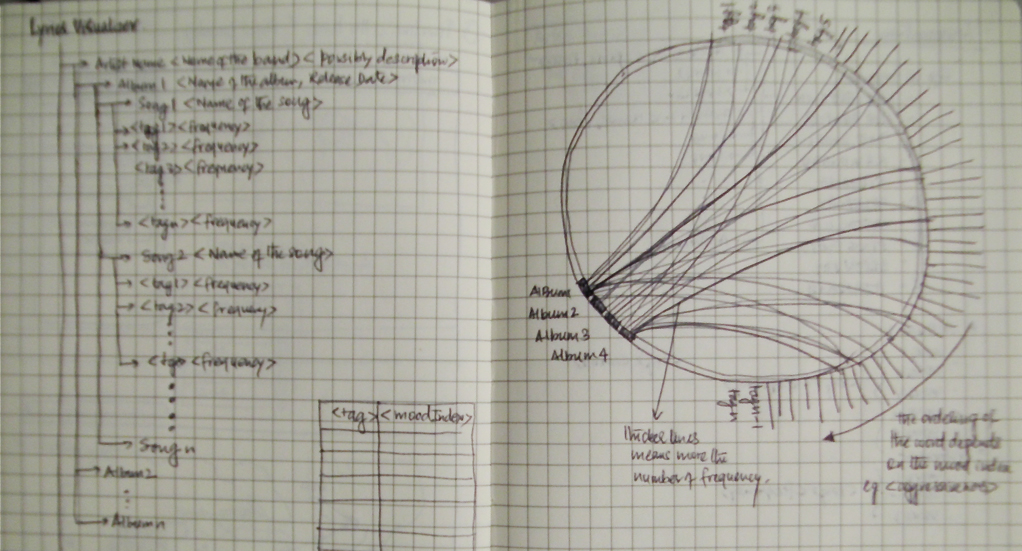
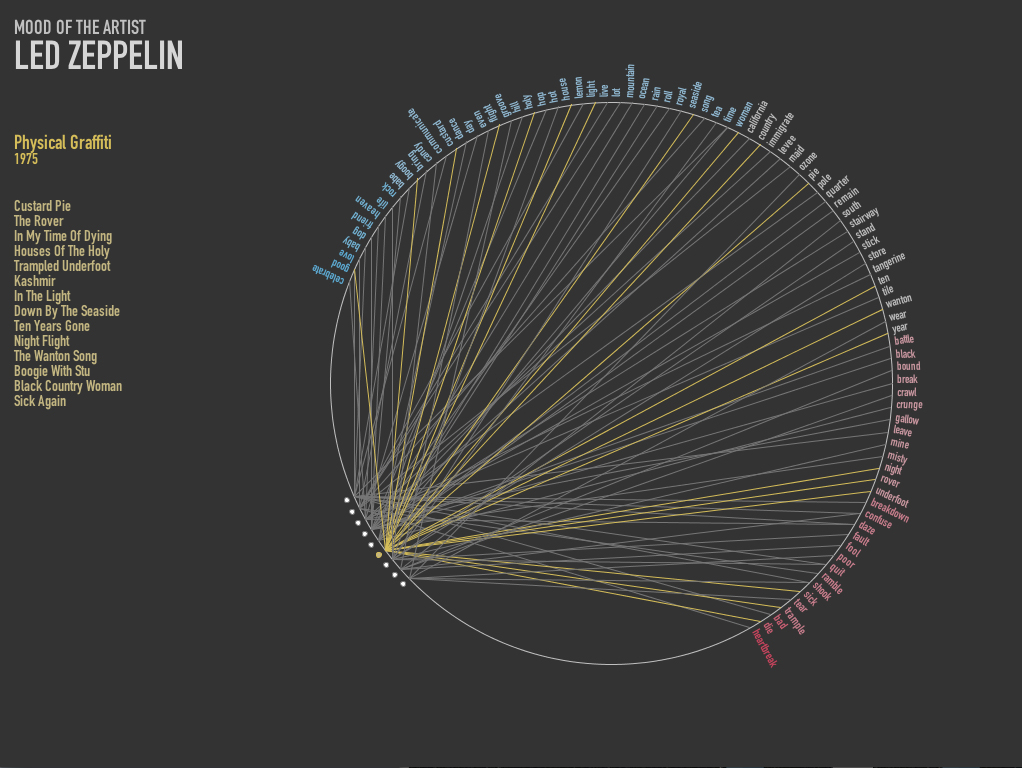
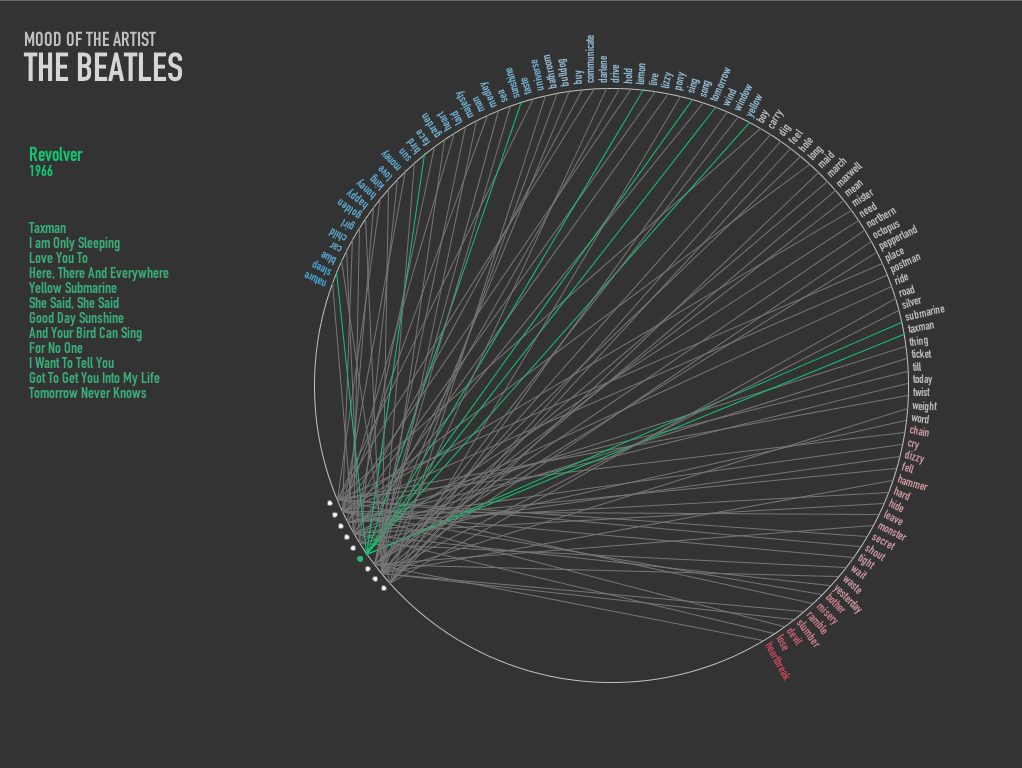
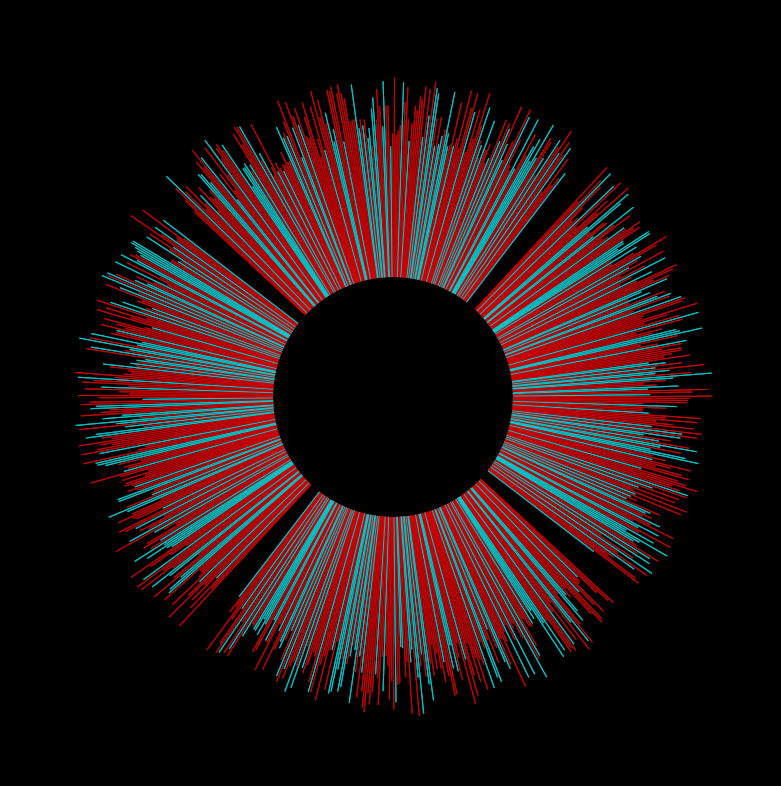
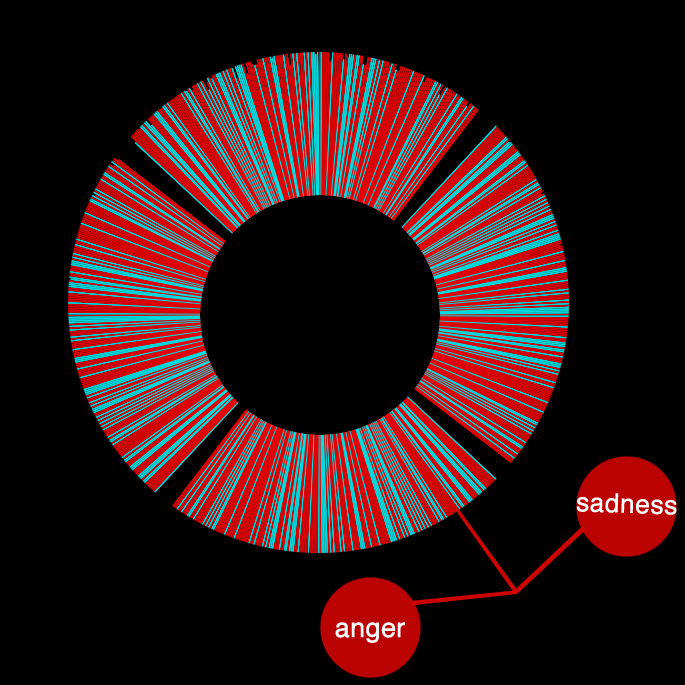
Project 2: Comedians & their Followers
Various awesome projects have explored how information filters through Twitter as a whole or how to characterize particular types of patterns, e.g., transit, again by searching through a large scope of tweets.
In this project, I took a step towards analyzing the interaction patterns around specific users, specifically, comedians.
Having been working with a robotic comedian that attempts to monitor audience reactions in real time, comedians that use twitter as a place to workshop their jokes provides data that could potentially continue to bootstrap that process. It is quantitative, public, and many, many comedians use it.
Do retweets, favorites and mentions reflect the success of particular jokes? Do they reflect the overall personality and interaction modes of that performer? How do they maintain rapport? Where do they divide their professional from personal? Do they ever lose their cool?
[vimeo=https://vimeo.com/36476603]
Please find some helpful resources to start playing with Twitter data in my previous Project 2 posts! It turned out some data was easier to scrape from twitter than others. Retweets were most supported by the twitter4j / Twitter API libraries.
The animations are adaptations of this openprocessing petaled flower: http://www.openprocessing.org/visuals/?visualID=48650. For readability, I do not re-include the visual adaptations in my code below, as I was mostly interested in sharing where my data came from.
You can also see in the extra bits of code (currently commented out), which include my first efforts at tracking down information about the whens and whos of individual retweets to extend the overall count. The next tricky bit is to track down responses to a tweet, which is quite convoluted as its not built directly into the API (again, take a peek at the code for the method I’m testing), happy to share with you my continued discoveries!
<pre lang=””java””>
// Runtime options
boolean part1 = true;
boolean part2 = false;
int numTweets = 10;
String who = “robdelaney”;
// Inits
ArrayList recentTweets = new ArrayList();
void setup(){
size(550,550);
background(255);
smooth();
//Credentials
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setOAuthConsumerKey(“*******************”);
cb.setOAuthConsumerSecret(“*******************”);
cb.setOAuthAccessToken(“*******************”);
cb.setOAuthAccessTokenSecret(“*******************”);
Twitter twitter = new TwitterFactory().getInstance();
Query query = new Query(“@”+who); //userid = 22084427 for ref
query.setRpp(5);
try{
//PART 1: FIND COMEDIAN STATUSES
if(part1){
println(“in part 1”);
// Get statuses
Paging paging = new Paging(1,numTweets);
List<Status> statuses = twitter.getUserTimeline(who, paging);
// For each status…
for(int i = 0;i<statuses.size();i++){
println(“in statuses”);
Status s = statuses.get(i);
// Get characteristics (text, time created, id)
String msg = s.getText();
Date d = s.getCreatedAt();
long id = s.getId();
println(“Tweet #” + i+” at” + d + “: ” + msg);
//Get total retweet count of that status
long rt_count = s.getRetweetCount();
println(“Total Number of Retweets: “+(int)rt_count);
//Add tweet to list
RecentTweet recent = new RecentTweet(msg, (int)rt_count);
recentTweets.add(recent);
/*
//For each retweet find time and username
for (int i = 0; i < retweets.size(); i++) {
Tweet rt = (Tweet) retweets.get(i);
String rt_user = rt.getFromUser();
Date rt_date = rt.getCreatedAt();
println("Retweet by " + user + " at " + d);
//Find Related Results: replies and more
//SADNESS: seems not to be a supported method, gives an insufficient authentication credentials error
//RelatedResults replies = twitter.getRelatedResults(id);
//println(replies);
println(" ");
}
}
// PART 2: MATCH UP @-REPLIES TO SPECIFIC COMEDIAN TWEETS
if(part2){
QueryResult result = twitter.search(query);
ArrayList replies = (ArrayList) result.getTweets();
for (int j = 0; j < replies.size(); j++) {
Tweet r = (Tweet) replies.get(j);
String r_user = r.getFromUser();
String r_msg = r.getText();
Date r_date = r.getCreatedAt();
long r_id = r.getId();
Status r_status = twitter.showStatus(r_id); // reply status
long orig_id = r_status.getInReplyToStatusId();
Status o_status = twitter.showStatus(orig_id); //original (replied-to) status
println("Tweet by " + r_user + " at " + r_date + ": " + r_msg);
println("Reply to: "+o_status.getText());
}
}
*/
}
}
}
catch (TwitterException te) {
println("Couldn't connect: " + te);
}
println("and we have stored "+recentTweets.size()+" tweets");
}
void draw(){
//do stuff
//println("in draw");
}
class RecentTweet {
private String msg;
//private Date date;
private int numRTs;
RecentTweet(String m, int rts) {
msg=m;
//date=d;
numRTs=rts;
}
public String msg() {
return msg;
}
// public Date date() {
// return date;
// }
public int numRTs() {
return numRTs;
}
}
</pre>