EliRosen-Project2-CivilWarVis
For this project I chose to visualize the battles of the civil war. Aside from the fact that I have always loved to study the civil war, I found this to be an interesting data set because it has so many different dimensions: battle names, geographic information, dates, commanders, casualties, et cetera. The data was scraped using a python script from the website www.civilwar.com. Thanks to Asim Mittal for all the help with python. I thought at first to visualizes the data on a map as a kind of animation of the civil war but found that that had actually already been done.
My next intuition was to use a timeline. I used this early processing sketch as a way to see what the data would look like on a timeline with the battles sized by total casualties;

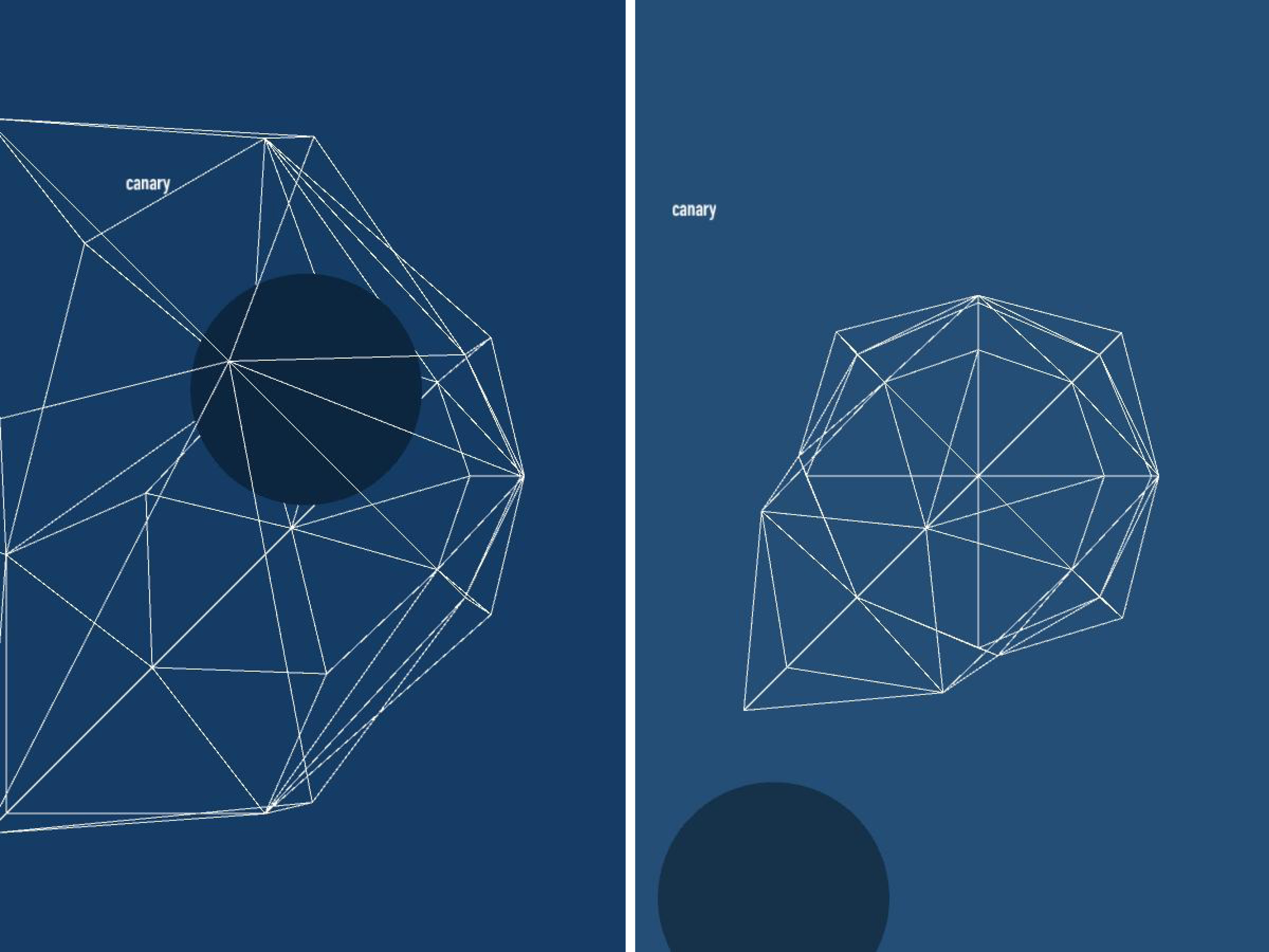
I liked this direction but decided I had to add a second element to make the project more interesting. I toyed with the idea of having an animated chronological visualization where as a playhead reached a battle it would explode, scattering two colors of particles that would represent the casualties on each side. Instead I decided to focus on the commander data to try to show where commanders had fought throughout the war. I drew connections for all commanders to all their battles. I found this to be much too cluttered and decided instead to introduce a selection mechanism so that only one battle and set of commanders was in focus at any one time. The user can step through the battles with the right and left arrow keys. Below is the result:
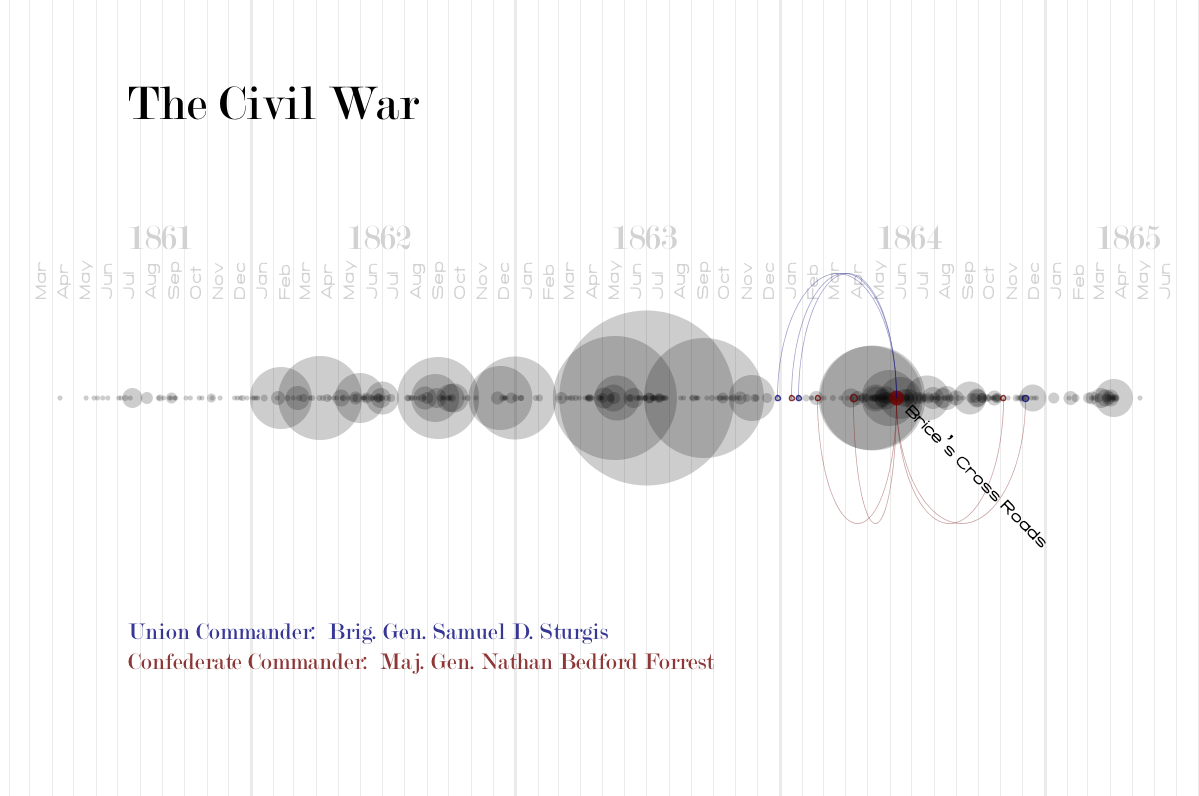
At this point I just added the legend to finalize the piece:
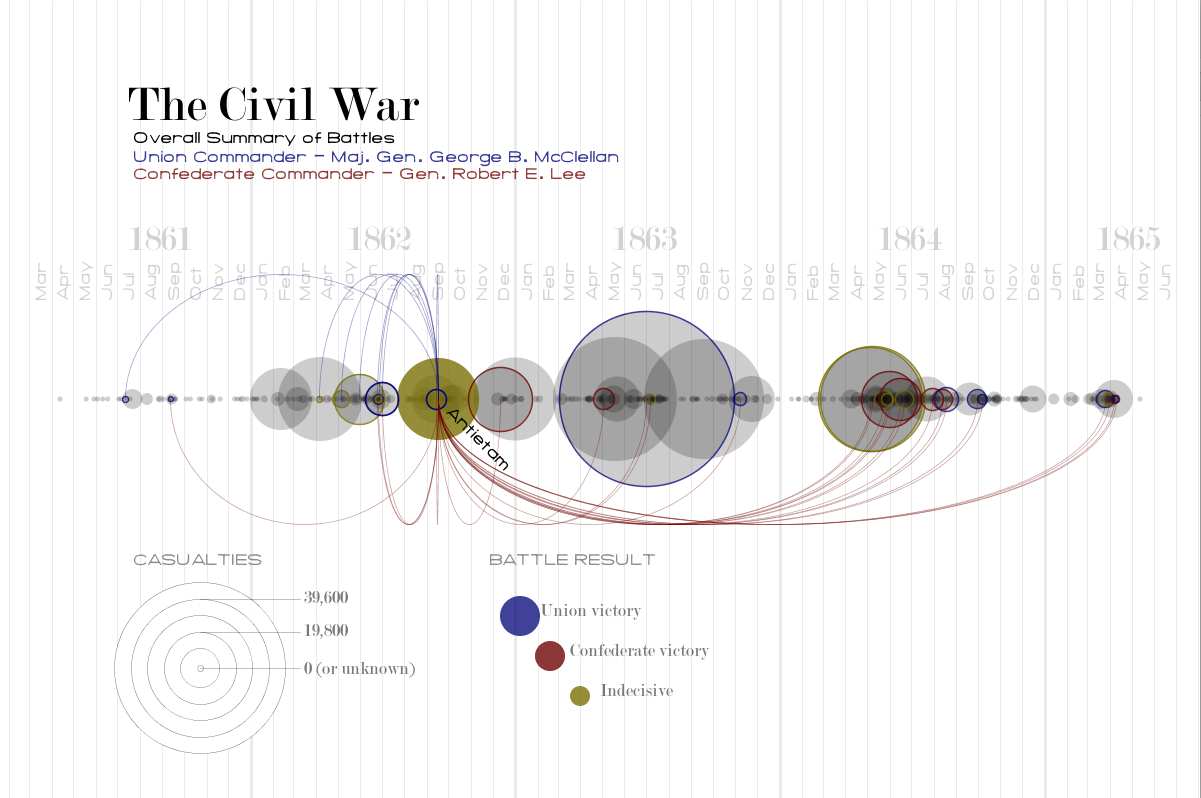
I’m pretty happy with the result. I think it provides some interesting high-level information about when commanders fought and how they fared. It also reveals some instances where commanders faced off in multiple battles. It is also interesting to see how the war escalated and then petered out. The visualization does not however give good insight into individual battles. The exact number of casualties is hard to discern and there is no information on the size of the armies that faced off. The areas where many battles occurred in rapid succession become very difficult to read and the dense areas do not read as being as dramatic as a single large battle even though the total casualties may be greater. It might be nice to have a supplemental tool to target a span of time and see the total casualties on each side.
Here is a video of the visualization as I step quickly through the battles of the war:
[youtube https://www.youtube.com/watch?v=zaA2Px_29dc&w=640&h=360]
Here is the live processing applet:
Select the applet and use your left and right arrow keys to step through the battles.