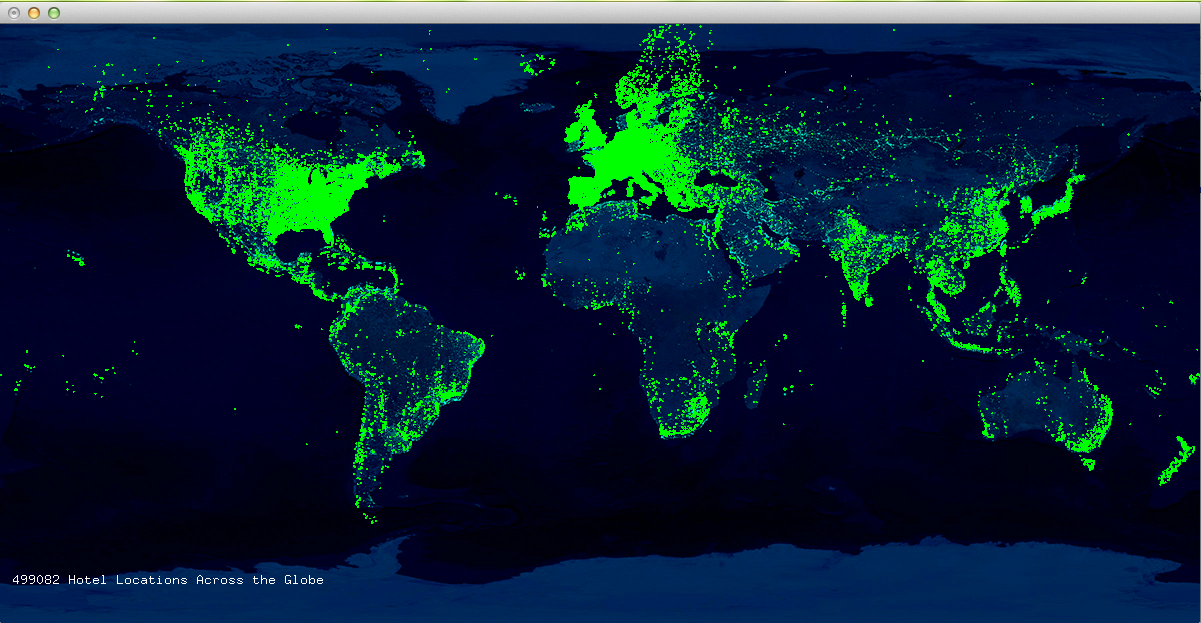
Given the database of all hotels in the world, I decided to run a TFIDF (Term Frequency Inverse Document Frequency) algorithm upon the hotel names, dividing the hotels up by countries, treating the countries like documents. In other words, given any country in the world (ie Germany), I can return a list of the most German ways to name a hotel, by comparing all the ways Germans name hotels to the entire corpus of countries, on a term by term basis.
The two addons I used were ofxCsv and ofxUI. I compiled the two of them together, but didn’t really end up utilizing ofxUI for anything practically speaking, due to the minimalist aesthetic I decided to go for, creating my own scrollbar rather than one from ofxUI.
The final interaction allows you to scroll through a text list of all of the countries in alphabetical order, alongside a few terms that are how those countries distinctly name hotels. Unfortunately, the algorithm I’ve written for the TFIDF is extremely granular, much moreso than what would realistically be required for an accurate data visualization. For this reason, my program has been running for a couple of hours and I’ll sleep on it and hopefully the numbers will have crunched fully. After the numbers of crunched, the program should export the data as a csv so that next time I open it up it should just load in the data and you can interact with it right away.
[UPDATE] After realizing my algorithm wasn’t optimized after running for 48 hours, I updated the code (from a horrendous O(n^3) to a manageable O(n^2)) and within a couple of hours, the algorithm finished. In a lot of ways, the results weren’t totally surprising. What I noticed were a few (unsurprising) trends: smaller countries tended to have their largest cities as disproportionately popular terms; countries tended to be divided among language lines; the term “Hotel” occurred much more often than I had expected considering the TFIDF process. What I suspect is that many smaller countries tended to use the term “Hotel,” while larger countries did not. For this reason, it could still be considered a disproportionately large portion of the entire corpus of appearances for those small countries.
Next steps? I’m very pleased with the general outcome of this project. My TFIDF is functional and fairly optimized. I plan to thread it as to increase speed up further. Top results also included the term “&” and a few other things I had to clean up in post, so I now know how to preprocess some of the data to ensure my results are better next time I use it.
I plan to use this algorithm for my data-selfie assignment, in which I will be using the entire corpus of my Facebook and text messaging, and very the inputs slightly to get a wide range of results (comparing how I talk to each user, comparing how I talked to a given user over time, using n-grams rather than individual terms, comparing how I talk to men vs women, comparing how women talk to me vs how men talk to me, etc.).