Nngdon-Last Project
The PDF version is available here: FaunaOfSloogiaII.pdf
For my last project I decided to expand on my generative book, which is about imaginary creatures on an imaginary island. The last version had only generated illustrations of the creatures, so I felt that I could supplement the concept of “fauna of an island” by giving each creature a short description, some maps indicating the habitats of them, and some rendered pictures of the animals with a natural background (trees, rivers, mountains, etc.).
The Map
I first generated a height maps using 2D Perlin noise. This results in an even spread of lands and waters across the canvas. To make the terrain more island-ish, I used a vignette mask to darken (subtract value from) the corners before rendering the noise.
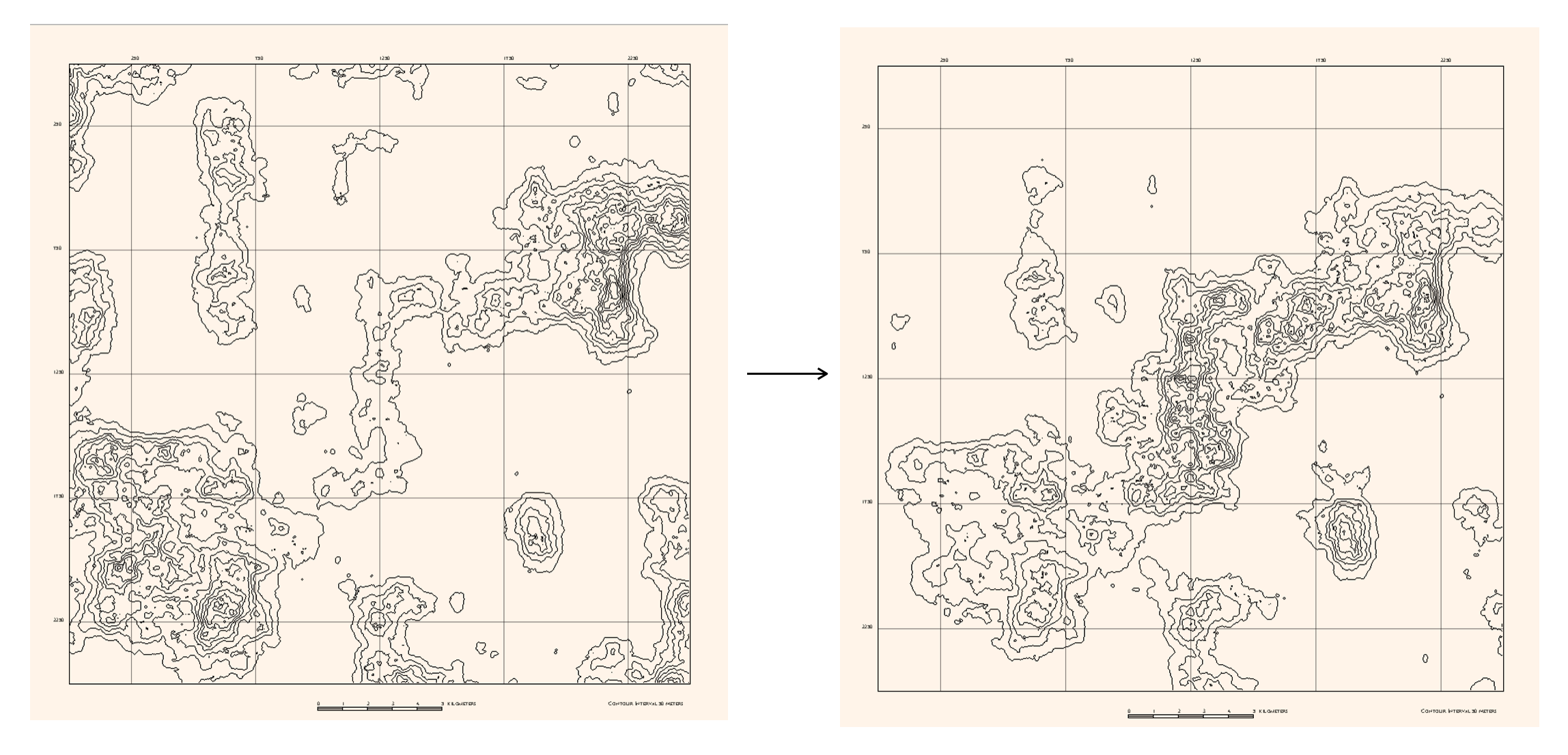
After this an edge finding algorithm was used to draw the isolines.
Labeling
The next task is to label the map: to find where the mountains and seas are and name them accordingly.
I wrote my own “blob detection” algorithm inspired by flood fill. First, given a point, the program will try to draw the largest possible circle, given the rule that all pixels in that circle have to be within a certain range of height. Then, around the circumference of the circle, the program tries to generate even more such circles. This is done recursively, until no more circles larger than a certain small radius can be drawn. The union of all the circles is returned.
Using Mitchell’s best-candidate algorithm, I picked random points evenly spread across the map, and apply my blob detection. Blobs that are very close to each other or have a lot of overlapping are merged.
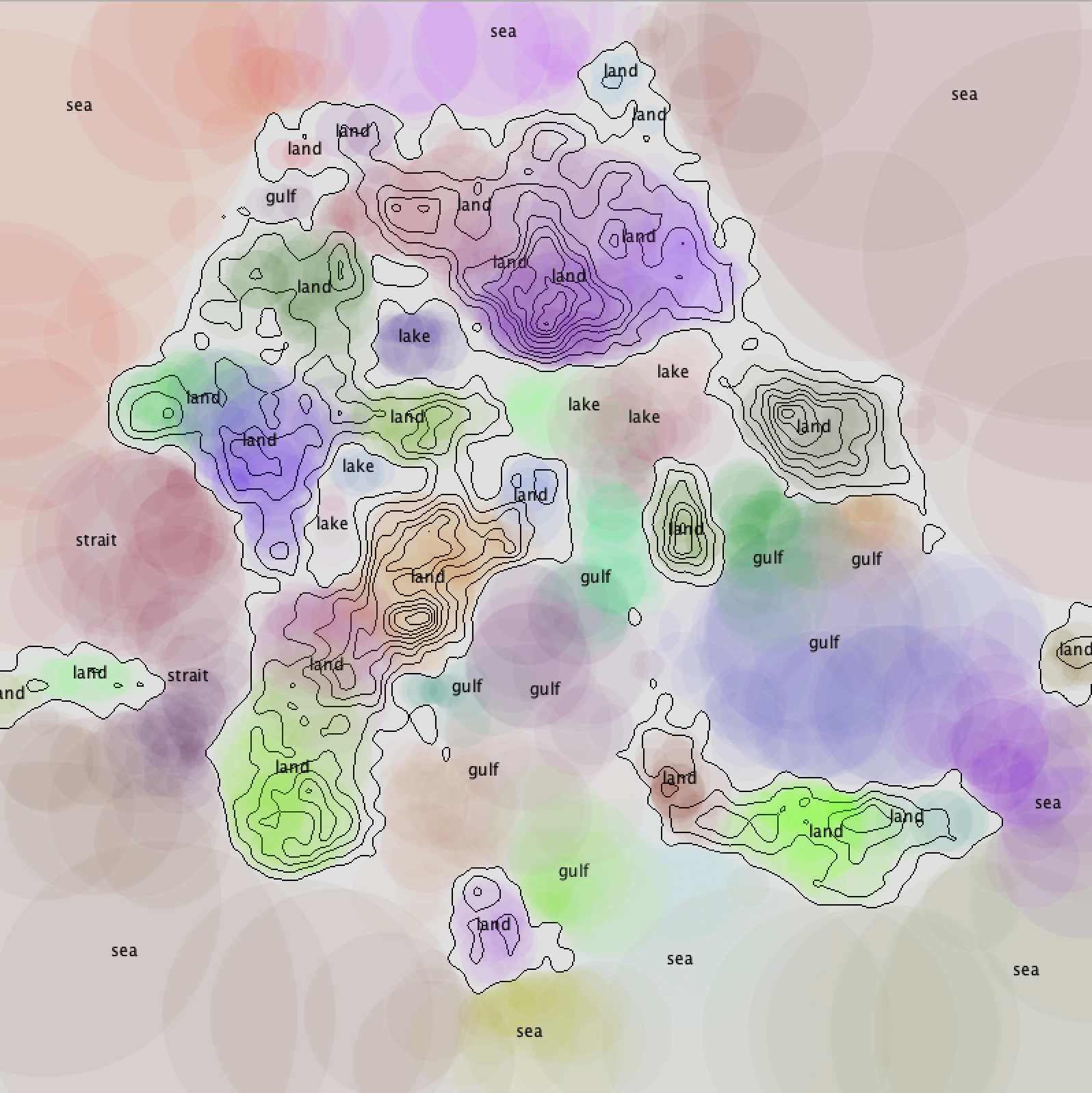
Then for each blob that indicates a water area, the program checks how surrounded by land it is, and decide whether it is a lake, strait, a gulf, or a sea. For the land areas, the program decides the terrain according to its height and whether it is connected to another piece of land.
A Markov chain is used to generate the names for the places. The text is rotated and scaled according to the general shape of the area.
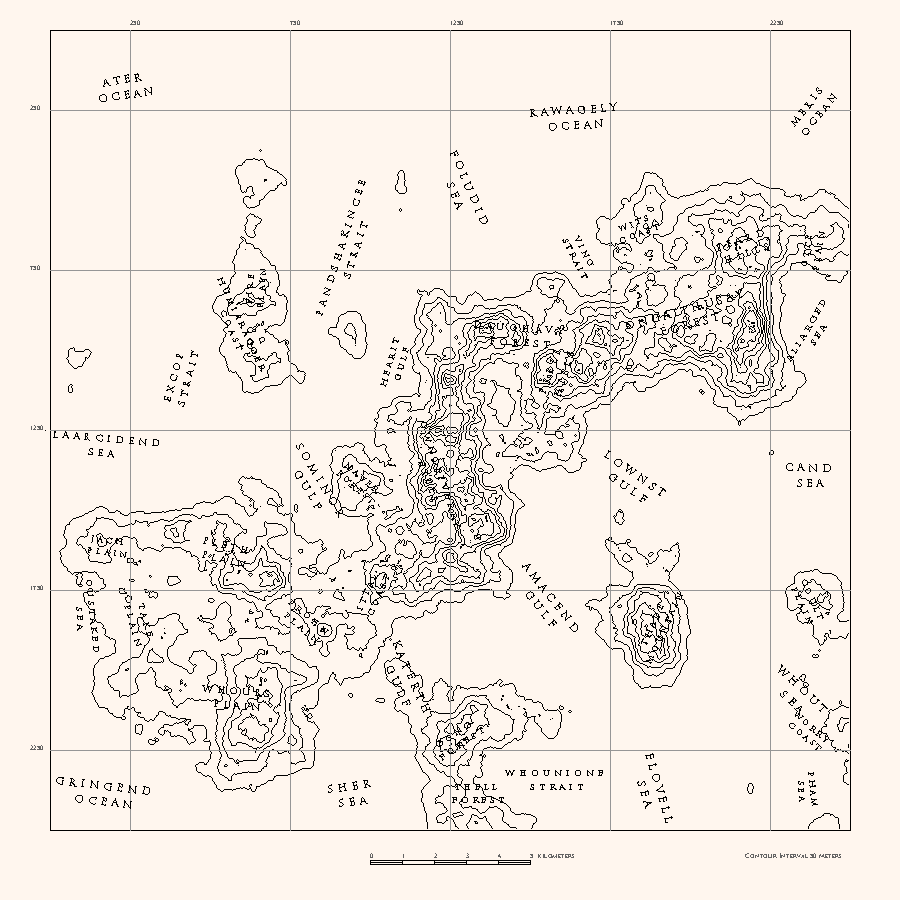
Finally, the program exports a JSON file, saving the seed and the names, areas and locations of the places, to be used in the next step.
The Description
The description costed me the most time in this project. I spent a long time thinking about ways of generating high-quality generative text.
I noticed that there are usually three major ways of making generative text people are using:
- Markov chain/ machine learning method. The result has good variety, and is easy to implement, as the computer does the most part for you. However the programmer has the least control over what the program is generating, and nonsensical sentences often occur.
- Word substitution. The human writer writes the whole paragraph, and some words in the paragraph are substituted by words chosen randomly from a bank. This method is good for generating only one or two pieces of output, and soon gets very repetitive after a few iterations. A very boring algorithm.
- A set of pre-defined grammar + word substitution.
The third direction seems to be able to combine order and randomness well. However as I explored deeper I discovered that it’s like teaching the computer English from scratch, and massive amount of work is probably involved to make it generating something meaningful, instead of something like:
Nosier clarinet tweezes beacuse 77 carnauba sportily misteaches.
However I was in fact able to invent a versatile regex-like syntax that makes defining a large set of grammar rather easy. I believe it’s going to be a very promising algorithm, and I’m probably going to work on it later. As for this project, I tried to look into the other two algorithms.
Grab data, tokenize and scramble
Finally after some thought, I decided to combine the the first and the second method.
First I wrote a program to steal all the articles from the internet. The program pretends to be an innocent web browser and searches sites such as wikipedia using a long list of keywords. It retrieves the source code of the pages, and parses it to get the clean, plain text version of the articles.
Then I collected a database of animal names, place names, color names etc., and searched within the articles to substitute the keywords with special tokens (such as “$q$” for the name of the query animal, “$a$” for name of other animals, “$p$” for places, “$c$” for colors, etc.)
I developed various techniques, such as score-based word similarity comparison to avoid missing any keywords. For example, an article about the grey wolf may mention “gray wolf”, “grey wolves”,”the wolf”, “wolves” referring to the same thing.
After this, a scrambling algorithm such as Markov chain is used. Notice that since the keywords are tokenized before scrambling, the generator can slide easily from one phrase to another across different articles. This gives the result interesting variety.
LSTR and charRNN
Golan pointed me to the neural networks LSTR and charRNN as alternatives to Markov chain. It was very interesting to explore them and watch as the computer learns to speak English. However they still tend to generate gibberish after training overnight. There seems to be an asymptote to the loss function: the computer is becoming better and better, but then it reaches a bottleneck, and starts to confuse itself and slips back.
Another phenomenon I observed is that the computer seems to be falling in love with a certain word, and just keeps saying it whenever it’s possible. At the worst outburst of this symptom the computer falls into a madness like:
Calf where be will calf will calf that calf will calf different calf calf calf the and calf a calf only calf a other calf calf calf calf…
And oftentimes it does not know when to end its sentences, and keeps running on.
The problem with neural networks is that it’s like a magic black box. When it works it’s magical, but when it doesn’t you don’t know where to fix. As I’m not too familiar with the details of neural networks and was entirely using other people’s libraries, I have no idea how to improve the algorithm.
Generation
I wrote my own very portable version of Markov chain in 20 lines of python code, and it seems to be working better than the neural networks.(?)
My favorite lines are:
The $q$ can take a grave dislike towards their tail, which are the primary source of prey.
A female $q$ gives birth to one another through touch, movement and sound.
The infant $q$ remains with its mother until it was strong enough to overpower it and kill it.
And paradoxical ones such as:
…the tail which is twice as often as long as two million individuals.
Finally the tokens are substituted by relevant information about the animal described. These information are stored in JSON files when the illustrations and maps are generated.
The names of all the 50 animals and places are stored in a pool, so descriptions of different animals can refer to each other. For example, in the description of animal A, it says its predator is animal B. After flipping a few pages, the reader will be able to find a detailed account of animal B, and so on.


Eyes Improvement
Golan told me that my creatures eyes look dead and need to be fixed. I added in some highlights so they look more lively now (hopefully).

Code
The complete code will be available on Github once I finalize the project. Currently I’m working on rendering the animals against a natural background.
But here’s my 20-line Markov chain in python.
import random
class Markov20():
def __init__(self,corp,delim=" ",punc=[".",",",";","?","!",'"']):
self.corp = corp
self.punc = punc
self.delim = delim
for p in self.punc: self.corp = self.corp.replace(p,delim+p)
self.corp = self.corp.split(delim)
def predict(self,wl):
return random.choice([self.corp[i+len(wl)] for i in range(0,len(self.corp)-len(wl)) if self.corp[i:i+len(wl)] == wl ])
def sentence(self,w,d,l=0):
res = w + self.delim
i = 0
while (l != 0 and i < l) or (l==0 and w != self.punc[0]):
w = self.predict(res.split(self.delim)[-1-d:-1])
res += w + self.delim
i+=1
for p in self.punc: res = res.replace(self.delim+p,p)
return res
def randsentstart(self):
return random.choice(self.delim.join(self.corp).split(self.punc[0]+self.delim)).split(self.delim)[0]
if __name__ == "__main__":
f1 = open("nietzsche.txt") #s3.amazonaws.com/text-datasets/nietzsche.txt
corp = (f1.read()).replace(" ","").replace("\n"," ").replace("\r\n"," ").replace("\r"," ").replace("=","")
m20 = Markov20(corp)
for i in range(0,3):
print m20.sentence(m20.randsentstart(),2)