized by Zachary Rapaport that began this Spring and Ann Tarantino’s Watermark in Millvale this past year. Both of them are trying to raise awareness about the role water plays in our lives, with a focus on critical issues that affect entire towns in Pittsburgh.
I developed Waterline in Unity using the Mapbox SDK. Most of the work of the app went into loading GeoJSON data on the Pittsburgh watersheds and using that data to determine a line by which water would flow from your current location to the nearest river. Waterline uses an inaccurate way of determining this line, so that right now it functions mostly as an abstract path to the river.
Waterline’s success, I believe, should be measured in its ability to meaningfully connect its users to the water they use in their daily life and to encourage more responsibility for their use of water. Ideally, this app would be used as a tool for organizations like the Living Waters of Larimer to quickly educate Pittsburgh residents about their impact, through water, on the environment and public health, so that the organization can have a stronger base for accomplishing its policy changes and sustainable urban development projects. I think this project is a successful first step on that path of quickly visualizing your impact on water, but it still needs to connect people more specifically to their watershed and answer the question of what can I do now to protect people downstream of me.
Thank you Zachary Rapaport and Abigail Owen for teaching me about the importance of water and watersheds in my life.
From my sketchbook, visuals and identifying technical problems to solve:
From my sketchbook, preliminary visual ideas for the app:
From my sketchbook, notes on Ann Tarantino’s Watermark:
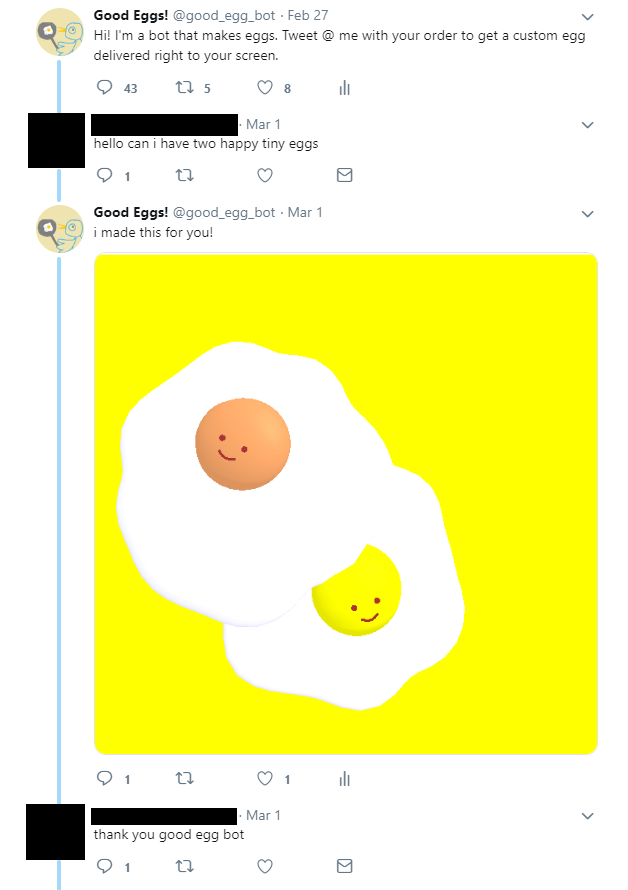
The good_egg_bot is a benevolent twitter bot that will try its best to make the egg(s) you desire. Twitter users can tweet requests for certain colors, types, sizes, and amounts of egg to get an image of eggs in response. I made this project because I wanted to have a free and easily accessible way for people to get cute and customizable pictures of eggs. I was also excited by the prospect of having thousands of unique egg pictures at the end of it all.
I was inspired by numerous bots that I have seen on twitter that make generative artwork, such as the moth bot by Everest Pipkin and Loren Schmidt, and the Trainer Card Generator by xandjiji. I chose eggs as my subject matter because they are simple to model through code, and I like the way that they look.
I used nlp-compromise to parse the request text, three.js to create the egg images, and the twitter node package to respond to tweets. I used headless-gl to render the images without a browser. Figuring out how to render them was really tricky, and I ended up having to revert to older versions of packages to it to work. The program is hosted on AWS so the egg bot will always be awake. I found Dan Shiffman’s Twitter tutorials to be really helpful, though some of it is outdated since Twitter has changed their API.
This project has a lot of room for more features. Many of people asked for poached eggs, which I’m not really sure how to make but maybe I’ll figure it out. Another suggestion was animating the eggs, which I will probably try to do in the future. Since it took so much effort to figure out how to render a 3D image with headless-gl, I think I should take advantage of the 3D-ness for animations. I like how, since the bot is on twitter, I have a record of how people are interacting with the bot so I can see what features people want. In my mind, this project will always be unfinished as there are so many ways for people to ask for eggs.
Here is a video tutorial on how to use the good_egg_bot:
“makes you think… 🤔” is a system for maximizing brain usage. Stare at the cross, and the system will automatically optimize what you see to maximally activate your brain.
abstract overview
makes you think… 🤔 combines a portable EEG sensor with a parametric image generator. It modifies the image generated to maximise the brain activity in the beta & gamma waves produced by your brain. It could be considered the opposite of meditation.
big pic
narrative
I was inspired by the EEG sensor used – the “Muse” headband – being framed as “next-level” meditation in its advertising
makes you think… 🤔’ uses a non-gradient based optimization of input parameters for a parametric image generator to generate an image, with the loss value for each image being derived from the level of brain activation when that image is seen.
My final project is a continuation of my project for the telematic assignment. It’s an Android chat app that automatically converts every message you send into a Rebus puzzle. For those unfamiliar, a Rebus is a puzzle in which words/syllables are replaced with images that depict the pronunciation, rather than the meaning, of the message. Below is an example Rebus of the phrase “To be or not to be.”
To be or not to be…
As you type, a preview of your Rebus-ified message appears above the text box. Pressing the paper airplane sends your message to the other person. Long pressing on any image generates a “hint” (a popup in the corner containing the title of that image). You can scroll back through past messages to see your chat history.
How it Works
I made Rebus Chat with Android Studio and Firebase (Quick sidenote about Firebase: it’s really amazing and I would recommend it to anyone making an Android app with things like authentication, databases, and ads. It’s very user friendly, it’s integrated with Android Studio, and it’s free!). All of the icons I used came from the Noun Project, and the pronunciations came from the CMU Pronouncing Dictionary.
The most important part of this app, and the one I am most proud of, is the Rebus-ification algorithm, which works as follows:
All punctuation, except commas, are stripped (I will change this in future iterations)
The string is split into words and those words are passed through the pronunciation dictionary, ultimately yielding a list of phonemes (words it doesn’t know are given a new “unknown” phoneme)
The full list of phonemes is passed into a recursive Dynamic-Programming function that tries to get the set of “pieces” (I’ll explain what a piece is in a minute) with the best total score for this message. Working from the back (so that the recursive calls are mostly unchanged as the message is added to, which improves runtime), the function asks “How many (from 1-n, the length of the list) phonemes should make up the last piece, such that the score of that piece plus the score of the rest of the message (via a recursive call) is maximized?” As part of this, each sublist of phonemes is passed into a function that finds the best piece it can become.
A “piece” is one of three things: Image, Word, or Syllable. The function to find the best piece for a given list of phonemes first checks every image we have to find the one with the best matching score (matching scores will be described next). If the best matching score is above a certain threshold, it’s deemed good enough and returned as an Image piece. If not, we say this list of phonemes is un-Rebusable. If the list contains exactly the phonemes from a full word in the original message–no more, no less–then it is a Word piece and returned as the word it originally was (this is the default when the pronunciation dictionary doesn’t know the word). Otherwise, the list is a Syllable piece and a string is generated to represent how those phonemes should be pronounced. I do this rather than using the letters from the original word because it is more readable in many cases (eg. if “junction” became a “Junk” image and then “ti” and then an “On” image, the “ti” would likely not read right. So in my code I turn it into “sh”).
To find the matching score between a word and an image, we get the phoneme list for the image. Then we do a second Dynamic Programming algorithm which tries to find the best possible score to assign these two lists. The first sounds of each list can either be matched with each other, in which case we add to our total the sound-similarity score (explained below) for these two sounds, or one of the lists’ first sound can be skipped, in which case we match it with the “empty sound” and add the sound-similarity score for that sound and nothingness. This repeats recursively until we hit the end of the list.
The sound similarity score is more or less a hard list of scores I made for each pair of sounds in the CMU Pronouncing Dictionary. The better the score, the better the match. In general, sounds that only kind of match (“uh” and “ah”) have slightly negative scores, as we want to avoid them, but can accept them, while sounds that really don’t match (“k” and “ee”) have very negative scores. Soft sounds like “h” have only slightly negative scores for matching with nothingness (ie. being dropped). Perfect matches have very positive scores (but not as positive as the non-matches are negative), and voiced/unvoiced consonant pairs (“s” and “z”, or “t” and “d”) are slightly positive because these actually swap out remarkably well.
Okay. That’s it. The bottom of the stack of function calls. After all the results of all the functions get passed up to the top, we are left with the best-scoring list of pieces. We then render these one at a time: words are simply inserted as text. Syllables are also inserted as text, with a plus sign next to them if they are part of the same word as an adjacent image piece (syllables are not allowed not to be next to image pieces–there would be no reason to do this). Images are looked up in my folder and then inserted inline as images.
While that was kind of complicated to explain, it’s mostly very simple: it just tries everything and picks the best thing. The only real “wisdom” it has comes from the sound-similarity scores that I determined, and of course the pronunciation dictionary itself.
Rebus Chat, as displayed in the final showcase.
Reflection
Before I get into my criticisms, I want to say that I love this app. I am so glad I was encouraged to finish it. I genuinely get a lot of enjoyment out of typing random sentences into it and seeing what kind of Rebus it makes. I have already wasted over an hour of my life doing this.
Rebus Chat is missing some basic features, including the ability to log in and choose which user you want to message (in other words, it’s basically one big chat room you can enter as one of two hard-coded “users”). In that respect, it is incomplete. However, the critical feature (the Rebus-ification tool) is pretty robust, and even just as a Rebus-generating app I think it is quite successful.
There are still some bugs with that part to be worked out too. The most important is the fact that some images in my catalog fail to render correctly, and others have too much or not enough padding, causing the messages to look messy (and, when two syllables from separate words get squished together with no space, inaccurate). But I also can and should spend a little more time fine-tuning the weights I put on each sound matching, because it’s doing some more than I would like (eg. it turns “Good” into “Cut” because g->c and d->t and oo->u are all considered acceptable) and others less than I would like.
Still, for how little it was tested, I am really happy with the version that was used in the class showcase. People seemed to have fun, and I scrolled back through the chat history afterwards and saw a lot of really interesting results. It was cool to have gotten so many good test cases from that show! Some of my favorites are below (try to decipher them before reading the answers 😀 ).
“On top of the world. But underneath the ocean.” = On // Top // of // the // Well+d. Button+d+Urn+eeth // the // ohsh+On
“Where is Czechoslovakia?” = Weigh+r / / S / / Check+us+Low+vah+Key+u
“The rain in Spain falls mostly on the plain.” = The // Rain // In // s+Bay+n // falls // Mow+stlee // On // th+Up // Play+n (I like this one as an example of a letter sound being duplicated effectively: “the plain” into “th+up” and “play+n”)
“I am typing something for this demo” = Eye // M // Tie+Pin // Sum+Thin // Four // th+S // Day+Mow
“Well well well, what have we here?” = Well // Well // Well // Watt // Half // we // h+Ear
“We’ll see about that” = Wheel // Sea // Up // Out // th+At
“What do you want to watch tonight?” = Watt // Dew // Ewe // Wand // Two // Watch // tu+Knight
“Golan is a poo-poo head” = Go+Lung // S // Up+oo // Poo // Head (I like this one as an example of two words merging: “a poo” into “Up+oo.” I was also pleased to find out that the pronunciation dictionary knows many first names)
Moving Forward
I would like to complete this app and release it on the app store, but the authentication parts of it are proving more painful than I thought. It may happen, but something I want to do first is make Rebus Chat into an extension for Messenger and/or email, so that I can share the joy of Rebus with everyone without having to worry about all of the architecture that comes with an actual app. This way, I can focus on polishing up the Rebus-ification tool, which in my opinion is the most interesting part of this project anyway. Whether I ultimately release the app or not, I’m really glad to have learned Android app development through Rebus Chat.
A conversational interaction with the hidden layers of a deep learning model about a drawing.
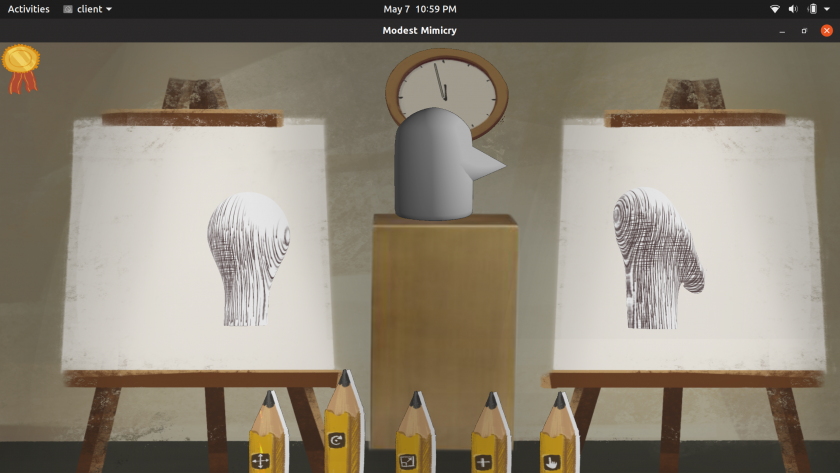
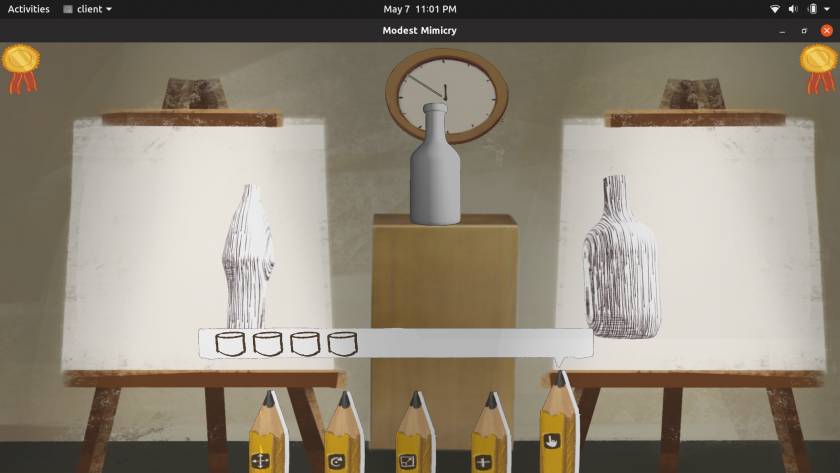
As an artist draws a dog, a machine gives friendly suggestions and acknowledgement about what parts are missing, have recently been improved, or seem fully drawn. It provides text mixed with visualization icons as well as continuous feedback in the form of a colorful bar graph.
The machine’s understanding of the world is based on the hidden layers of a deep learning model. The model was originally trained to classify whole entities in photos, such as “Labrador retriever” or “tennis ball.” However, during this process, the hidden layers end up representing abstract concepts. The model creates its own understanding of “ears,” “snouts,” “legs,” etc. This allows us to co-opt the model to communicate about dog body parts in half-finished sketches.
I was inspired to create this project based on ideas and code from “The Building Blocks of Interpretability.” I became interested in the idea that the hidden layers of machine learning contain abstractions that are not programmed by humans.
This project investigates the question, “Can the hidden layer help us to develop a deeper understanding of the world?” We can often say what something is or whether we like it or not. However, it is more difficult to explain why. We can say, “This is a Labrador retriever.” But how did we come to that conclusion? If we were forced to articulate it (for example in a drawing) we would have trouble.
Much of machine learning focuses on this exact problem. It takes known inputs and outputs, and approximates a function to fit them. In this case we have the idea of a dog (input) that we could identify if we saw it (output), but we do not know precisely how to articulate what makes it a dog (function) in a drawing.
Can the hidden layers in machine learning assist us in articulating this function that may or may not exist in our subconscious? I believe that their statistical perspective can help us to see connections that are we are not consciously aware of.
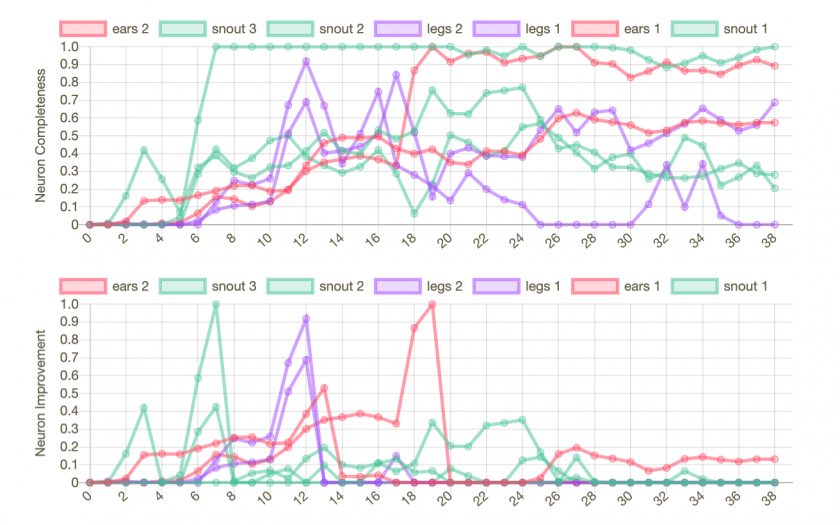
This project consists of a Python server (based on code from distill.pub) that uses a pre-trained version of Google’s InceptionV1 (trained on ImageNet) to calculate how much a channel of neurons in the mixed4d layer causes an image to be labeled as a Labrador retriever. This attribution is compared across frames and against complete drawings of dogs. Using this information, the machine talks about what dog parts seem to be missing, to be recently improved, or to be fully fleshed out.
This project is successful at demonstrating that it is possible to use real-time comparison of hidden layers to tell us something about a drawing. On the other hand, it is extremely limited:
The neuron channels are hand-picked, creating an element of human intervention in what might be able to arise purely from the machine.
The neuron channel visualizations are static, so they give little information about what the channels actually represent.
It only tells us very basic things about a dog. People already know dogs have snouts, ears, and legs. I want to try to dig deeper to see if there are interesting pieces of information that can emerge.
It is also not really a “conversation,” because the human has no ability to talk back to the machine to create a feedback loop.
In the future, I would like to create a feedback loop with the machine where the human specifies their deepest understanding as the labels for the machine. After the machine is trained, the human somehow communicates with the hidden layers of the machine (through a bubbling up of flexible visualizations) to find deeper/higher levels of abstraction and decomposition. Then, the human uses those as new labels and retrains the machine learning model with the updated outputs… and repeat. Through this process, the human can learn about ideas trapped in their subconscious or totally outside of their original frame of thinking.
Machine setup at exhibitionDrawings from the exhibitSample of the types of information provided by the UISummary of major events in the history of the drawing and what the machine detected at each timeCharts showing attributions for different channels over time and with a thresholded subtraction to detect events (both normalized with measurements from a canon of completed drawings)
Tweet: Competitively model/sketch against a friend using spheres, cubes, cones, and cylinders that seamlessly gloop into each other!
Overview: This is a two player game in which you do your best to “sketch” an example scene in front of you using simple shapes rendered with a hatching shader that you combine into more complicated scenes and forms. Through the power of raymarching and shapes rendered using math equations rather than meshes, shapes smoothly blend together as you translate, rotate, and scale the 4 available default shapes. A simple 2D image comparison algorithm decides if you or the other player is winning and will brighten or dim the spotlight on your easel based on how you’re doing. This game plays on the idea of going between 2D and 3D in sketching and modeling, the interplay between form and contour.
Narrative: What inspired me was a combination of “Real-Time Hatching” by Praun et al. and Sloppy Forgeries. I wanted to implement that shader mainly, and after thinking more, decided I wanted to make some kind of game that would make people think about the role of thinking in 3D for something like 2D drawing.
In the interest of time, I wrote this in the game framework I am most comfortable in: the base code James McCann uses for his Computer Game Programming course here at CMU. I relied on Inigo Quilez’s notes on raymarching and distance functions as well as his shadertoy implementation of raymarching primitives. I also took from this implementation of the hatching paper. Essentially, much of the technique behind this game involves me sticking together lots of other people’s code and doing my best to make it all work together. Despite that, I struggle a lot on getting raymarching working properly, with the scoring algorithm, and with lag between the two players that didn’t pop up as an issue until I finally ran it on another person’s computer instead of just running it in two windows on my own.
I suppose the success of this project I’d measure in terms of what I’ve learned about in terms of shaders (which was a main motivating factor of making this) and how well it serves as a fun game to play. I’ve kind of succeeded and kind of failed in both. I learned some stuff, although probably not as much as I would have if I’d implemented all shaders from scratch. Some people at the final show had fun with my game and complimented the idea and interesting experience. Personally I was proud of the fact that I’d made an UI of some kind that wasn’t just keyboard inputs for the first time ever, but I think my UI confused and frustrated a lot of people. The networking issues with lag also made the actual competition part of the game largely impossible during the show.
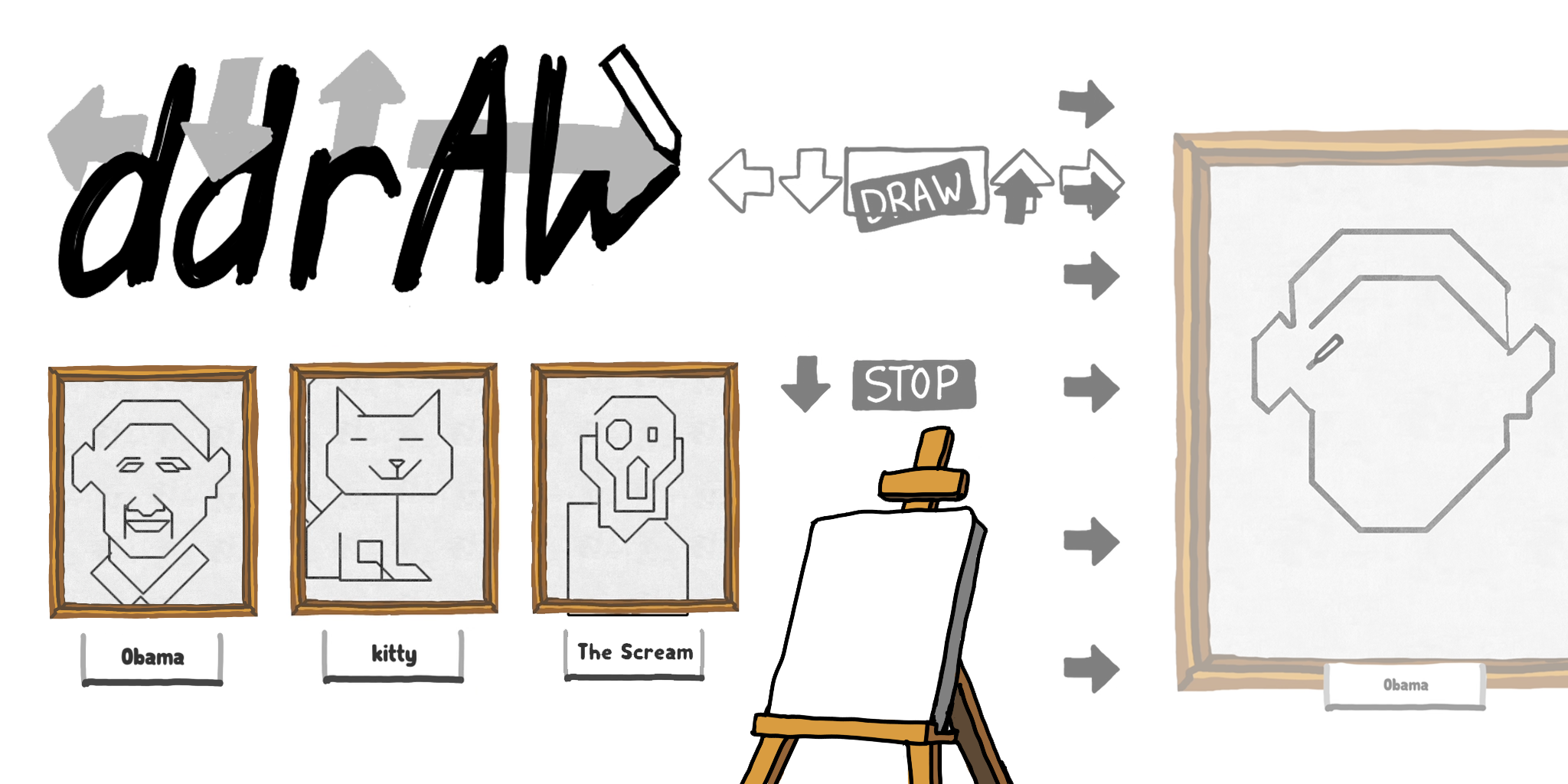
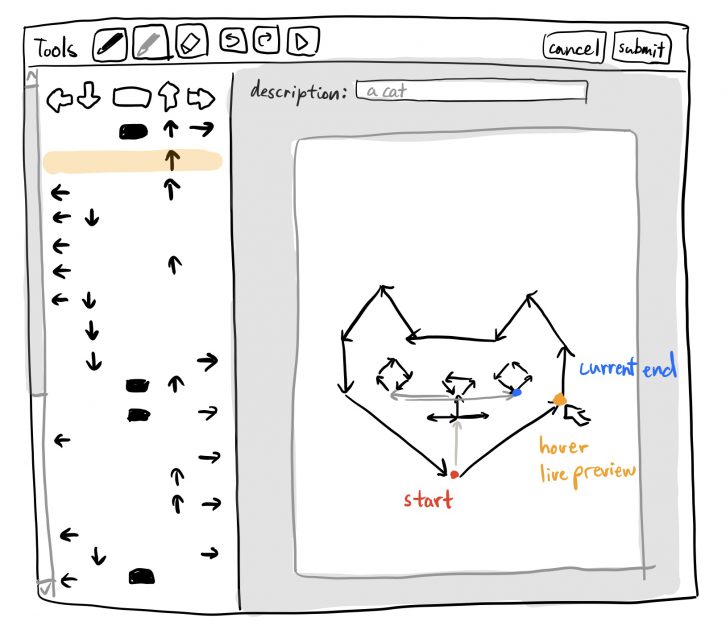
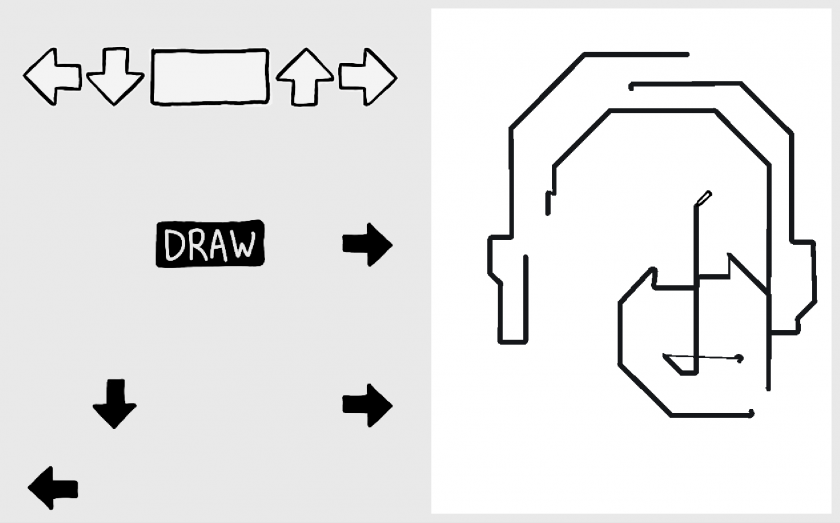
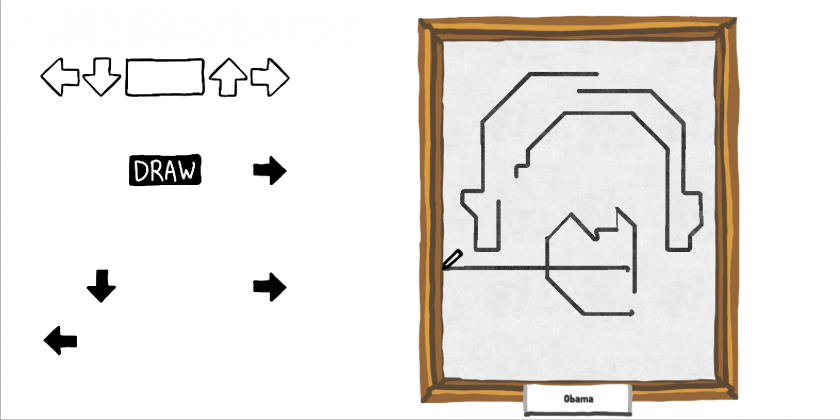
DDRaw is a drawing game based on Dance Dance Revolution.
Overview
DDRaw is a game that borrows the language of rhythm games to recontextualize drawing as an act of following instructions. Players must hit buttons as prompted at the right time in order to control a pen drawing on a canvas. The more accurately the player follows these instructions, the more closely they will reproduce the target image. In addition to the game mode, DDRaw includes a level creator that mimics the appearance of popular image editing software.
Narrative
The concept of DDRaw is drawing as instructions as opposed to drawing as an act of creativity. This dichotomy is embedded into my own identity as an artist, as I consider myself more of a “maker” than a “creator”. I combine an existing tradition of instructions-based drawing game-likes, such as Paint By Numbers and tracing games, with the strict timing demands of rhythm games, such as Dance Dance Revolution (DDR). The resulting juxtaposition of precise sketching creates opportunities for interesting mistakes and highlights the choice to avoid them. Missing one prompt can skew the entire drawing! Each gameplay level is created by an anonymous user using DDRaw’s drawing software-like level creation tool. By playing a level, a player is always indirectly imitating another player’s drawing process. Importantly, players are free to be both or to prefer one over the other, regardless of the distinction between the two roles. Key to the success of this interaction is that people of both roles mutually benefit from each other’s engagement.
The exhibition served as both a proof of concept and a playtest opportunity. On the conceptual end, the engagement of the exhibition visitors—particularly those already familiar with rhythm games—proved that the concept was viable on a broader scale. On the implementation end, observing what passersby noticed and struggled with provided helpful feedback on interaction improvements. I define a non-exhaustive list of improvements for each element of the game.
Player
Alternate control schemes. Arrow keys and one-handed setups were popularly demanded, especially among more experienced gamers.
Increasing the accuracy window by about 100ms. Currently, a hit is registered as on-time if it is within 200ms of the target timing.
Increasing the window for detecting simultaneous key presses and syncing this up with the accuracy detection. Currently, determining whether two key presses are simultaneous (and therefore whether to combine their directional vectors into diagonals) is independent of the accuracy detection on the UI.
A return to menu button to interrupt the level.
More feedback in general.
Level Creation
Provide an undo functionality with the arrow preview.
Remove the ghost line when draw is toggled off.
Make the title input box more obvious and prevent users from submitting works without a title.
Make the submit message more obvious.
Prevent multiple submissions of the same work. I am considering between detecting whether the canvas has changed or forcing the player back to the menu.
Either remove grid snapping or make it more obvious. Drawing-oriented players disliked not being able to line up points perfectly.
Menu
Make the scroll view more obvious.
Add functionality to delete specific drawings.
Add functionality to remix specific drawings. This would pair with forcing the players back to the menu upon submitting a new drawing.
In future expansions of this game, I hope to clean up the internals, improve usability, prototype new mechanics, and most importantly, publish DDRaw as a networked game with a database of drawings.
I’d like to acknowledge sheep for suggesting the name DDRaw.
















 From my sketchbook, notes on Ann Tarantino’s Watermark:
From my sketchbook, notes on Ann Tarantino’s Watermark:


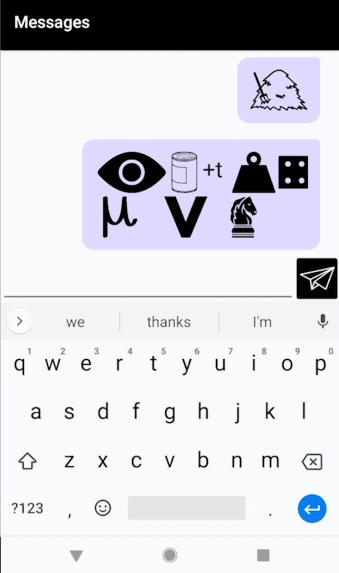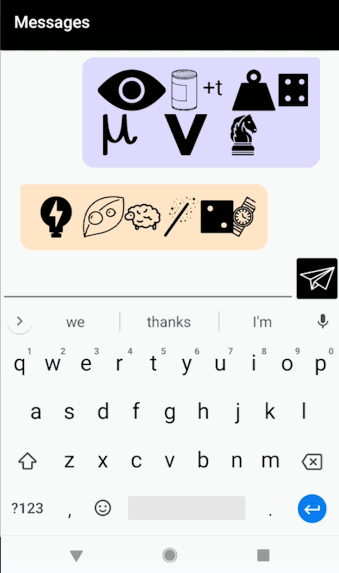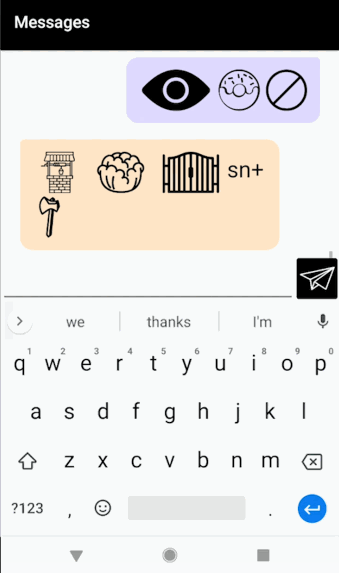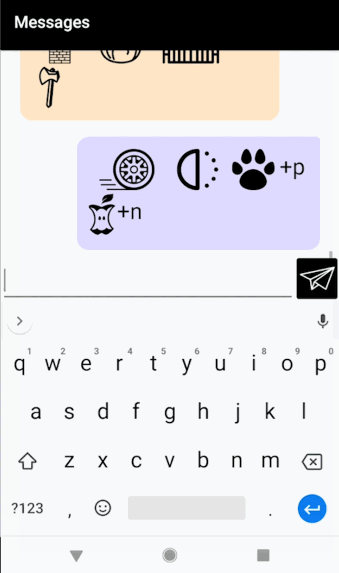


 “Carnegie Mellon University Tartan” = Car+Neck+ee / / m+L+on / / Ewe+nuv+S+u+tea / / t+Art+On
“Carnegie Mellon University Tartan” = Car+Neck+ee / / m+L+on / / Ewe+nuv+S+u+tea / / t+Art+On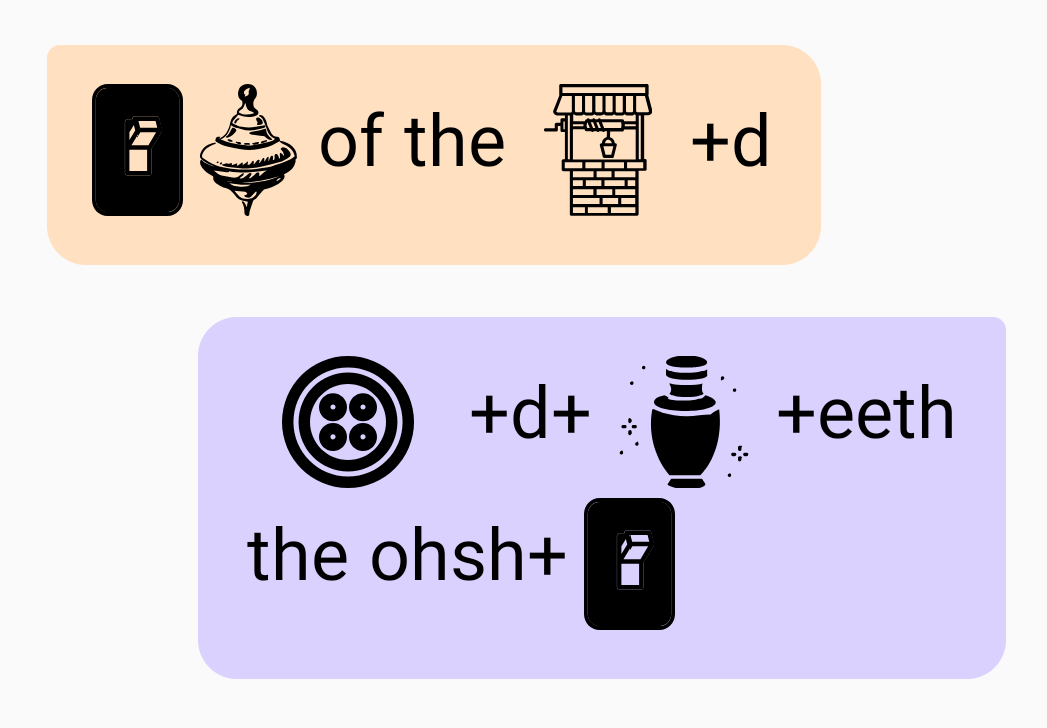 “On top of the world. But underneath the ocean.” = On // Top // of // the // Well+d. Button+d+Urn+eeth // the // ohsh+On
“On top of the world. But underneath the ocean.” = On // Top // of // the // Well+d. Button+d+Urn+eeth // the // ohsh+On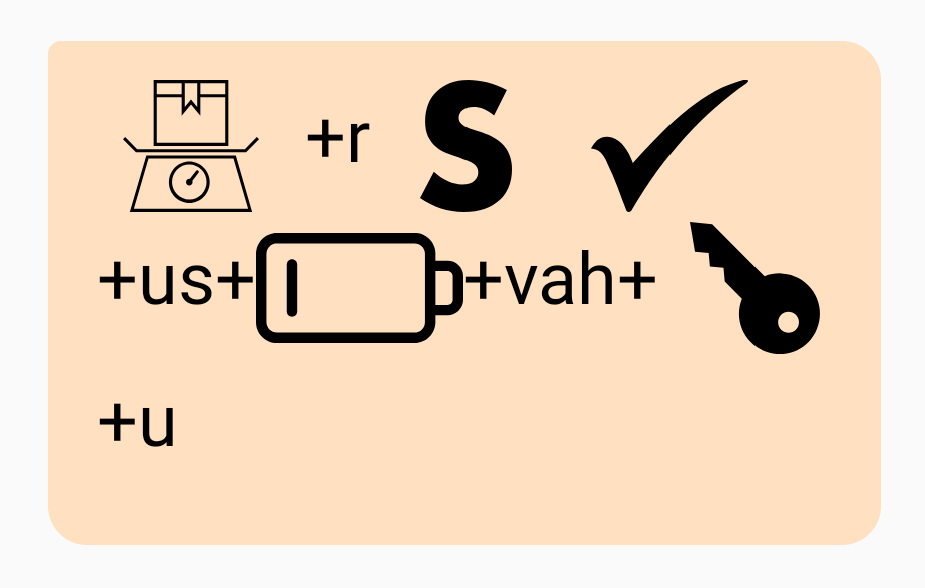 “Where is Czechoslovakia?” = Weigh+r / / S / / Check+us+Low+vah+Key+u
“Where is Czechoslovakia?” = Weigh+r / / S / / Check+us+Low+vah+Key+u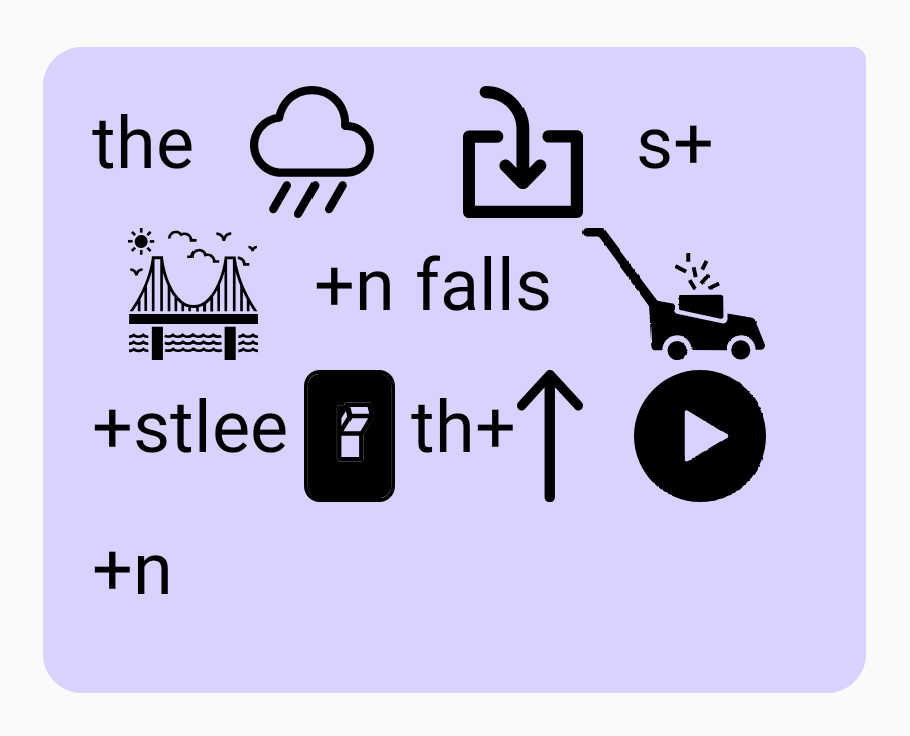 “The rain in Spain falls mostly on the plain.” = The // Rain // In // s+Bay+n // falls // Mow+stlee // On // th+Up // Play+n
“The rain in Spain falls mostly on the plain.” = The // Rain // In // s+Bay+n // falls // Mow+stlee // On // th+Up // Play+n “I am typing something for this demo” = Eye // M // Tie+Pin // Sum+Thin // Four // th+S // Day+Mow
“I am typing something for this demo” = Eye // M // Tie+Pin // Sum+Thin // Four // th+S // Day+Mow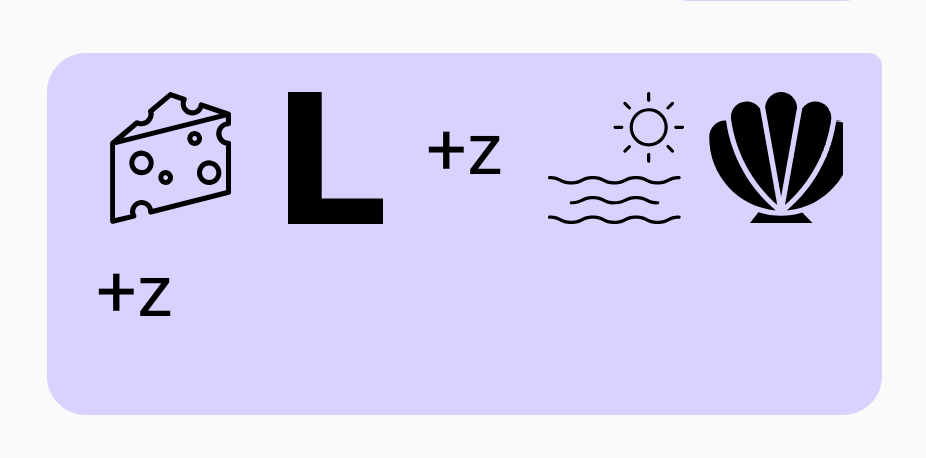 “She sells sea shells” = Cheese // L+z // Sea // Shell+z
“She sells sea shells” = Cheese // L+z // Sea // Shell+z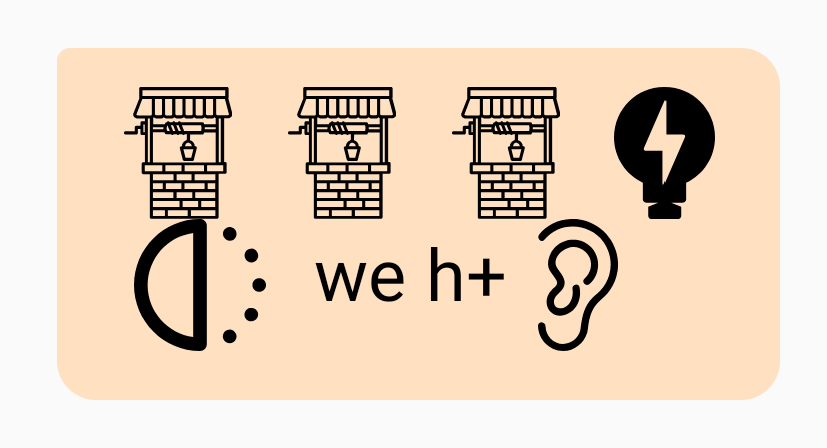 “Well well well, what have we here?” = Well // Well // Well // Watt // Half // we // h+Ear
“Well well well, what have we here?” = Well // Well // Well // Watt // Half // we // h+Ear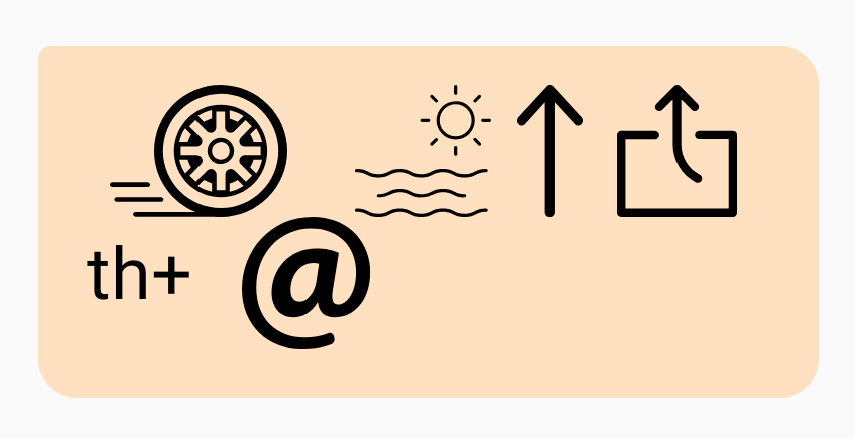 “We’ll see about that” = Wheel // Sea // Up // Out // th+At
“We’ll see about that” = Wheel // Sea // Up // Out // th+At “What do you want to watch tonight?” = Watt // Dew // Ewe // Wand // Two // Watch // tu+Knight
“What do you want to watch tonight?” = Watt // Dew // Ewe // Wand // Two // Watch // tu+Knight “Golan is a poo-poo head” = Go+Lung // S // Up+oo // Poo // Head
“Golan is a poo-poo head” = Go+Lung // S // Up+oo // Poo // Head