The goal I had for this project was to try to better understand the social structure of the subjects that Teenie Harris photographed by determining how many photos any pair of subjects appeared in together. I wrote a Python script using the Natural Language Toolkit (nltk) to find the different subjects and build a map to determine the subject overlaps. All of the Teenie photographs are descriptively titled with who and what appears in them, so I was able to use nltk to make a list of all the subjects for each photograph. Then, I assign each subject a unique id in order to build up a map containing the counts of pairs. Lastly, I go back through the map and for every pair with a count greater than a given threshold, I create an edge in a GraphViz graph, a Python graph abstraction and visualization library. The graph gets output as a ‘.gv’ file, which can then be interpreted and viewed in Gephi, an opensource visualization software.
The first time I ran the script, I used a threshold count of one so that all subject pairs were represented, resulting in close to 25,000 nodes, 112,000 edges, and a graph looking like this:

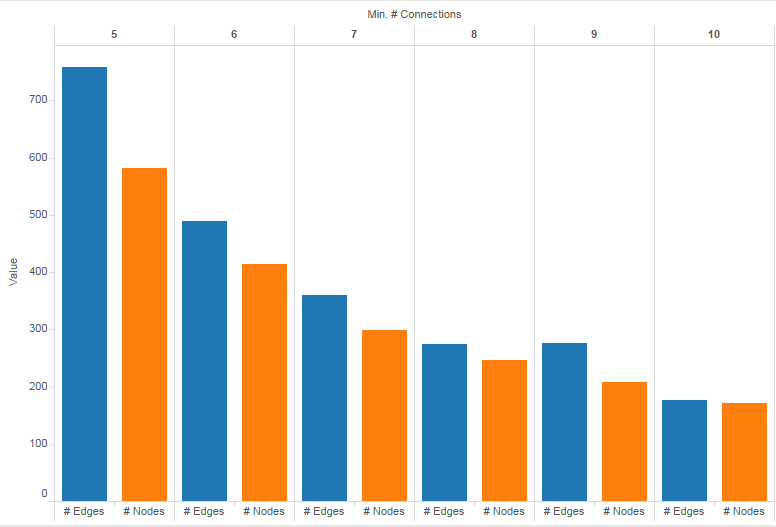
While visually this is obviously not very informative, the ratio of nodes to edges suggest that on average each subject is somehow linked to 4.5 others. I then did a series of script runs with thresholds varying from five to ten to check how consistent this ratio was. The graphs are displayed below, along with a bar chart depicting the ratio for each threshold.

There is still a lot of work to go in order to maximize the benefits of this script. Firstly, the nltk picks up false positives, such as the names of places. This could be refined to ensure that only names are found. Secondly, the visualization of the graph could be made much more informative by showing pair counts through line weight and by being made interactive.