joxin-speech
Podcast & Active Listening
(You may play with the prototype here)

Inspirations
From my past experiences interviewing people, I realized that active listening is a central part of any conversations. When someone is telling a story, we nod, acknowledge, and respond. These reactions indicate we are listening and encourage them to say more. Giving responses make me feel more focused and more involved. It helps me develop a relationship with the person telling their story, and enjoy it in a deeper way.
I decided to integrate active listening into podcasts. Right now, when we listen to podcasts, we don’t need to react at all. But what if we have to be more active in order for the story to go on? Would the user feel like they are playing a part in the conversation? Would they feel as if they are the interviewers?
Design Process
Last October, I listened to an episode of The New York Times Daily, which talked about the story of Shannon Mulcahy, who lost her job at an Indiana steel plant because it got moved to Mexico. The story was moving in many different ways, so I decided to use it for my interactive prototype.
I listened to the podcast a bunch of times, and scripted the outline on paper.
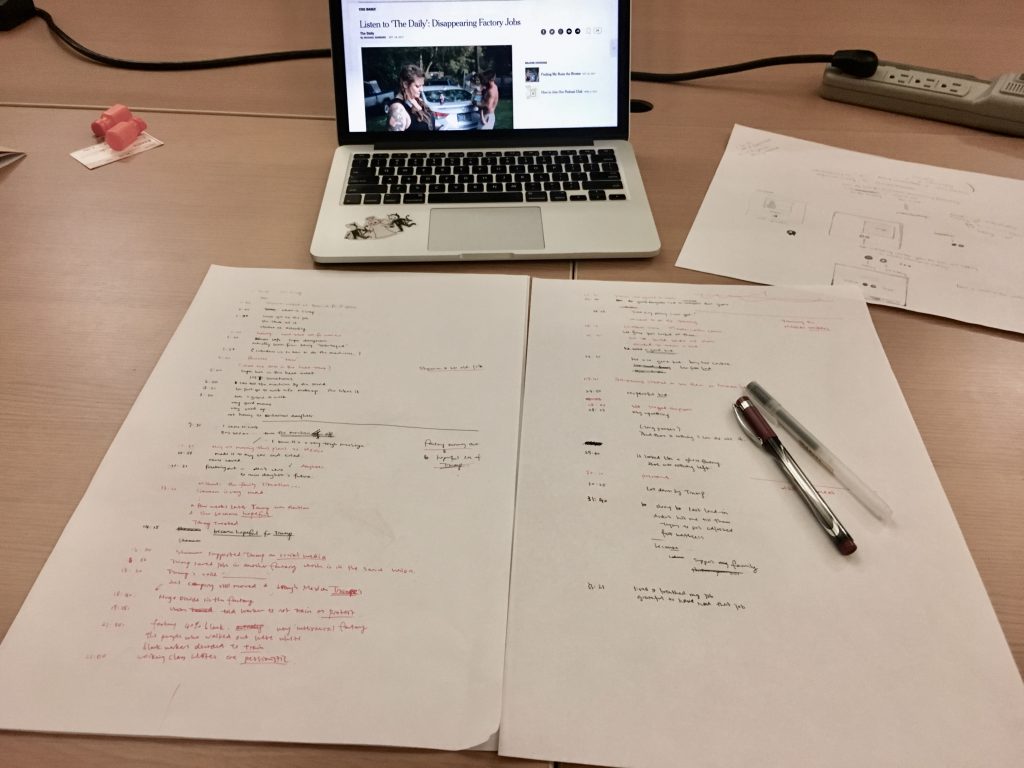
I sliced the whole podcast into clips on Audacity. Then, I loaded the clips into a p5.js sketch.
You may interact with it like this:
The story unfolds as the audio plays clip by clip. For the audio to keep playing, you have to say things like “go on,” “please continue,” or “okay,” to show that you are actively listening.
The upper circle indicates the audio clips playing, and the lower circle indicates you speaking. They symbolize a conversation between two parties.

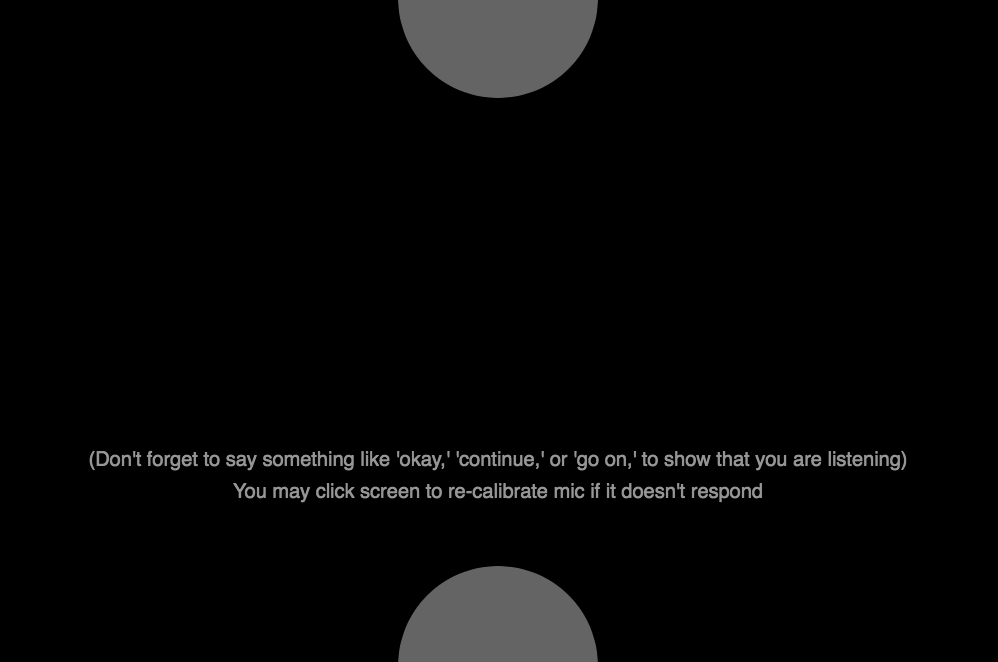
You can play with it here!
Reflection
I had fun experimenting with this new, interactive way of storytelling/story-listening, but I am not so satisfied with the visuals and the robustness of the prototype (sometimes I need to re-calibrate a lot for the computer to catch the user’s speech).
Also, at this point, whether the user is actively listening or not is checked in a very hard-coded way, but in real life, listening is not measured like that. I imagine there could be machine learning algorithms that allow me to learn the communication styles of the user and the storyteller in real time, so that I could measure their engagement and move the story forward in a more dynamic, human way.
If I could expand this app to include more podcasts, interviews, or monologues, I feel like it could provide opportunities for people to talk to their idols. For example, I just watched a Netflix documentary about an artist named Carmen Herrera. If this documentary were to be put in this form, it would allow me to “interview” Herrera virtually, and that would be really, really cool.
code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | // start up code adapted from https://www.openprocessing.org/sketch/485107 var myRec = new p5.SpeechRec(); // New P5.SpeechRec object myRec.continuous = true; // Do continuous recognition myRec.interimResults = true; // Allow partial recognition (faster, less accurate) var mostrecentword; //Variable to hold the spoken words var stringOnScreen; var acceptableWords = ["wow", "please", "all right", "continue", "good", "okay", "that's", "go on", "alright", "oh no", "I am sorry", "I'm sorry"]; var recordings; var photo; var curPlaying; var lastSpoken; var timeLimit = 5000; var mic; var button; var state; // The speech recognizer var mySpeechRecognizer; var mostRecentSpokenWord; var mostRecentConfidence; function initializeMySpeechRecognizer(){ mySpeechRecognizer = new p5.SpeechRec('en-US'); mySpeechRecognizer.continuous = true; // do continuous recognition mySpeechRecognizer.interimResults = false; // allow partial recognition mySpeechRecognizer.onResult = parseResult; // recognition callback mySpeechRecognizer.start(); // start engine console.log(mySpeechRecognizer); } function preload() { recordings = []; for (var i = 0; i < 49; i++) { recordings[i] = loadSound(i.toString()+'.mp3');; } photo = loadImage("shannonphoto.jpg"); } function setup() { createCanvas(windowWidth, windowHeight); frameRate(10); myRec.start(); //Start speech recognition stringOnScreen = "ready!"; smooth(); mic = new p5.AudioIn(); mic.start(); lastSpoken = millis(); button = createButton(' |
Go to NYT Daily Podcast
‘); button.position(windowWidth-170,height-50); button.mousePressed(webpage); textAlign(CENTER); ellipseMode(CENTER); state = 0; initializeMySpeechRecognizer(); } function webpage() { link(“https://www.nytimes.com/2017/10/18/podcasts/the-daily/factory-jobs.html”); } function link(href, target) { if (target !== null) window.open(href, target); else window.location = href; }; function draw() { if (state == 0) { background(0); fill(255); imageMode(CENTER); image(photo, width/2, height/2-60, photo.width/2, photo.height/2); textSize(12); text(“Click on Screen to listen to Shannon Mulcahy tell her story”, width/2, height/2+128); text(“Please respond intermittently to show that you are listening, as if you are an interviewer yourself”, width/2, height/2+150); textSize(10); fill(100); text(“Adapted from the Oct. 18, 2017 episode of The New York Times Daily Podcast”, width/2, height/2+200); noStroke(); fill(100); ellipse(width/2, 0, 100, 100); ellipse(width/2, height, 100, 100); } else { background(0); voiceInput(); audioOutput(); if (!recordings[curPlaying].isPlaying() && curPlaying < 5) { if (Math.sqrt(Math.pow(mouseX – width/2, 2) + Math.pow(mouseX – height, 2))) { fill(150); text(“(Don\’t forget to say something like ‘okay,’ ‘continue,’ or ‘go on,’ to show that you are listening)”, width/2, height-100); text(“You may click screen to re-calibrate mic if it doesn’t respond”, width/2, height-84); } } } } function parseResult() { mostRecentConfidence = mySpeechRecognizer.resultConfidence; if (mostRecentConfidence > 0.3){ var curString = mySpeechRecognizer.resultString; print(curString); for (var i = 0; i < acceptableWords.length; i++) { if (curString.includes(acceptableWords[i])) { lastSpoken = millis(); } } mostRecentSpokenWord = mySpeechRecognizer.resultString.split(‘ ‘).pop(); bFoundRhymeWithMostRecentWord = false; } } function voiceInput() { micLevel = mic.getLevel(); noStroke(); var size = map(micLevel, 0, 1, 120, 400); if (recordings[curPlaying].isPlaying()) { fill(100); ellipse(width/2, height, size, size); fill(255); ellipse(width/2, height, 100, 100); } else { fill(100); ellipse(width/2, height, 100, 100); } } function audioOutput() { amplitude.setInput(recordings[curPlaying]); var audioLevel = amplitude.getLevel(); var size = map(audioLevel, 0, 1, 120, 400); if (recordings[curPlaying].isPlaying()) { fill(100); ellipse(width/2, 0, size, size); fill(255); noStroke(); ellipse(width/2, 0, 100, 100); } else { if (millis() – lastSpoken < timeLimit && curPlaying < 48) { curPlaying += 1; recordings[curPlaying].play(); } fill(100); noStroke(); ellipse(width/2, 0, 100, 100); } } function mousePressed() { if (state == 0) { state += 1; curPlaying = 0; amplitude = new p5.Amplitude(); recordings[curPlaying].play(); } else { initializeMySpeechRecognizer(); } }