So I went through a few different ideas, and I pulled three different sources before finding a dataset that really started to provoke in me questions that I hope the data can answer. One of the unused datasets—the transcripts for every This American Life I did put on Github. I think it’s a cool dataset, and I hope someone else is inspired by it and uses it for something. See the github repo.
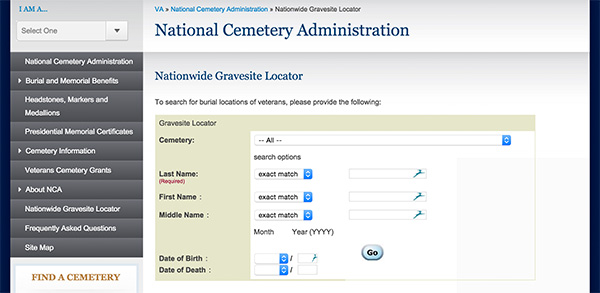
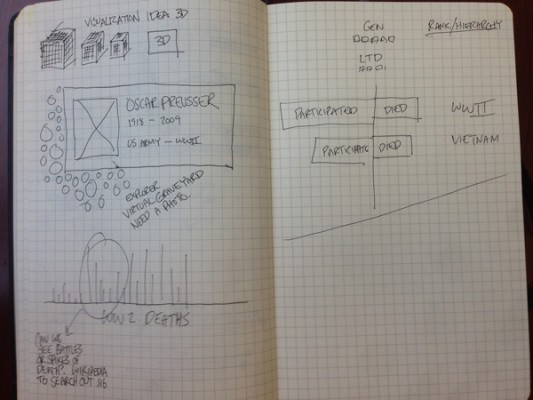
In last Thursday’s class, I was inspired by the visualization of grave stones. I was particularly inspired by Golan’s commentary on the lines of death and how they were traces of the deaths from World War II. My grandpa served in World War II, and with my grandma, I visited his gravesite a number of times since his death. He’s buried in a National Cemetery, and so there are literally thousands of lines of identical gravestones surrounding his grave. I wondered what a visualization of these mens’ gravestones would look like. Visually, it’d be monotonous, but the death-dates (and birth-dates) from all National Cemeteries would tell a story about both individuals and about the history of the United States.
I couldn’t find any dataset for veteran’s deaths and births, and even if I did, there must be millions of lines of data. But, the VA administration has a gravesite finder. The gravesite finder is basically a form that you submit with a name. It then returns every matching name, where they are buried, their birth and death, their rank, their service, and the wars they served in. EUREKA.
I created a datascraper (no Temboo choreos, sadly), that takes the 5,000 most common surnames in the US, submits a form to the VA site, then goes through each page of results and stores them locally. I also created a parser to transform the HTML into CSV. Because the VA’s HTML is not well written, the challenge of parsing isn’t trivial, and required me to make a few assumptions and guesses to categorize data. Taking the 5,000 most popular names means this will be a large dataset. I’ve scrape some 300,000 records and am finished with the 1,500 least-common names on my list. Finding ways to pair this list down without upsetting the descriptive power of the data will be a challenge.
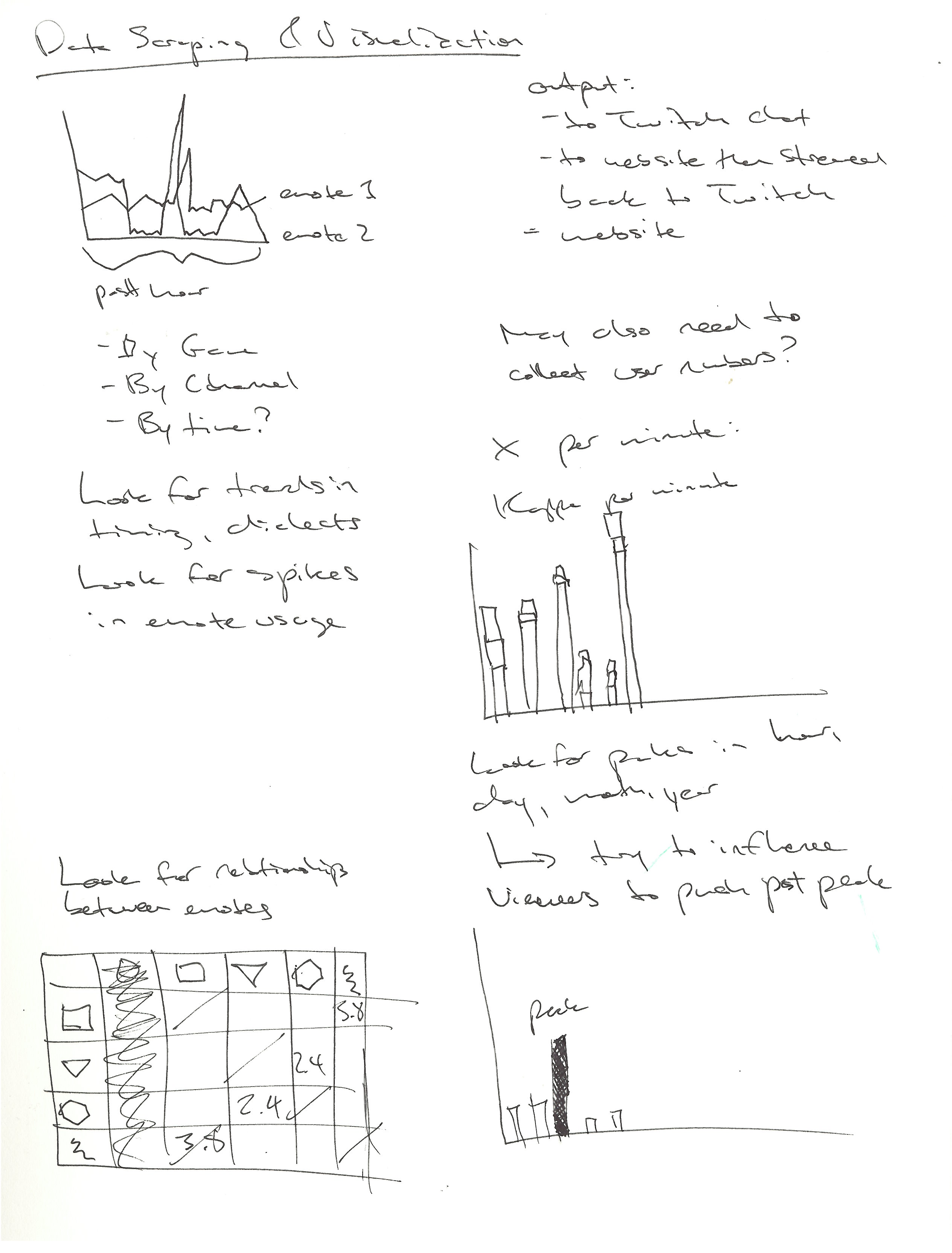
Here’s a sketch of some ideas for how to visualize this data.
Here is some data. Click on the image to download a small csv of the data.