I came up with a new idea for my InfoVis project, unrelated to my previous idea.
This idea is to create a form of Twitter-Scrabble. The way the data is collected is as follows: 1. Start with a random Tweet. Choose a random word in that Tweet and find another random Tweet with that word in it. Continue this process until a large amount of Tweets have been gathered.
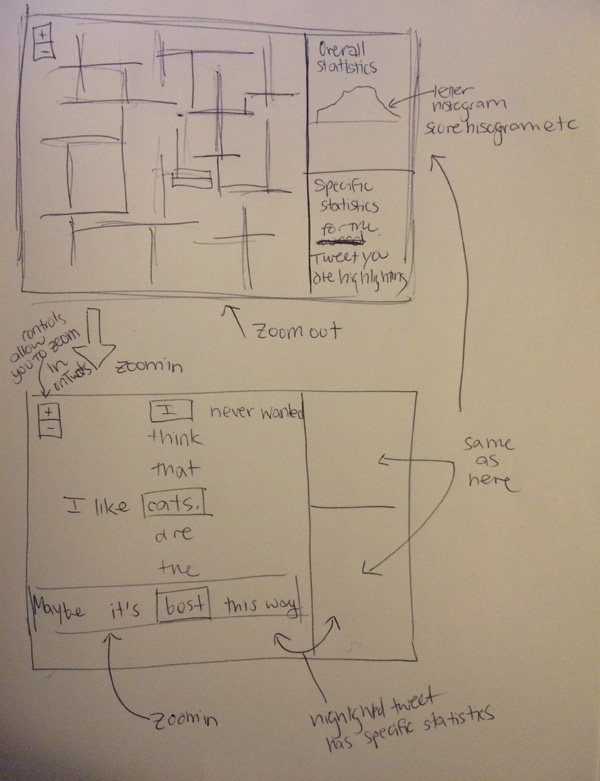
The visualization will be arranged in a somewhat Scrabble-like nature, wherein Tweets which share a word will be arranged perpendicularly so that they cross where the shared word occurs. You will be able to zoom very far out so that the Tweets are abstracted beyond recognition into criss-crosssing patterns, and also be able to zoom in close enough to read each individual Tweet. In addition, each Tweet will have a calculated “Scrabble score” using the scores that each letter receives in a traditional game of Scrabble. Additionally, there will be a side panel which will show overall statistics about the board (such as the distribution of scores, etc.)
The reason I decided to connect Twitter to Scrabble was because of the nature of Twitter posts as being only 150 characters long. The idea of people having to cram everything they might want to say into such a small space is a curious and interesting phenomenon. Tweets are already by their nature quantifying words and condensing the meaning of those words. I wanted to further quantify these already quantified entities and further abstract away from their original meaning by assigning Scrabble scores to them, treating them as scores and game pieces rather than content.
A basic sketch of how the visualization might look is below:
I was also debating whether or not I should create some sort of Bot which will Tweet the people it gets the Tweets from with the Scrabble score it assigned to their Tweet.