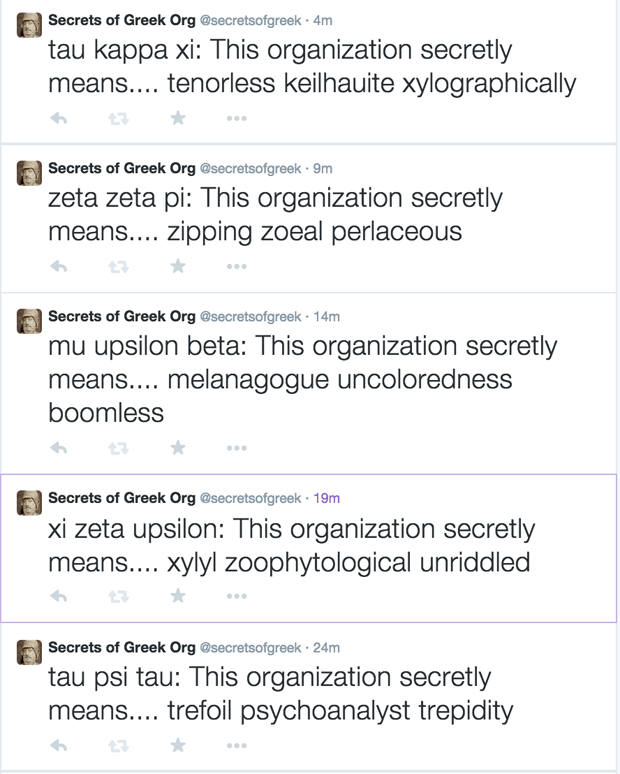
Say hello to @LimerickTweets. It’s a bot that retweets some of the latest tweets in the form of limericks.
I'm not a fan of facial hair
oh okay cool see if I care
— Sophie (@__sophs) March 1, 2015
I only live twice
— JesusChrist (@FakeShemetov) February 27, 2015
I'm craving fried rice.
— ϻ.thor (@trvpmt) February 27, 2015
I respect his intentions there.
— Nino (@NinoBeige) March 1, 2015
I’ve been interested in generating limericks for a couple years now. When I was new to programming and NLP concepts, it was one of the first things I thought about doing. After all, limericks are pretty easy to think about computationally: you have a just need to identify three 8/9-syllable phrases that rhyme and a 5-syllable rhyming couplet — with thousands of lines of data, these wouldn’t be all that hard to find. It also seemed like the results would be interesting! Short tweets, the kind that would be only 5 or 8 syllables, are often ambiguous, emotive and poetic. it seemed like stringing several together might result in a piece of poetry that was able to suggest real, genuine sentiment.
Naturally, it seemed like a limerick bot (particularly a twitter limerick bot) would be an obvious and overdone project. I checked, however, and while there are a couple of GitHub accounts with “work in progress” bots, I couldn’t actually find one that had made it to the web. It seemed like the perfect opportunity to build one myself and see what happened.
Implementation
I built my bot in Python, using the Twitter Temboo API to scrape recent tweets. It quickly accumulated several thousand and updates regularly. Using NLTK and the CMU Pronouncing Dictionary (of course), I assigned each one a syllable count and looked up its pronunciation so that I could find rhymes. Finding the best set of three words that rhyme with one another is actually kind of an interesting problem. How do you figure out which three words in a dataset of one thousand rhyme best? My solution was to hash tweets into buckets based on syllable-count and the pronunciation of the last word in the tweet, starting with the first vowel of the word. For instance, “cat” translated to “K AE T” which hashed into the “AE T” bucket — just like “sat” (“S AE T”) or “drat” (“D R AE T”). It wasn’t going to match longer words to rhyme with the ends of sentences, like “go in” and “cohen”, but I felt really dirty with every bulky data structure I thought of. There are a lot of tweets, the words used in them aren’t big, and so I wasn’t particularly worried about not matching every possible rhyme. To post, the program would choose one 5-syllable bucket with at least two tweets that end in distinct words (we group all posts that end in the same word together so we don’t accidentally try to rhyme a word with itself), and, similarly, one 8-syllable bucket containing at least 3 tweets. These tweets are then posted in limerick order and deleted from the word list.
Some other interesting problems included working with decimal numbers and unicode. I wanted “#YOLO #420” to both have the correct number of syllables and rhyme with “twenty” (“scenty”?), but the CMU rhyming dictionary doesn’t translate straight numbers. My solution was to replace every instance of a decimal number with a handcrafted verbal representation when finding rhymes. It’s a little hacky, but it does the job.
Posting Tweets
LimerickTweets posts its limericks by retweeting the original author of the tweet in the order of the limerick. This is done both to add some legitimacy to the tweets — it’s proof I’m not making them up — and to make the bot engage with the world around it. By retweeting the original poster, it creates a dialogue with them and their friends, inviting the user to see what their words have become a part of. In order to comply with Twitter logistics, each tweet is used only once. The program scrapes for new tweets just before it posts.
Since it is frequently checking for new tweets that match a certain pattern, you might call this a “watcher” bot using Michael Cook’s nomenclature. It is only generative insofar as it’s given content.
Results
The bot has been active for about a week now, and has tweeted about 100 retweet limericks. It maintains about six followers (usually from among those whose posts were retweeted), some of whom engage with the limericks by retweeting their favorites. One woman began replying with names for the limericks, and sending words of comfort to posters who were complaining about their lives. I’ll be interested in seeing how the world reacts with time and visibility.
The results themselves are spectacular, in my humble opinion. They rhyme well, the poetry they create is culturally rich and meaningful, and it even has managed to capture some of the trending topics (as it turns out, a lot of things rhyme with “dress”, “blue”, “black” and “gold”). While not the most novel thing in the entire world, I think LimerickTweets contributes a stylized spotlight to posters and uses their sentiments to craft novel, reactive art.
Some Additional Thoughts
A week or so back, I mentioned this assignment to one of my directing professors, who is largely unfamiliar with tech and computation. He was exceptionally confused by the notion of data scraping, and was left without a lot of words when I asked what he might do with a bot and a large repo of tweets to generate culture. He thought about it for a while before saying “the thing you have to remember is that, what makes drama unique is its intimacy. Many art forms like to generalize, to give some abstract overview of the human condition. Drama tries to take one small instance of the human condition, and bring its audience in very intimate contact with it. If you want your work to be dramatic, you should keep this in mind.”
It’s valid for a bot or an app to take in thousands of lines of data and condense it into something a person can visualize and understand. I feel like this is generally what we think of when we think of this sort of data processing. But perhaps an app influenced by the realm of theatre isn’t going to do this. Instead, it’s the job of the theatre to highlight single people and their plights in a stylized way that allows us to understand them differently, if not better. Perhaps it is more “dramatic” for an app to showcase individual tweets in an artistic framework than to try and make a statement about the thousands of tweets it searched through to find them. I’m interested in further exploring this notion of maintaining intimacy alongside large datasets.
The Other Bot
Since I felt like perhaps this bot wasn’t the most interesting and original thing on earth, I decided to make another one. However, I’ve yet to set up a twitter account for this one. Each account needs a separate phone number in order to access the API? How is that supposed to scale?
This second “bot” instead lives on YouTube, and its purpose is to upload generative montages. It scrapes random vine videos from Twitter, stitches them together with slow fades, and adds slow motion and a dramatic soundtrack before posting the result to YouTube. It does this by making heavy, abusive use of the Python subprocess library and the ffmpeg on the machine.
Running out of my monthly Temboo limit, I didn’t end up posting a large number of videos. But you can see them on the YouTube channel I made for my infovis project: