What happens if you compare the language of government with the language of the rest of the culture? Well. You probably make a mess…  Where am I coming from?
Where am I coming from?
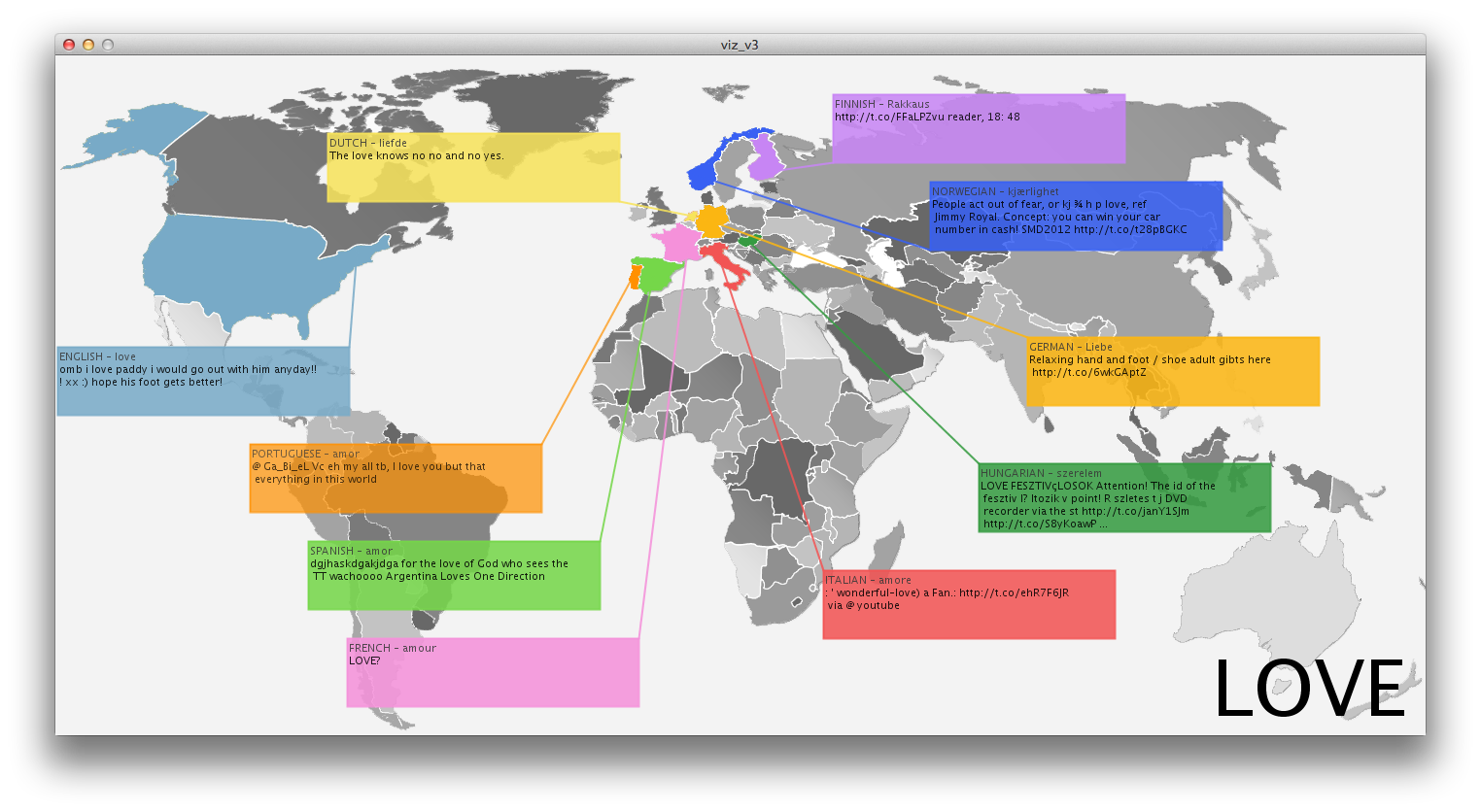
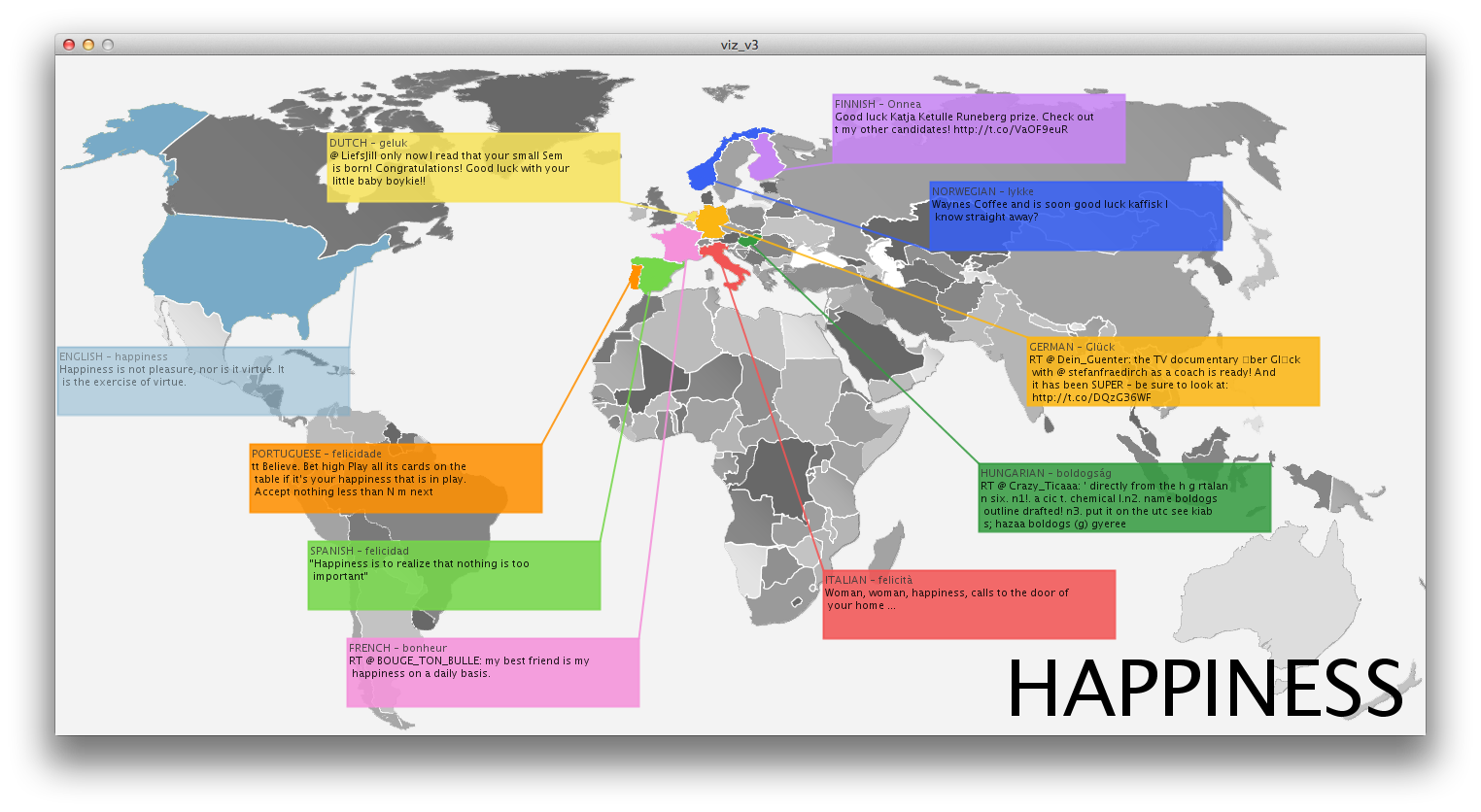
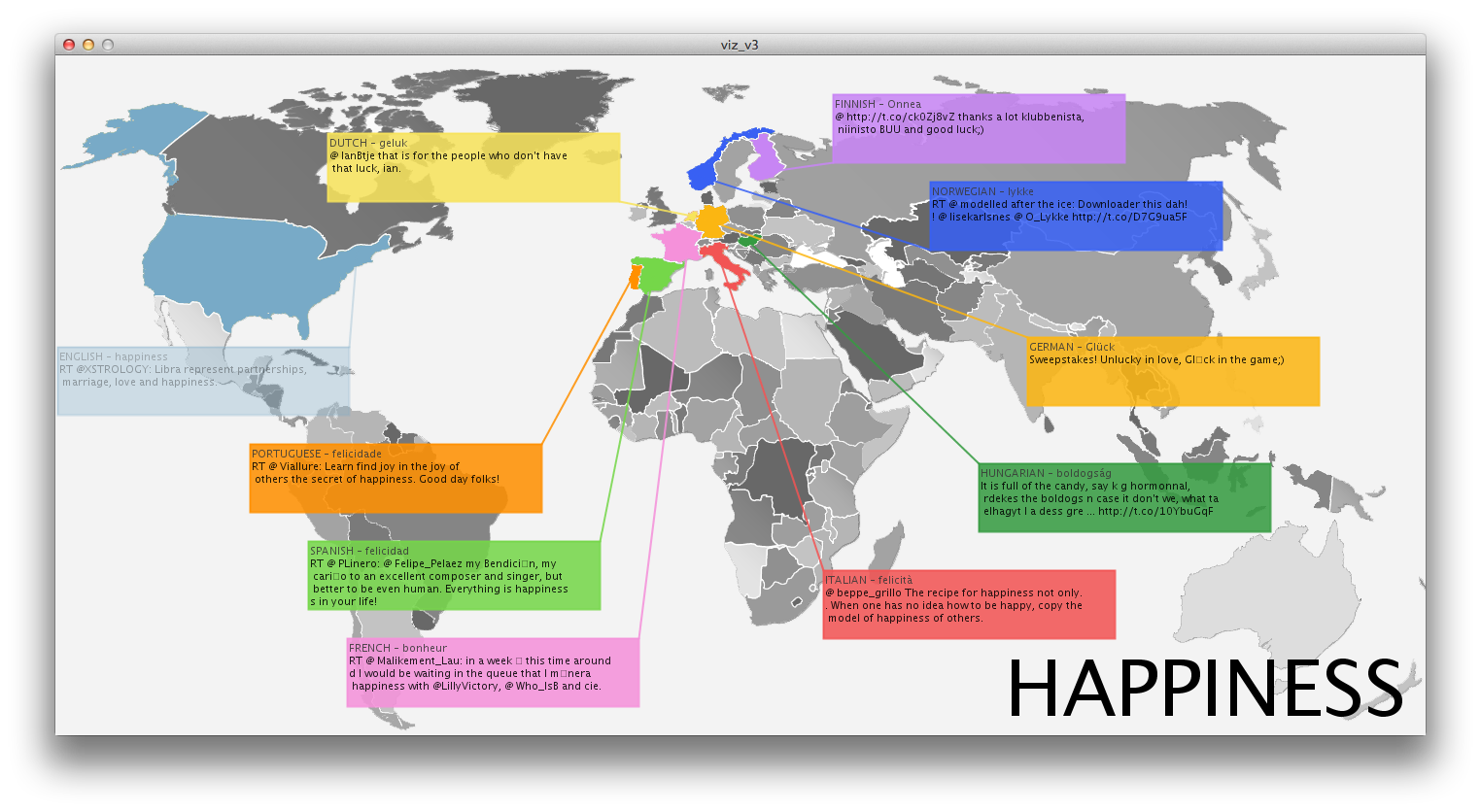
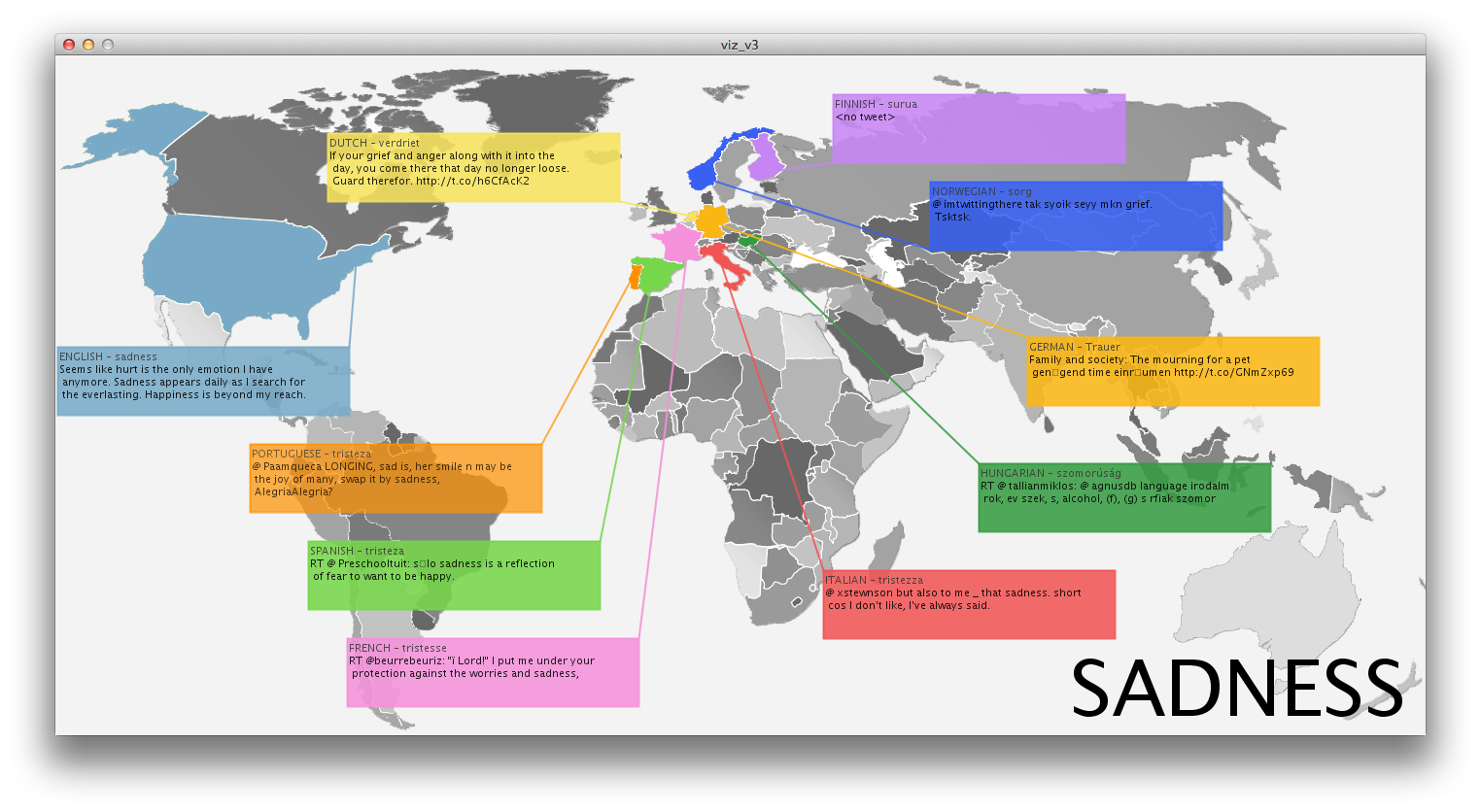
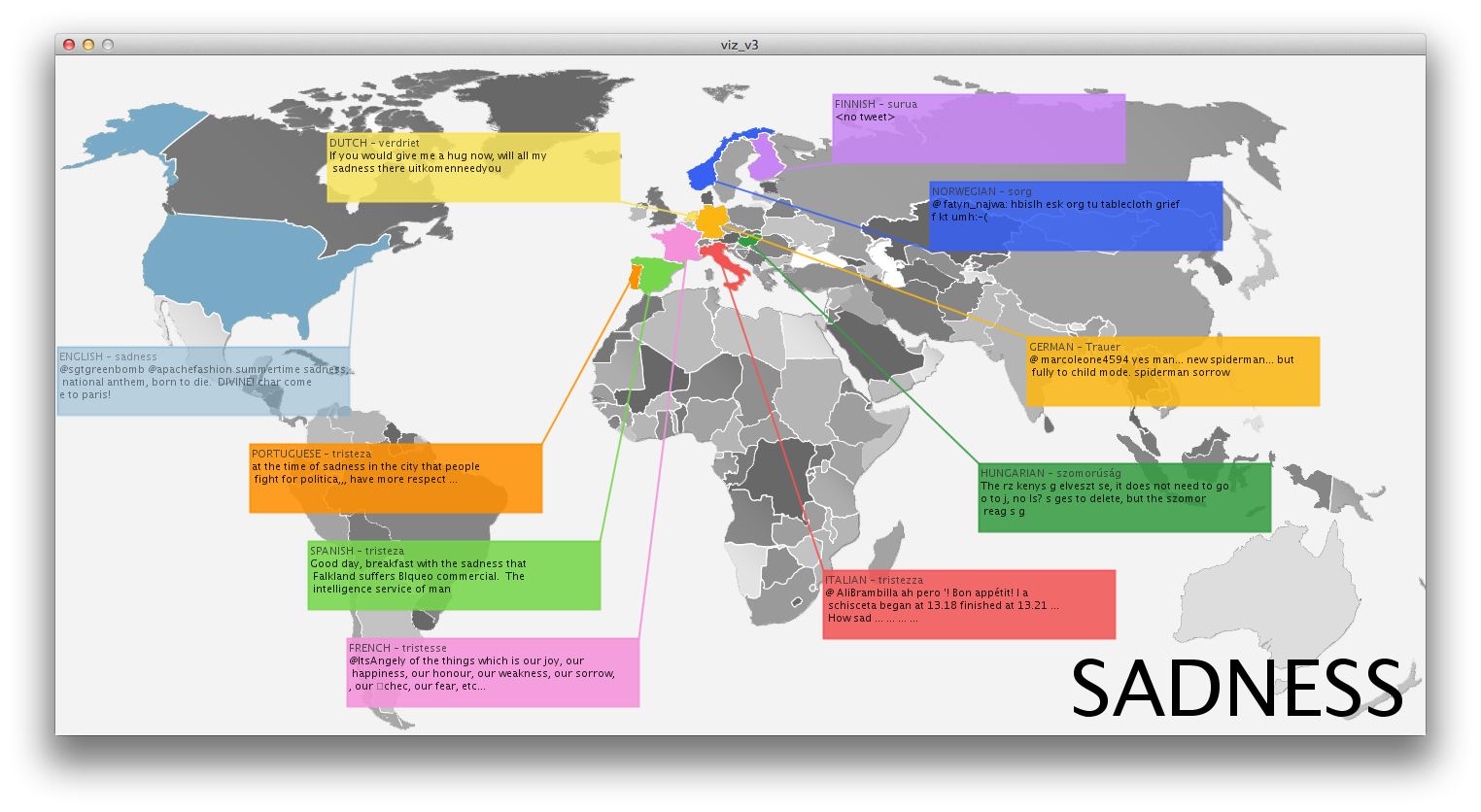
I was initially interested in trying to visualize DISINFORMATION while the world is ecstatic about new ways to visualize NON-DISINFORMATION, a.k.a INFORMATION. The hypothesis was that for every vetted, scientific, evidence-based government study conclusion, there exists an opposite conclusion with the same backing.
How and what came of it?
I initially thought that I would somehow try to visualize point-counterpoint in government officials perspectives. Global warming is a fact./Global warming is a theory. That kind of thing. That boiled down to the question, is it right and wrong or is perception truly reality. At that point I realized I could use the language of government as a cultural probe and perhaps find a relationship between their words, and ours. If perception is reality, then a representative government’s perceptions may be revealed by filtering their own language through the ultimate cultural barometer: YouTube…Government + YouTube =…you get the point.
What’s the process?
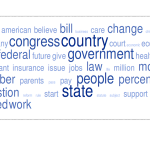
First, data. Transcripts of Executive, Legislative and Judicial proceedings were cooked down using tagCrowd.com. It’s a classic word cloud generator that boils thousands of words down to 600 words down to this: 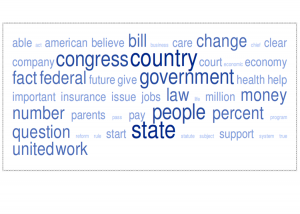

Inspired by Dan Shiffman’s text mirror, the words were put into an array then used to search YouTube and the first (non-promoted, non-featured) video was loaded into an array in processing. The comparison titles looked like this, Gub’ment words on the left…
able — God is Able
act — How to Act Good w/Hugh Jackman
american — Americans are NOT stupid – WITH SUBTITLES
believe — Cher – Believe [Official Music Video] [HQ]
bill — IPHONE BILL
business — Entrepreneur’s Mission Statement
care — Kid Rock-Care Music Video
change — deftones-change
clear — Cybotron-Clear
chief — Chief – Night & Day (2010)
company — Company( the Musical): Part 1
congress — C-SPAN: Stephen Colbert Opening Statement
country — Jason Aldean – She’s Country
court — Pepsi – King’s Court Super Bowl
economic — Economy key in Nevada Republican caucus
economy — Keiser Report: Starving the Economy (E243)fact —
federal — Federal BMX – Cologne
future — Future – Magic ft. TI
life — The Life (An anthropology graduate student (Denise Richards), guided by her prostituting neighbor (Darryl Hannah)…)
number — 10 Little Numbers
parents — PARENTS SUCK!
pass — PASS THIS ON
pay — Soulja Slim – I’ll Pay For It
people — Foster The People – Pumped Up Kicks
percent — Percent of a Number – YourTeacher.com – Math Help
program — The Program – Alvin Mack
give — Pitbull – Give Me Everything ft. Ne-Yo, Afrojack, Nayer
government — Alex Jones: US government spies on everybody
health — HEALTH :: DIE SLOW :: MUSIC VIDEO
help — Help! in the Style of “The Beatles” with lyrics (no lead vocal)
important — The Most IMPORTANT Video You’ll Ever See (part 1 of 8)
insurance — Auto Insurance
issue — Escape the Fate – Issues
jobs — Steve Jobs’ 2005 Stanford Commencement Address
law — LA Law theme
million — Nipsey Hussle “A Million” (Music Video)
money — Money – Pink Floyd HD (Studio Version)
question — System Of A Down – Question!
reform — Social Security Reform Bill Encourages Americans To Live Faster, Die Younger
rule — Take That – Rule The World – Official Music Video
start — DEPAPEPE – START(PV)
state — The State MTV: Louie “I Wanna Dip My Balls…”
statute — Lesson4- Society and Statutes Part 1.mp4
subject — English Grammar & Punctuation : What Is a Subject-Verb Agreement?
support — tech support
system — System Of A Down – Chop Suey!
true — Spandau Ballet – True
united — United Breaks Guitars
work — Ciara featuring Missy Elliott – Work ft. Missy Elliott
Some favorites…
The rest looked something like this…
[youtube https://www.youtube.com/watch?v=CEyt9PEHHwY]
There are more questions raised here than answers and without a brief description the visualization doesn’t clearly explain what the viewer is seeing. Admittedly, I chose to use this brief study to explore programming skills I hadn’t previously undertaken. And not until I had gotten through them did I begin to explore the potential visual output. Even then, I was more interested in the vis than the info, but limited by my programming skills.
One interesting observation about the data, however, is that the language of government tends to translate into entertainment for YouTube-ers. Fully 54% of the videos were music videos for recording artists. Only 10%had anything to do with matters of government and three of those were jokes or conspiracy theories. According to YouTube, the government looks like a song-and-dance.
/*iacd 2012, Zack Jacobson-Weaver copywrite 2012
youTube files:
https://www.youtube.com/watch?v=_2exW2cUdC4
https://www.youtube.com/watch?v=Ul86UVXqpxs
https://www.youtube.com/watch?v=UdULhkh6yeA&feature=fvst
https://www.youtube.com/watch?v=J-ywH_1rUFA&feature=pyv
https://www.youtube.com/watch?v=2Ccjjt5OihM&ob=av3n
https://www.youtube.com/watch?v=ZL4MGwlZuAc
https://www.youtube.com/watch?v=fGqiBFqWCTU
https://www.youtube.com/watch?v=XLPlfODCBlI
https://www.youtube.com/watch?v=JJsd_Cvk_rw
*/
import processing.video.*;
int videoScale = 14;
int cols, rows, pCharCount, nextShuffle, b,c;
int frames =5;
int nextFirstLetter=0;
String [] titles;
String [] finalWords;
int [] startChars = new int [100];
Movie [] videos = new Movie[9];
String chars = "";
void setup()
{
size(480, 360, P2D);
cols = width/videoScale;
rows = height/videoScale;
//frameRate(24);
b = 0;
titles = loadStrings("youtubes.txt");
finalWords = loadStrings("Final.txt");
for (String s : finalWords)
{
chars = chars + s + " ";
}
for (int i=0; i nextShuffle)
{
nextShuffle += frames;
pCharCount = (pCharCount + 1) % chars.length();
}
int charcount = pCharCount;
for (int j=0; j< rows; j++)
{
for (int i=0; i < cols; i++) { int x = i*videoScale; int y = j*videoScale; if (charcount >= startChars[b] && charcount < startChars[b +1])
{
fill(255);
}
else
{
fill(255,45);
}
textSize(20);
text(chars.charAt(charcount),x,y);
charcount = (charcount + 1) % chars.length();
}
}
}
void keyPressed()
{
if (keyPressed && key == ' ' )
{
b = (b + 1) % videos.length;
}
} |